Today, we enable AutoResearch in the physical world for the first time! Introducing ENPIRE: we give 8 Codex agents a fleet of robots, an allocation of GPUs, and generous token budget. We set them free with a simple goal: solve the task as quickly as possible, keep the robots busy but stay safe, don't waste precious compute. Make no mistake.
Then humans step aside and our watch begins. The robot fleet starts to come alive: they learn to look for visual clues, reset the scene, practice novel skills, tinker with control stack, read papers online, debate, reflect, get stuck, and try again directly on the hardware. All we did is to give Codex an API to the world of atoms, and the rest is emergence.
ENPIRE is able to solve high-precision tasks like tying zip-ties, organizing fine pins, and installing GPUs all by itself. We also discovered a new type of "physical scaling": 8 robots exploring in parallel improves significantly faster than fewer ones.
A part of our NVIDIA GEAR lab now self-improves tirelessly over night. We just read the reports in the morning.
/goal: we all take a holiday and Jensen wouldn't even notice ;)
We will be open-sourcing everything, so you can host your self-running robot lab at home too! Deep dive in the thread:
Hot take: robots should not dream in pixels.
Pixels are too low-level.
Latents are too opaque.
μ₀ predicts a third thing:
3D motion traces.
On real robots, it beats π₀.₅ — with ~1/100 the data scale and no action labels for world-model pretraining. 🧵
https://t.co/UfmrqNlBtw
(this video features voiceover narration)
Vision and Robotics for Embodied AI
What an incredible meeting at the intersection of vision and robotics!
Would have absolutely loved to attend and be part of these discussions. Really inspiring to see so many leading researchers from embodied AI, robotics, and computer vision coming together 💪
#EmbodiedAI #Robotics #ComputerVision
@mapo1@dimadamen@JitendraMalikCV Vladlen Koltun @andyzengineer@CordeliaSchmid@GeorgiaChal@danfei_xu@SiyuTang3@yukez@ylecun@CSProfKGD and many other outstanding researchers.
https://t.co/rDckL7sfK3
"Claude usage limit reached. Your limit will reset at 7pm"
every. fucking. day.
was about to pay $200 for Max. then I read this article
98.5% of tokens - wasted
you're not paying for answers. you're paying for Claude to re-read its own homework 30 times
spent months blaming Anthropic for being greedy. turns out the problem was how I write prompts
5 minutes of reading
basic plan now handles more than my old Max
𝗟𝗼𝗻𝗴-𝗵𝗼𝗿𝗶𝘇𝗼𝗻 𝗿𝗼𝗯𝗼𝘁𝗶𝗰𝘀 𝗵𝗮𝘀 𝗮𝗻 𝗶𝗻𝗳𝗼𝗿𝗺𝗮𝘁𝗶𝗼𝗻 𝗱𝗲𝗰𝗮𝘆 𝗽𝗿𝗼𝗯𝗹𝗲𝗺.
Most imitation learning models hit a "memory ceiling" as task length increases. Policies struggle to distil smaller, intermediate goals from the larger mission - so as execution stretches on, the robot loses the thread. It keeps moving, but the movements no longer connect to any meaningful objective. The result is policy drift: technically correct actions that make no sense for the goal.
Researchers from @deepmind and @cmu propose BPP, an approach that addresses this by conditioning policies on milestone keyframes detected by a Vision-Language Model (VLM). Instead of forcing a model to digest every raw frame in a massive history window, BPP anchors execution to the specific visual "Big Picture" milestones that define success.
Key Systems Advancements:
• 𝟳𝟬% 𝗛𝗶𝗴𝗵𝗲𝗿 𝗦𝘂𝗰𝗰𝗲𝘀𝘀 𝗥𝗮𝘁𝗲𝘀: Significant performance gains in real-world manipulation tasks that require deep history conditioning
• 𝗩𝗟𝗠-𝗚𝘂𝗶𝗱𝗲𝗱 𝗔𝗻𝗰𝗵𝗼𝗿𝗶𝗻𝗴: Uses the reasoning power of VLMs to identify and remember the critical stages of an operation.
• 𝗦𝘆𝘀𝘁𝗲𝗺 𝗘𝗳𝗳𝗶𝗰𝗶𝗲𝗻𝗰𝘆: Reduces the computational tax of processing long histories by focusing on semantic milestones rather than raw motor paths.
The key insight is that long-horizon tasks aren't one problem, they're many smaller ones chained together. Rather than training one large model to handle everything, the better path is training many specialised models, each responsible for a distinct milestone, and composing them into a high-level goal.
@Neuracore_AI is built for exactly this. Teams can spin up and train multiple specialised models in parallel and rapidly iterate across all of them simultaneously. Instead of waiting on a single monolithic model, you build a library of targeted policies and orchestrate them toward the bigger objective.
“Everyone knows” what an autoencoder is… but there's an important complementary picture missing from most introductory material.
In short: we emphasize how autoencoders are implemented—but not always what they represent (and some of the implications of that representation).🧵
Excited to share what we've been cooking @GoogleDeepMind to bring Gemini into the physical world! 🦾🧠
Here is an uncut interaction of the Gemini Robotics VLA helping me clean up my desk. 🔊
Interacting with a robot through voice is the most surreal experience, and parallels the giddy excitement I had playing with early LLMs that is hard to put in words. You've got to try it to believe it!
Over the next few days, we'll be sharing more such interactions that go beyond shiny demos and expose raw capabilities of our models. Stay tuned for more raw videos!
Tech Report: https://t.co/83NBmieIHZ
Blog: https://t.co/7VINxV3D3y
YouTube Playlist: https://t.co/pFLdQLDtiA
Diffusion models are so ubiquitous, but it's difficult to find an introduction that is concise, simple and comprehensive.
My supervisor Rich Turner (with me & some other students) has written an introduction to diffusion models that fills this gap:
https://t.co/c9fBSXMMtl
The field of Robotics + AI is at a very interesting moment in time right now because we’re seeing the evolution of how optimism from the last 10 years of research is carrying over to new frontiers: towards commercialization, towards more complex morphologies and applications, towards dreams of generality usually reserved for “AGI research”.
There are now big questions around how historic trends will project onto the current robotics + AI wave. How applicable are the cyclical patterns we’ve seen play out in frontier modeling? In RL + search? In AV commercialization? In agent/code GenAI? In SaaS customer flywheels? In hardware startups tackling integration challenges?
But more interesting is that there are even big questions around how actual *robotics research* applies to these new frontiers! There’s been a lot of exciting progress in the last years on training large multitask robot policies, on sim2real policy learning, on fleet-scale robot data collection, on learning robust and generalizable policies — but most of this research targeted embodiments and application complexities that are substantially simpler than where goalposts are today with complex manipulation, humanoids, and commercial production requirements.
I think this last point is especially important and undervalued. A lot of folks new to robot learning are assuming that the same scaling laws and approaches that have worked elsewhere will easily be applied in robotics: self-play in AlphaGo, world model learning in video generation, sim2real in locomotion, search in CodeGen/math, exploration in Minecraft. These are indeed very promising and exciting research areas, but my main advice when asked about these directions is that robotics has a very different set of operating constraints and comparative challenges than other domains.
Moravec’s Paradox applies to technical algorithms as well: what methods excel at in one domain they may struggle with in robotics, and where methods face challenges in other domains they may scale better in robotics.
In 2021, my father was diagnosed with a benign brain tumor & hydrocephalus. As serious as this sounds, technologies do exist to repair & recover (radiosurgery, shunt surgery, etc.). Sadly, none were available in Honduras. Long story short, after thousands of dollars, treatment abroad, & help from family contacts, he received the care he needed & is back to being himself.
My dad *is the exception*; most people in places like Honduras (5/8 billion people worldwide🌎) will deteriorate or die from perfectly treatable conditions. Do we, as engineers, have any role to play? Should we, & how can we, design technologies to improve access to safe & affordable surgery? Really looking forward to this conversation!
@ImperialRobots@ICLHamlynRobots
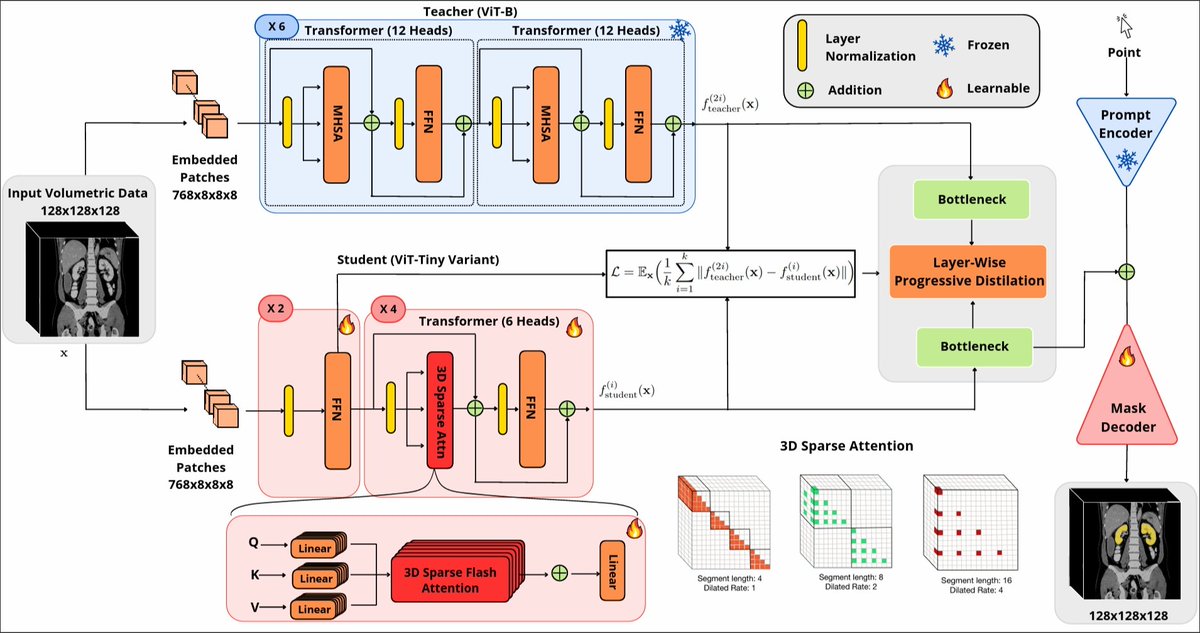
Need to "segment anything" in 3D medical images? Yes?
Want quick reaction to prompts, like **volumetric segmentation in ~8 ms**? Yes?
Consider FastSAM3D: https://t.co/yvu5UTQAQM, ~500x/9x speedup over 2D and 3D SAMs, respectively.
Code: https://t.co/Wm8lz0TsNI
@JHUCompSci
Very excited to share what our research team at Covariant has been working on: RFM-1, our latest Robotics Foundation Model. Built on top of high-quality multimodal data the Covariant robotics fleet has collected over the years, this project embodies our commitment to pushing the boundaries of how AI can interact with and understand the physical world. We're eager to share this milestone with the community and invite feedback and collaboration. Read more at https://t.co/Cc3Wmyk2N7
BioMistral is a new 7B foundation model for medical domains, based on Mistral and further trained PubMed Central.
- top open-source medical Large Language Model (LLM) in its weight class
- Apache License
- includes base models, fine tunes, and quantized versions.
📢 Having synthetic negatives in self-supervised contrastive learning is important, but how to add them?
Check out our preprint paper "Unsupervised hard Negative Augmentation for contrastive learning"!
Paper: https://t.co/NcBQLqDnhg
Code: https://t.co/bOoOrMk4xZ
#NLP
Mobile ALOHA 🏄 is coming soon!
Special thanks to @tonyzzhao for throwing random objects into the scene, and @chelseabfinn for the heavy pot (> 3 lbs) !
Stay tuned!
Create Your Own Custom LLM Chatbot
Impressive step-by-step tutorial explaining how to choose the best LLM and the components needed for building your own custom LLM-powered chatbot.
@abacusai offers one of the best solutions that I've used to quickly build custom LLM chatbots.
The foundational parts discussed in the tutorial are:
• Data sources - data warehouses, data lakes, and a range of databases are supported. You can also transform data within the platform as needed. There is even an AI agent that can assist with operating on data.
• Chunk size - the chunk size determines how to split the text; this affects performance and varies by use case. You should also think about the overlap between adjacent chunks so information is not abruptly cut off.
• Embedding technique and document retriever - the chunks of texts are embedded and stored in a vector database that helps you build a powerful retriever that the LLM interacts with to ensure it's using the relevant information to answer questions. This is particularly useful for a lot of knowledge-intensive use cases.
• LLM - the synthesizing capabilities of LLMs combined with the retrievers enables a robust solution to create your custom LLM chatbots and pick the best LLM for your dataset and task. With @abacusai you can choose between models offered by Google, OpenAI, Anthropic, the open-source community, and Abacus's proprietary LLMs. I like that you can also fine-tune your own models as well so the offering is pretty comprehensive.
• Automation and Evaluation - picking the right model and the right configurations is challenging. The AutoML capabilities of Abacus help in this regard. You can also upload an evaluation dataset that enables the platform to compare combinations and determine an optimal solution for your use case. Metrics include BLEU score, METEOR, and others.
• Deployment & Monitoring - this whole process is iterative in nature and new data will always be available. You can deploy your LLMs and set up pipelines to keep incorporating or fine-tuning on new data. Having your solution in production means you need to continuously evaluate and monitor performance on a regular basis to ensure the solution doesn't deteriorate.
Read more here: https://t.co/WcQEbqtAZa
If there is enough interest, I will also be posting a full demo with a use case in an upcoming post. Stay tuned!