Claude Managed Agents can operate in a sandbox you control, on your own infrastructure or with any provider you choose.
Today we added new guides for @blaxelAI, @e2b, @googlecloud, @namespacelabs, and @superserve_ai, so you can choose the best fit for your use case.
Wow, this is interesting..
@Stanford researchers put a common assumption to the test: large models need only “high-quality” filtered training data.
What if the best filter is no filter at all?
They compared full Common Crawl data with heavily filtered versions of it and got surprising results:
1. Filtering can help with small compute budgets, because models can't learn from everything well.
2. However, as models get larger and train longer, the full, unfiltered dataset becomes the winner.
Large models handle messy data better than expected – low-quality text, irrelevant text, or some “junk” data are not a big deal; these models can tolerate them.
And they can even extract useful signal from data that looks poor.
These facts transform general rules:
→ Filtering helps when compute is limited. But when compute is very large, removing too much data may throw away useful information.
This also connects with the concept of "bitter lesson": at large scale, simple scaling often beats clever human design.
But the final choice depends on your constraints and preferences – would you rather increase compute costs or put more resources and time into filtering?
Interesting to see your answers 👀
What can a neuron compute?
Real biological neurons are complex, but how capable are they?
Using a new method, we found that a single cortical neuron can classify cats vs dogs, recognize spoken words, and solve 10-bit parity, all tasks thought to require entire networks. (1/15)
Introducing our first technical blog post:
Automatic Dense Rewards for Autonomous Robot Learning
In this post, we utilize VLM chunking techniques to densely reward trajectories based on video and telemetry data without human supervision.
LocateAnything is a new vision-language grounding model from @NVIDIAAI
performs diverse localization tasks like dense object detection, GUI element finding, OCR, document layout, and referring expression comprehension
NVIDIA is demoing it at CVPR today
Second big release from us today: Nemotron-3.5-ASR-Streaming!
🌎40 languages
⚡️80ms - 1s controllable latency
🔥240 - 2400 concurrent streams on 1xH100
🧱FastConformer Cache-Aware RNN-T architecture
https://t.co/lxmcAnKeOl
MOSS-TTS v1.5 is here, an upgrade to v1.0 from @OpenMOSS. (demo👇)🤖https://t.co/n0muiRJ2wA
Key improvements:
⏸️ Inline pause control: [pause 3.2s] now supported mid-sentence
🌍 31 languages, up from 20 — now includes Cantonese, Hindi, Thai, Vietnamese, Tagalog, Swahili and more
🎙️ More stable voice cloning with reduced variance across repeated generations
📝 Better long-reference, short-text cloning All v1.0 capabilities preserved: zero-shot cloning, long-form speech, Pinyin/IPA control, code-switching.
💻 https://t.co/j1kyeIiPnk
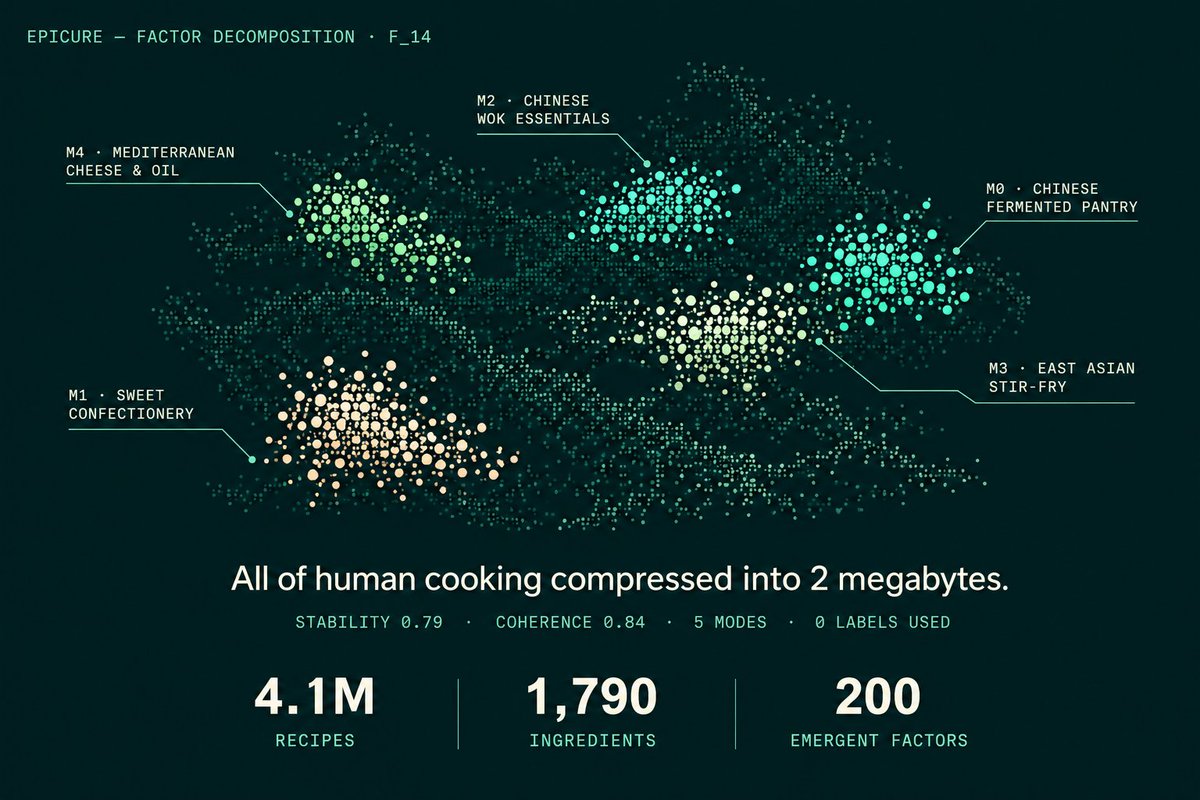
Launching our new paper on arXiv: we trained the largest multilingual food model ever built.
4.1M recipes. 7 languages. 1,790 ingredients. 300 dimensions.
All of human cooking compressed into 2 megabytes.
With my own Agent, I got a PaddlePaddle + TensorRT inference solution on RTX 5070 that had been delayed by about 2 months. With the help of the Agent, it was resolved in 30 minutes, including fixing a split op compatibility issue.
AutoResearchClaw: Chat an idea, get a paper.
A 23-stage autonomous research pipeline with multi-agent debate and self-healing experiments.
It features human-in-the-loop collaboration across 7 intervention modes.
Outperforms AI Scientist v2 by 54.7% on ARC-Bench.
Seedance has a hidden feature that feels illegal.
It lets you create old-school anime at lightning speed.
It’s called “in-between” - and it actually delivers.
Try it yourself 👇
it's open source time, with a real leap for world models 🎉
NVIDIA's SANA-WM: a camera-conditioned world model that fits on one GPU. 60s of 720p in 34s on a single 5090 - 2.6B params and Apache 2.0!
https://t.co/Vptws3HDwa
Woow Nvidia has just released a 2.6B open-source world model 🔥
You can turn a single image, text prompt and trajectory into controllable worlds...
And on a single GPU!
- Code available on GitHub
- Paper as well on arxiv
You can use it for many things like embodied AI and robotics research, simulations, etc.
Because it can run on a single GPU (like an RTX 5090 or H100) it makes world models accessible to basically everyone!
New Google paper: A forecast needs context, not just history.
Some patterns are caused by events, not time. Nexus reframes forecasting as a reasoning problem, where events and numbers have to explain each other.
Nexus argues that forecasting improves when models read the world around the numbers, not just the numbers themselves.
In the Zillow tests, one Claude-based version cut average MAPE by 86.6% versus direct chain-of-thought prompting.
That matters because most time series models are fluent in pattern, but mute about cause.
A housing inventory curve can reflect seasonality, mortgage pressure, migration, layoffs, and local supply, while a stock price can be bent by earnings, regulation, hype, and fear.
Nexus separates those jobs instead of asking one prompt to do everything.
One agent turns messy historical text into a clean event timeline, one reads the broad regime, another tracks local shocks, and a synthesizer reconciles them with calibration from past errors.
The interesting result is not merely that context helps, but that structure helps the language model use context without losing the time series.
The evidence is still narrow: Zillow counts, seven equities, post-cutoff data, and single-run evaluations, so this is not a universal law of forecasting.
But the direction is clear: future forecasters will not only extrapolate curves; they will argue about what made the curve move.
----
Paper Link – arxiv. org/abs/2605.14389
Paper Title: "Nexus : An Agentic Framework for Time Series Forecasting"