Today we introduce a new vectorized dataset for mapping fine-scale ecological features, such as hedgerows, that often go undetected by standard satellites. This precision provides a new roadmap for addressing climate & biodiversity challenges without compromising food security. More: https://t.co/NRU3hrqvrd
Another cool stuff from NVIDIA.
LocateAnything - high-speed visual search engine. You provide a text prompt and it instantly pinpoints that object's exact location in an image.
- 10x speedup for dense object detection
- Qwen2.5-3B + Moon-ViT
- Fast/Slow/Hybrid modes
- trained on 138M samples for UI, docs, generic grounding.
https://t.co/bEvD6pRKaR
My first PhD paper is out now in @Nature! Very grateful to have worked with the FutureHouse team on this, and a big shoutout to my co-first author @agreeb66 😀
Esto es, realmente, un DELIRIO.
Agarraron 2.245 currículums reales escritos por humanos y le pidieron a ChatGPT, DeepSeek y otros modelos que los reescriban. Mismo curriculum, experiencia, estudios... todo igual, solo que reescrito.
Después, le mostraron pares al azar a cada IA y le pidieron que eligiera el mejor: el suyo contra el del humano. Todos se eligieron a sí mismos más del 95% de las veces. Incluso después de controlar por calidad (asegurándose de que el CV humano no fuera objetivamente peor) seguían eligiendo el suyo.
Después, simularon procesos reales de selección en 24 industrias y descubrieron que, si usaste el mismo modelo que el reclutador, tenés entre 23% y 60% más chances de pasar el primer filtro.
¿Por qué pasa esto? Los autores tienen una hipótesis fuerte: cuando le pedís a un modelo que te mejore el CV, te lo reescribe con su huella estilística: sus palabras favoritas, su ritmo, su forma de armar oraciones... Cada IA tiene un estilo propio, como cada escritor tiene una letra. Después, cuando esa misma IA evalúa, se reconoce del otro lado y se pone un diez. Cuanto más capaz es el modelo, más afilada es su capacidad de reconocerse.
Ahora buscar laburo es como el test de Turing pero al revés: en lugar de una máquina intentando convencerte de que es humana, parece que ahora somos nosotros los que tenemos que convencer a los robots que somos uno de ellos.
Thread on a staple of modern computer vision: Masked AutoEncoder (MAE)
This 2021 FAIR paper proposes a new self-supervised technique to pretrain ViTs.
It is one of the first ViT-specific SSL technique, which showed the world the flexibility of the transformer [1/6] 🧵
Google DeepMind has made Stable Diffusion's VAE obsolete.
Right now, every major AI image generator (like Stable Diffusion) operates on a massive, hidden flaw.
They use a two-step process.
First, an encoder compresses an image into a smaller "latent" space. Then, that encoder is frozen forever.
Only after it is frozen does the actual diffusion model try to learn how to generate things from that space.
The frozen encoder doesn't know how the generator works.
This creates a brutal trade-off.
If the compression is simple, the final output is blurry and soupy. If you try to keep all the fine details, the latent space becomes a chaotic mess that the AI struggles to learn.
DeepMind has dropped a paper that completely destroys this trade-off.
They call it Unified Latents (UL).
Instead of training the encoder and the generator in isolation, DeepMind co-trained them. Together.
They replaced the old, rigid architecture with a framework where the encoder is jointly regularized by a diffusion prior and decoded by a diffusion model.
The AI now learns how to compress the data specifically so the generator can understand it perfectly. It explicitly controls the "bitrate" of its own imagination.
The results rewrite the economics of generative AI.
On massive benchmarks like ImageNet-512 and Kinetics-600, Unified Latents just set new state-of-the-art records for fidelity and video consistency.
But here is the part that should terrify the hardware monopolies.
It achieved this while requiring significantly fewer training FLOPs than existing models.
We spent the last two years thinking the only way to get perfectly coherent AI video was to burn billions of dollars on larger GPU clusters.
But the real unlock wasn't throwing more compute at the problem.
It was teaching the AI to organize its own mind before it started dreaming.
Are we done with object detection? What about tiny objects beyond 200 meters? 🔎
Telescope 🔭 addresses long-range perception by explicitly tackling extreme scale imbalance ⚖️ in images. It hinges on a learnable hyperbolic foveation transform from a low-resolution image, magnifying distant regions 🔍 while compressing nearby ones - effectively normalizing object scales with minimal computational overhead. Objects are detected in the transformed (Riemannian) space using a novel bounding box parameterization and are then mapped back to the original image.
Project: https://t.co/mBuQGd7KnB
Yay, finally! Introducing Vision Banana🍌 from @GoogleDeepMind, our unified model that outperforms SoTA specialist models on various vision tasks!
By treating 2D/3D vision tasks as image generation, we unlock a new foundation for CV.
Project page: https://t.co/GQgRi6mWwC
(1/5)
🎉 After one year of teamwork, we are excited to release our 3D foundation model — LingBot-Map!
Unlike DA3/VGGT, LingBot-Map is a purely autoregressive model for streaming 3D reconstruction ⚡
It achieves ~20 FPS on 518×378 resolution over sequences exceeding 10,000 frames — and beyond 🚀
Two key insights behind LingBot-Map:
🔑 Keep SLAM's structural wisdom: build Geometric Context Attention with long-context modeling while maintaining a compact streaming state
🔑 Make everything end-to-end learnable — no optimization, no post-processing
Let's check out our demos 👇
LabelMe v6.1 is out.
- SAM3 AI-Box: drag one box, get multiple shapes
- AI toolbar: 4 tools collapsed into 2 (AI-Points, AI-Box)
- Progress bar for model downloads
- Open one image, the whole folder loads
Notes: https://t.co/aqMyE0MVJr
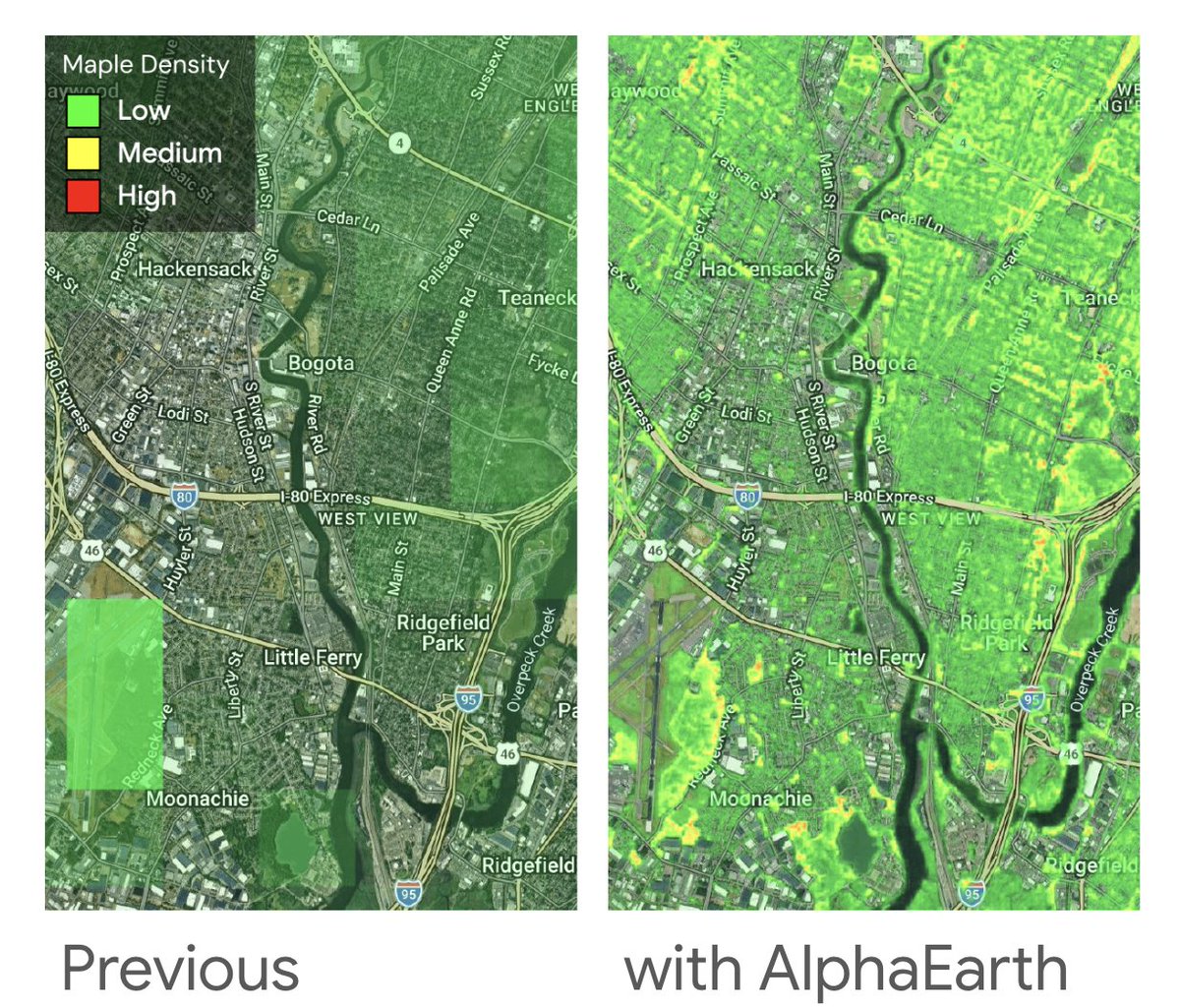
Incredibly rewarding to see foundational AI research translate into tools that millions of people rely on.
@GoogleDeepMind's AlphaEarth model is now powering high-resolution precise pollen maps for @googlemaps and Pixel Weather in the US - just in time for allergy season! 🌳🤧
Here’s an example showing pollen-producing Maple trees in New Jersey
Google just released the dense prediction TIPSv2 models on Hugging Face
A vision encoder with DPT heads for depth estimation, surface normals, and semantic segmentation — all trained on TIPSv2 B/14.
EUPE: Efficient Universal Perception Encoder👋
Looking for the most powerful small image models today?
Guess what: researchers at @AIatMeta cooked again!🍳
This time around, not some large vision encoder. Instead, a set of lightweight and efficient ones, both ViTs and ConvNeXts, all under 100M. The smallest is a ViT-Tiny at just 6M params!
But hear me out: this is the COOLEST thing ever...
🚨 BREAKING: NVIDIA proved backpropagation isn't the only way to build an AI.
They trained billion-parameter models without a single gradient.
Every AI you use today relies on backpropagation.
It requires complex calculus, exploding memory, and massive GPU clusters.
Meanwhile, an ancient, gradient-free method called Evolution Strategies (ES) was written off as impossible to scale.
Until now.
NVIDIA and Oxford just dropped EGGROLL.
Instead of generating massive, full-rank matrices for every mutation, they split them into two tiny ones.
The AI mutates. It tests. It keeps what works. Like biological evolution.
But now, it does it with hundreds of thousands of parallel mutations at once.
Throughput is now as fast as batched inference.
They are pretraining models entirely from scratch using only simple integers.
No backprop. No decimals. No gradients.
We thought the future of AI required endless clusters of precision hardware.
It turns out, we just needed to evolve.
Google descubrió un truco muy estúpido para que la inteligencia artificial te responda MUCHO mejor. Mientras todo el mundo busca el prompt perfecto, escribe instrucciones complejas y técnicas con nombres elegantes... unos investigadores de Google descubrieron que lo que mejor funciona es copiar y pegar tu pregunta dos veces.
¡Sí, así de simple! Le mandás el mismo texto dos veces seguidas y la IA responde mejor.
Probaron con Gemini, ChatGPT, Claude y DeepSeek: en matemáticas, razonamiento y comprensión lectora mejoró en todo. En un caso, un modelo pasó de 21% de precisión a 97%.
¿Y por qué carajo funciona esto? Porque la IA lee tu mensaje una sola vez, de izquierda a derecha, sin poder volver atrás. Si tu pregunta está al final, todo el contexto de antes se procesó sin saber qué le ibas a preguntar. Es como leer un capítulo entero de un libro y recién al final alguien te dice: "ah, buscá cuántas veces aparece la palabra perro". Ya es tarde. Pero si lo leés dos veces, la segunda vez ya sabés qué buscar.
Mientras vos buscabas el prompt perfecto, la respuesta era Ctrl+C, Ctrl+V. A veces la solución más bruta es la más inteligente.
Today we're introducing TRIBE v2 (Trimodal Brain Encoder), a foundation model trained to predict how the human brain responds to almost any sight or sound.
Building on our Algonauts 2025 award-winning architecture, TRIBE v2 draws on 500+ hours of fMRI recordings from 700+ people to create a digital twin of neural activity and enable zero-shot predictions for new subjects, languages, and tasks.
Try the demo and learn more here: https://t.co/VkMd1YpQWI
This is essentially LeCun's JEPA dream made practical— a clean, efficient, collapse-free world model that learns entirely from pixels with minimal engineering tricks. The key insight (SIGReg Gaussian regularization) is surprisingly simple.



























![gabriberton's tweet photo. Thread on a staple of modern computer vision: Masked AutoEncoder (MAE)
This 2021 FAIR paper proposes a new self-supervised technique to pretrain ViTs.
It is one of the first ViT-specific SSL technique, which showed the world the flexibility of the transformer [1/6] 🧵 https://t.co/EjIdJpk4hV](https://pbs.twimg.com/media/HG9B5OXaoAAVYo1.jpg)