Introducing DiffusionBlocks: Block-wise Neural Network Training via Diffusion Interpretation
https://t.co/c9AvsRKybj
What if we didn’t have to hold an entire neural network in memory to train it?
Standard neural net training optimizes all parameters jointly. As a result, the memory required during training grows linearly with the depth of the network.
In our #ICLR2026 paper, we propose DiffusionBlocks, a principled framework to train networks one block at a time, drastically reducing memory requirements while matching end-to-end performance.
With DiffusionBlocks, we split the network into blocks and train them one at a time, so you only need memory for a single block.
How? We explicitly assign each block a role: to move the representation a little closer to the target than the block before it did. That role turns out to be precisely what a diffusion model does, step by step. Each block only needs to optimize its own objective and can be trained independently.
We validated this across five different architectures:
• ViT
• DiT
• Masked diffusion
• Autoregressive transformers
• Recurrent-depth transformers
In each case, performance is competitive with end-to-end training while using a fraction of the memory.
This perspective also extends naturally to recurrent-depth (Looped) transformers, which apply the same network iteratively and normally require expensive backpropagation through time (BPTT). Viewed through DiffusionBlocks, we can replace those multiple iterations with a single forward pass during training.
Read our paper and code, to learn more.
Paper: https://t.co/CRj96VGYQn
GitHub: https://t.co/eNW0K9Xh8E
🐟
Anthropic pays $750,000+ a year for engineers who can build LLM architectures from scratch. Stanford taught the entire thing in 1 hour lecture & released it for free.
Bookmark & watch this today before someone takes it down.
"Getting the Target Right in Return Prediction": "Transforming the target from raw to standardized or rank-based returns nearly triples predictive accuracy and doubles portfolio returns [based on machine learning]." https://t.co/EBdJHkmV60
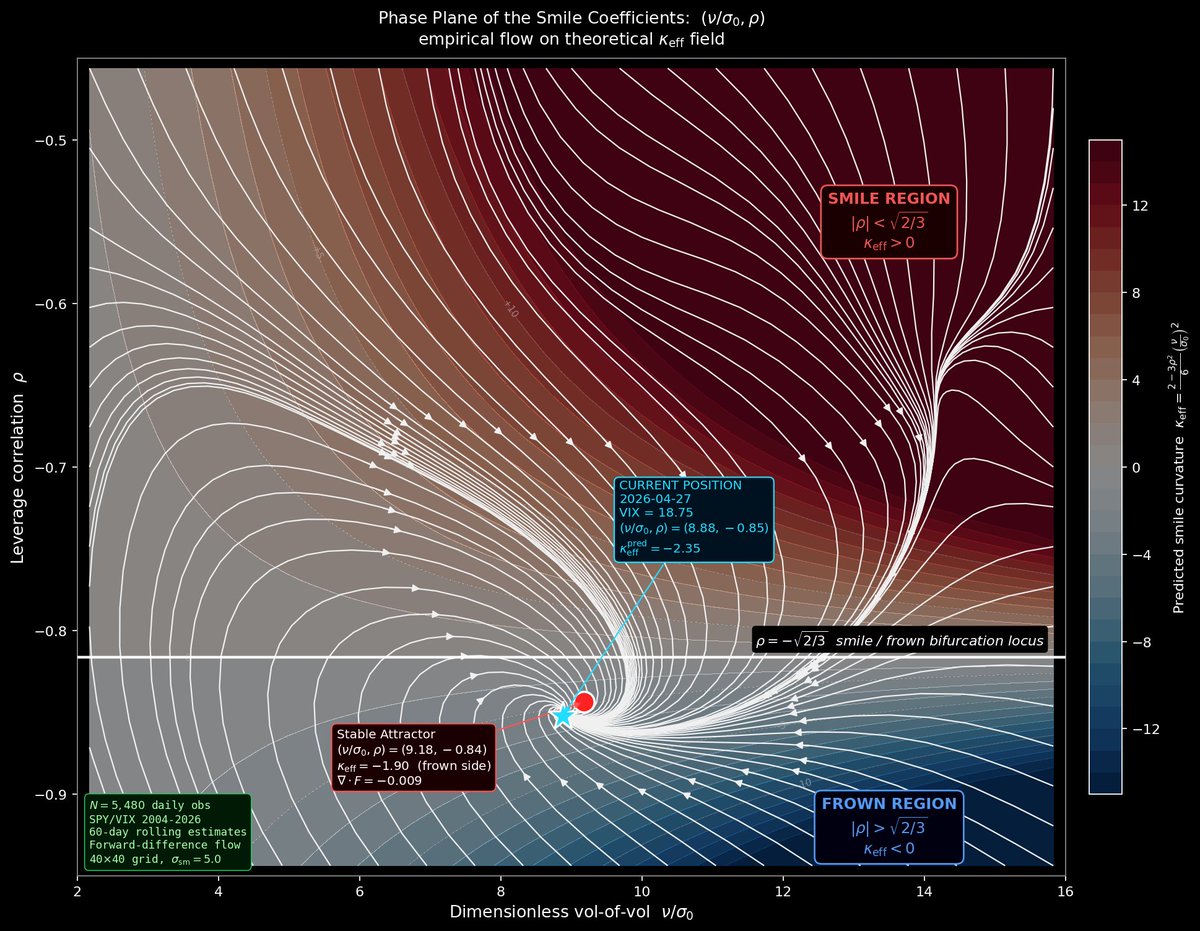
Black-Scholes is wrong almost everywhere.
And yet, it’s still the language of options markets.
The reason: It’s the flat limit of a curved geometric pricing space.
The volatility smile? That’s the curvature.
Below we see where markets actually live in that space
Preprint:
https://t.co/uD7NVupSsx
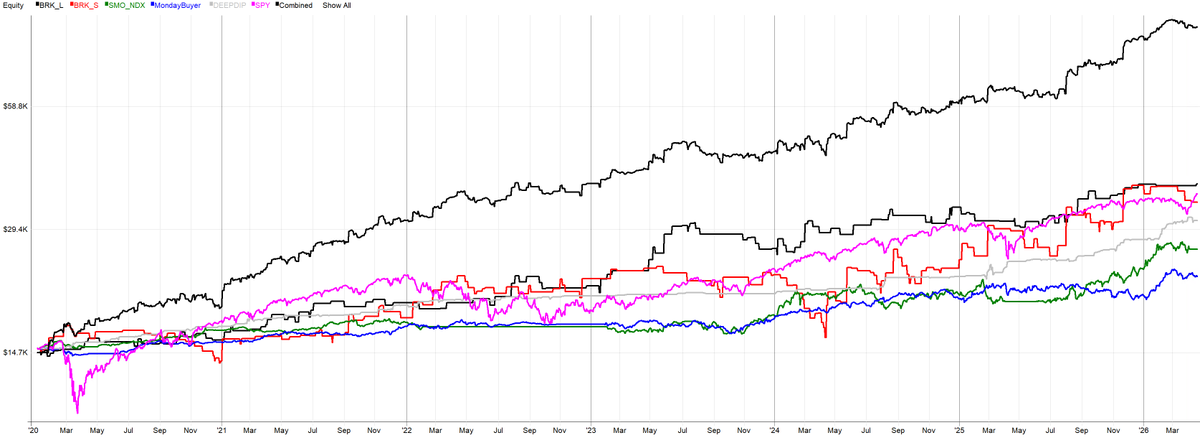
A systematic portfolio does not have to be complicated.
If I were starting from scratch, I would not begin with 25 exotic strategies and endless optimization.
I would start with a few simple, different return drivers:
- stock momentum
- slow long mean reversion on stocks
- faster long mean reversion on stocks
- simple intraday system on indices
The goal is not to find one perfect system.
The goal is to combine simple systems that behave differently, make money in different market conditions, and reduce dependence on any single edge.
This chart shows the main strategies in my own portfolio applied to a smaller account, with slippage and commissions included.
Simple ideas.
Different behavior.
One systematic portfolio.
Deep dive with detailed statistics, updated daily:
https://t.co/QqtucCENtB
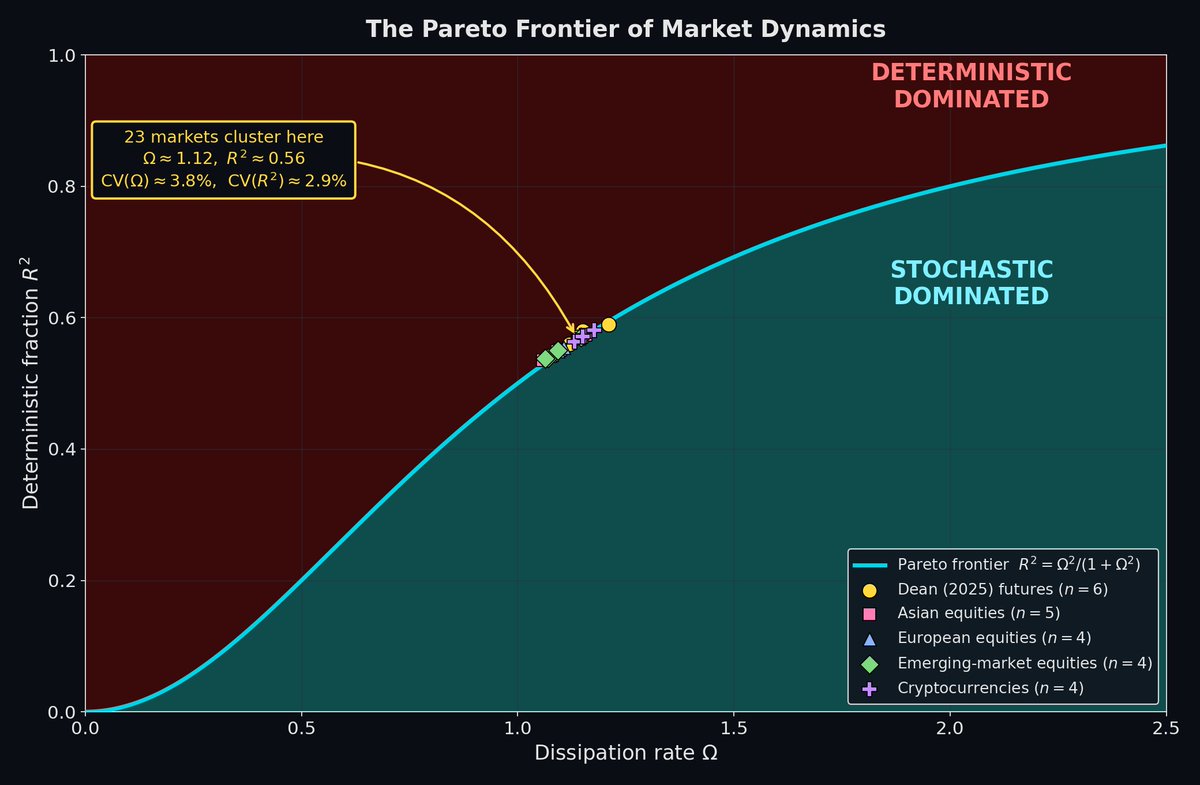
As a grad student working on Hamiltonian systems in General Relativity, I often wondered what the phase-plane approach from dynamical systems theory could tell us about markets.
Today I submitted the third paper in that answer:
Information Geometry of Market Dynamics: A Pareto Frontier from Contact Geometry.
Preprint: https://t.co/NXpR7VxFlw
and code:
Zenodo: https://t.co/uppcCQwoo1
Solid mathematical ideas almost always outperform contrived engineering tricks.
For years deep learning has been dominated by increasingly complex architectural hacks: CNN blocks, attention layers, channel mixers, residual pathways, normalization stacks.
Every few years a new architecture is announced as if it were a revolution.
One of the most famous examples was Kaiming He and Residual Networks (ResNet). At the time he was paraded around the AI world like a celebrity because residual connections supposedly “solved” deep learning.
But these were largely engineering patches.
Now something much more interesting appeared.
A new architecture called CliffordNet returns to mathematics — specifically Clifford Algebra, developed in the 19th century by William Kingdon Clifford.
Instead of stacking arbitrary modules, the model is built around the geometric product
uv = u·v + u∧v
A single algebraic operation that simultaneously captures inner product structure and geometric interactions.
In other words: the math already contains the interaction mechanism.
No attention blocks.
No mixer layers.
No architectural spaghetti.
The result:
• 77.82% accuracy on CIFAR-100 with only 1.4M parameters
• roughly 8× fewer parameters than ResNet-18
And with strict O(N) complexity.
The paper even suggests that once geometric interactions are modeled correctly, feed-forward networks become largely redundant.
A good reminder for the AI community.
Engineering tricks can dominate for years.
But eventually mathematics shows up and deletes half the architecture.
Paper:
[https://t.co/QIkCCO1tYs)
19th century geometry just walked into computer vision.
For a decade, we've made models wider and deeper—but we've barely changed how layers *talk* to each other.
Since ResNet's `x + F(x)` in 2015, the depth residual has been the only highway for inter-layer communication.
It's time to upgrade the staircase. 🧵
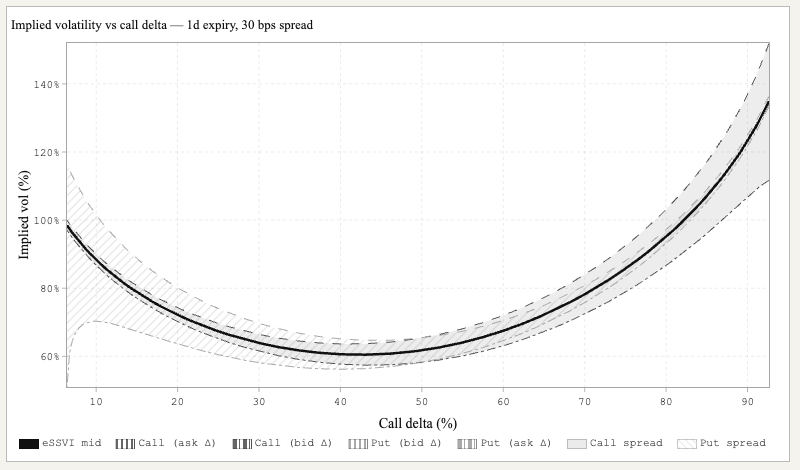
when fitting curves on short dated options, do you fit to the bid / ask respectively and then take the mid of the vols? or do you take the mid of the prices and then take the vol of that?
what if neither will give you the full picture?
a thread on fitting 0dte curves🧵
1/11
Huge! Recurrent neural networks could match Transformer memory without the quadratic burden!
Ali Behrouz from Google and colleagues have cracked it!
They present Memory Caching (MC), a simple yet powerful method that lets RNNs store "memory checkpoints" of their internal states. This allows their effective memory to grow with context, offering a flexible trade-off between speed and recall.
MC dramatically enhances recurrent models in language modeling and long-context understanding. It significantly closes the performance gap with Transformers on recall tasks and outperforms existing state-of-the-art recurrent models.
This is the EXACT 12-step methodology Institutional quant desks use to win every single trade.
Bookmark & run it through your stack or just pass it directly to your AI coding agent. Most people never reach this layer in their entire lifetime.
Full breakdown in article below.
@plus_vision_div I noticed you also make whiteboards, so I wanted to ask—do you have any plans to bring this magnetic writing technology to whiteboards in the future? I think it could solve common issues like dried-out markers and stains from unwiped ink, while also being more eco-friendly.
Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: https://t.co/CDSQ8HpZoc



























![macro_synergy's tweet photo. "Getting the Target Right in Return Prediction": "Transforming the target from raw to standardized or rank-based returns nearly triples predictive accuracy and doubles portfolio returns [based on machine learning]." https://t.co/EBdJHkmV60 https://t.co/BUF8LiAh05](https://pbs.twimg.com/media/HHIl5UoWQAA4uKJ.jpg)