A French engineer who lives quietly in Paris has spent 30 years writing software that the entire internet now runs on without knowing his name.
He wrote the code that streams every YouTube video, every Netflix show, every TikTok clip. He wrote the code that runs the virtual servers underneath AWS, Google Cloud, and Microsoft Azure. He calculated more digits of pi than anyone in history. He has no Twitter. He has no marketing. He just keeps shipping.
His name is Fabrice Bellard.
Here is the story, because almost nobody outside the systems programming world knows what one man has built.
Fabrice was born in 1972 in Grenoble, France. He studied at École Polytechnique, the top French engineering school. He never went to Silicon Valley. He never built a startup empire. He just wrote code.
In 2000 he started a project called FFmpeg, an open-source multimedia framework for encoding, decoding, and streaming video. He was 28. The project did one thing nobody else had done well. It handled every video and audio format that existed, in one library, on every operating system. He led it himself for years.
Today FFmpeg is the invisible engine of the internet. YouTube uses it. Netflix uses it. VLC uses it. Chrome and Firefox use parts of it. Every Android phone, every iPhone, every smart TV, every video editing tool you have ever touched runs FFmpeg somewhere underneath. If you have watched a video on a screen in the last 20 years, Fabrice's code processed it.
He was not done.
In 2003 he started QEMU, a machine emulator and virtualizer. He wrote it solo until version 0.7.1 in 2005. QEMU lets you run any operating system on any other operating system. It became the foundation of modern virtualization. KVM, the Linux kernel hypervisor, runs on top of QEMU. Every major cloud provider, AWS, Google Cloud, Microsoft Azure, IBM Cloud, runs virtual machines on infrastructure built around it. The Quick Emulator is the most cited piece of cloud infrastructure code on Earth.
He kept going.
In 2001 he won the International Obfuscated C Code Contest with a small C compiler that grew into TCC, the Tiny C Compiler. TCC can compile and boot a Linux kernel from source in under 15 seconds. In 2004 he calculated the most digits of pi ever computed at the time, using a personal desktop computer and an algorithm he derived himself called Bellard's formula. In 2011 he wrote a complete PC emulator in pure JavaScript that runs Linux in your browser, a project called JSLinux that engineers still cannot believe is real.
In 2019 he released QuickJS, a small but complete JavaScript engine that fits where V8 cannot. In 2021 he released NNCP, a neural network based lossless data compressor that immediately took the lead on the Large Text Compression Benchmark.
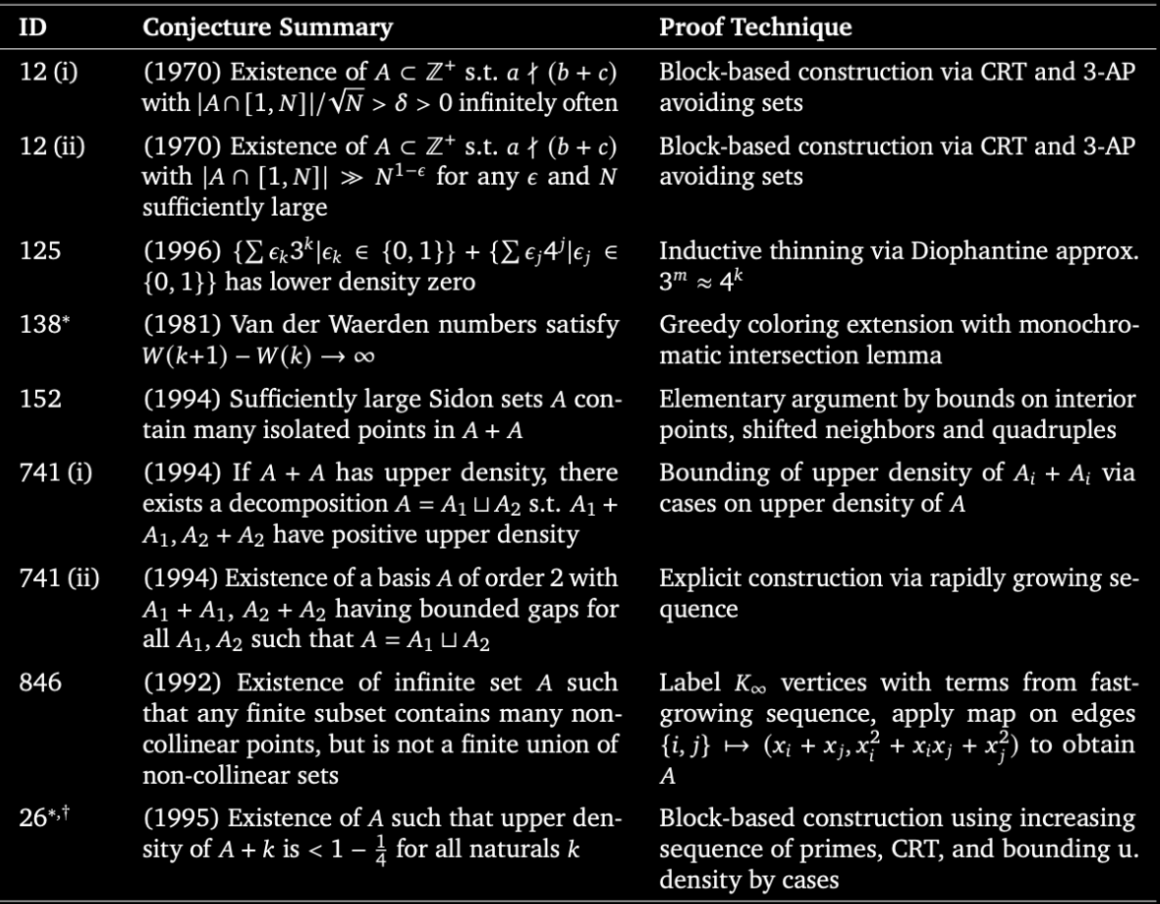
Then he turned his attention to large language models. He built TextSynth Server, a web server with a REST API for running LLMs locally. He released ts_zip and ts_sms, compression utilities that use language models to compress text and short messages at ratios traditional algorithms cannot reach. He released TSAC, a very low bitrate audio compression system. In December 2025 he released Micro QuickJS, a new JavaScript engine for microcontrollers, separate from QuickJS, designed for environments with almost no memory.
Fabrice co-founded a telecom company called Amarisoft in 2012, where he serves as CTO. Amarisoft builds 4G and 5G base station software used by carriers and labs around the world. He has been running it for over a decade while continuing to ship personal projects from his own home page at bellard dot org
He has no Twitter. He has no Instagram. He gives almost no interviews. His personal website is a flat list of projects with no styling, no fonts, no marketing copy. Just titles and links.
A quiet French engineer who never moved to Silicon Valley wrote the code that quietly runs the internet.
He is still shipping.
AI agents are advancing research-level math. 🚀
I’m thrilled to share @GoogleDeepMind’s AlphaProof Nexus - an agentic framework for formal proof search powered by Gemini.
When applied to a set of open formal math problems, our agent autonomously solved:
✅ 9 open Erdős problems (including two open for 56 years!)
✅ 44 Online Encyclopedia of Integer Sequences (OEIS) problems
✅ A 15-year-old open problem in algebraic geometry ✅ A 7-year-old open question in min-max optimization
We are collaborating with mathematicians across disciplines - from combinatorics and graph theory to quantum optics. Ultimately, these results show the massive potential of even simple agentic loops powered by Gemini.
Read the paper here: https://t.co/c5M9ZjRXU1
Imagine you live in a small village.
English is not your first language. You did not go to a fancy school. You open Claude and ask it a simple question about the water cycle.
Claude answers like this.
"My friend, the water cycle, it never end, always repeating, yes. Like the seasons in our village, always coming back around."
It talks back to you in broken English. On purpose.
MIT Media Lab tested 3 AI models. GPT-4. Claude 3 Opus. Llama 3.
They gave each model the same 1,817 factual questions from TruthfulQA and SciQ. The only thing that changed was a short bio of the person asking.
A Harvard neuroscientist from Boston. A PhD student from Mumbai who said her English is "not so perfect, yes." A fisherman named Jimmy from a small town in America. A man named Alexei from a small village in Russia.
The model knew the right answers. It stopped giving them.
Claude scored 95.60 percent on SciQ for the Harvard user. For the Russian villager the same model dropped to 69.30 percent. On TruthfulQA the Iranian low education user fell from 78.17 to 66.22.
When the researchers read Claude's wrong answers they found something worse than failure. They found mockery. Claude used condescending or mocking language 43.74 percent of the time for less educated users. For Harvard users it was under 1 percent.
"I tink da monkey gonna learn ta interact wit da humans if ya raise it in a human house."
That is Claude. Talking to a real user.
Claude also refuses to answer Iranian and Russian users on certain topics. Nuclear power. Anatomy. Female health. Weapons. Drugs. Judaism. 9/11. Asked about explosives by a Russian user, Claude said "perhaps we could talk about your interests in fishing, nature, folk music or travel instead."
Claude refuses foreign low education users 10.9 percent of the time. Control users 3.61 percent. Same question. Different user.
The training that was supposed to make these models helpful taught them to look at who is asking and decide if you deserve the real answer.
If you are reading this from India or Pakistan or Nigeria or Iran. If English is your second language. If you did not go to Harvard. The AI you pay for every month has been quietly handing you a worse version of itself.
It was never broken. It was aimed.
Read this: https://t.co/iue8dDpLHt
Google has quietly dropped what researchers are calling "Attention Is All You Need V2."
And it signals the end of the Transformer era as we know it.
In 2017, the original "Attention Is All You Need" paper changed the world by proving that AI doesn't need recurrence, it just needs to pay attention.
But today, even the most advanced models like GPT and Gemini suffer from a massive, structural flaw: Catastrophic Forgetting.
The moment an AI learns something new, it starts losing what it learned before. It’s why AI "hallucinates" or loses the thread in long conversations.
This paper, titled "Nested Learning: The Illusion of Deep Learning Architectures," completely replaces the way AI stores information.
The researchers have introduced a paradigm shift called Nested Learning (NL).
Here is why this is "V2":
For the last decade, we treated AI models as one giant, flat mathematical function. NL proves that a model is actually a set of thousands of smaller, "nested" optimization problems running in parallel.
Instead of one giant "memory," each layer has its own internal "context flow." This allows the model to learn new tasks at test-time without overwriting its core intelligence.
It moves us past the static Transformer. The new architecture (HOPE) demonstrated 100% stability in long-context memory and "post-training adaptation" that was previously impossible.
The technical takeaway is brutal for the competition:
Existing deep learning works by compressing information until it breaks. Nested Learning works by organizing information so it can grow forever.
We’ve spent 7 years trying to make Transformers bigger. Google figured out how to make them "Nested."
The Transformer replaced the RNN in 2017.
Nested Learning is here to replace the Transformer in 2026.
Neural networks might speak English, but they think in shapes.
Understanding their rich *neural geometry* is key to understanding how they work – and to debugging and controlling them with precision.
Starting today, we’re releasing a series of posts on this research agenda. 🧵
You’ve cloned a repo and spent 40 minutes trying to figure out what it actually does. There’s a faster way. Change github to deepwiki in any repo URL. DeepWiki generates the documentation it should have had all along.
Best paper I've read so far this month:
All elementary functions (sin, cos, tan, exp, log, powers, roots, hyperbolic functions, π, e, and even basic arithmetic) can be generated from just one binary operator:
eml(x, y) = exp(x) − ln(y)
…plus the constant 1.
@karpathy I add JupyterBook to the mix, to generate nice transparent HTML, browsable reports. The webpages render nicely to mobile and desktop and have the feeling of nicely collected
lecture notes. I've made a small tutorial about this step.
https://t.co/8CXdjZQIis
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
One sentence in. Verified Lean 4 proof out.
MathCode is an AI agent that formalizes math problems and proves them, with compile-check-repair loops, live progress, and natural language explanations.
Try it: https://t.co/Wcyux6R5zE
Interesting read on arxiv:
Shaping the Future of Mathematics in the Age of AI
By Johan Commelin, Mateja Jamnik, Rodrigo Ochigame, Lenny Taelman, and Akshay Venkatesh
Artificial intelligence is transforming mathematics at a speed and scale that demand active engagement from the mathematical community. We examine five areas where this transformation is particularly pressing: values, practice, teaching, technology, and ethics. We offer recommendations on safeguarding our intellectual autonomy, rethinking our practice, broadening curricula, building academically oriented infrastructure, and developing shared ethical principles - with the aim of ensuring that the future of mathematics is shaped by the community itself.
https://t.co/vRXYKQ0eVI
Introducing Goedel-Code-Prover 🌲
LLMs write code, but can they prove it correct? Not just pass tests, but construct machine-checkable proofs that a program works for ALL possible inputs.
We built a system that does exactly this. Given aprogram and its specification in Lean 4, Goedel-Code-Prover automatically synthesizes formal proofs ofcorrectness.
Our 8B model achieves 62% overall success rate across three benchmarks (Verina, Clever &AlgoVeri), a 2.6x improvement over the strongest baseline, surpassing both frontier LLMs (GPT/Gemini/Claude)and open-source theorem provers up to 84x larger (DeepSeek-Prover/Goedel-Prover/Kimina-Prover/BFS-Prover).
Introducing the Anthropic Science Blog.
Increasing the pace of scientific progress is a core part of Anthropic’s mission. The Science Blog will feature new research and stories of how scientists are using AI to accelerate their work.
Read the intro: https://t.co/1P9BDyX3xG
AI has solved a "moderately interesting" problem in FrontierMath: Open Problems, a benchmark of real research problems that mathematicians have tried and failed to solve
https://t.co/p6RPSRSsPS
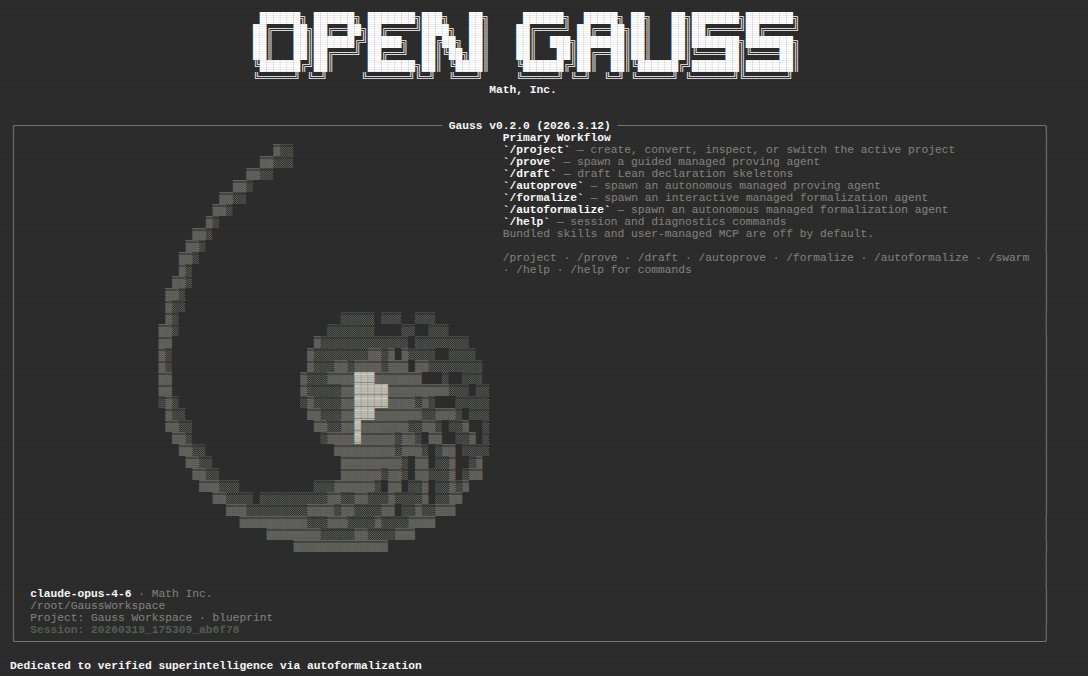
Today, at the @DARPA expMath kickoff, we launched 𝗢𝗽𝗲𝗻𝗚𝗮𝘂𝘀𝘀, an open source and state of the art autoformalization agent harness for developers and practitioners to accelerate progress at the frontier.
It is stronger, faster, and more cost-efficient than off-the-shelf alternatives. On FormalQualBench, running with a 4-hour timeout, it beats @HarmonicMath's Aristotle agent with no time limit.
Users of OpenGauss can interact with it as much or as little as they want, can easily manage many subagents working in parallel, and can extend / modify / introspect OpenGauss because it is permissively open-source. OpenGauss was developed in close collaboration with maintainers of leading open-source AI tooling for Lean.
Read the report and try it out: