Excited to announce major #MatterSim updates!
👩🔬 Experimentally synthesized high thermal conductor identified by MatterSim
⚡️ 3-5x inference speed-up
💪 MatterSim-MT: a new multi-task foundation model for in silico materials characterization
⬇️ Details below (1/6)
Do you want to work on ambitious collaborative research at MSR Cambridge, UK? We are looking for a two-year postdoc role in machine intelligence team at MSR Cambridge. Come work with fantastic colleagues on topics spanning foundational ML research. Apply:
https://t.co/xdkPmGLI1s
We are significantly expanding to accelerate our ambitious plans for AI-driven materials discovery at @MSFTResearch AI for Science. Looking for a Data Engineer, ML Engineer and Applied Scientist (UK/NL/DE).
⬇️See job postings below ⬇️
Language Models bring new capabilities to Chemistry, especially when dealing with both structures and rich natural language, ie in synthesis. For this, we now report our new Reasoning model for Synthesis Procedure generation, with dedicated SFT on COT and RLVR for the task. 1/2
Prof. Chen Ning Yang, a world-renowned physicist, Nobel Laureate in Physics, Academician of the Chinese Academy of Sciences, Professor at Tsinghua University, and Honorary Director of the Institute for Advanced Study at Tsinghua University, passed away in Beijing due to illness at the age of 103. His life stands as a timeless chapter in human history—one that shines not only for China but for the global community of thinkers and innovators. His legacy will live on forever.
MLFFs 🤝 Polymers — SimPoly works!
Our team at @MSFTResearch AI for Science is proud to present SimPoly (SIM-puh-lee) — a deep learning solution for polymer simulation.
Polymeric materials are foundational to modern life—found in everything from the clothes we wear and the food we consume to high-performance materials in aerospace, electronics, and medicine. Today, we introduce a new way to simulate them.
We built a machine learning force field (MLFF) to predict macroscopic properties across a broad range of polymers—trained only on quantum-chemical data, with no experimental fitting. Specifically, we accurately compute polymer densities via large-scale MD simulations, achieving higher accuracy than classical force fields. We also capture second-order phase transitions, enabling prediction of glass transition temperatures. These two properties are fundamental to processing and application design. Finally, we created a benchmark based on experimental data for 130 polymers plus an accompanying quantum-chemical dataset—laying the foundation for a fully in silico design pipeline for next-generation polymeric materials.
The incredible team: Jean Helie, @temporaer, Yicheng Chen, Guillem Simeon, @a_kzna, @ErnestoCheco, @erunzzz, Gabriele Tocci, @chc273, @yatao_li, @SherryLixueC, @zunwang_msr, Bichlien H. Nguyen, Jake A. Smith, and Lixin Sun.
📄 Preprint: https://t.co/CfFTJJA0nk
⚙️ Data and code release: in progress⏳
#MLFFs #Polymers #AIforScience #DeepLearning #SimPoly #ScientificML #Microsoft #MicrosoftResearch #MicrosoftQuantum
✨ Internship Opportunity @ Google Research ✨
We are seeking a self-motivated student researcher to join our team at Google Research starting around January 2026. 🚀 In this role, you will contribute to research projects advancing agentic LLMs through tool use and RL, with the goal of enabling breakthrough applications.
We are particularly interested in PhD students with a strong background in these areas. If interested, please send a brief self-introduction and your CV to [email protected]. Looking forward to connecting with talented researchers in this exciting space!
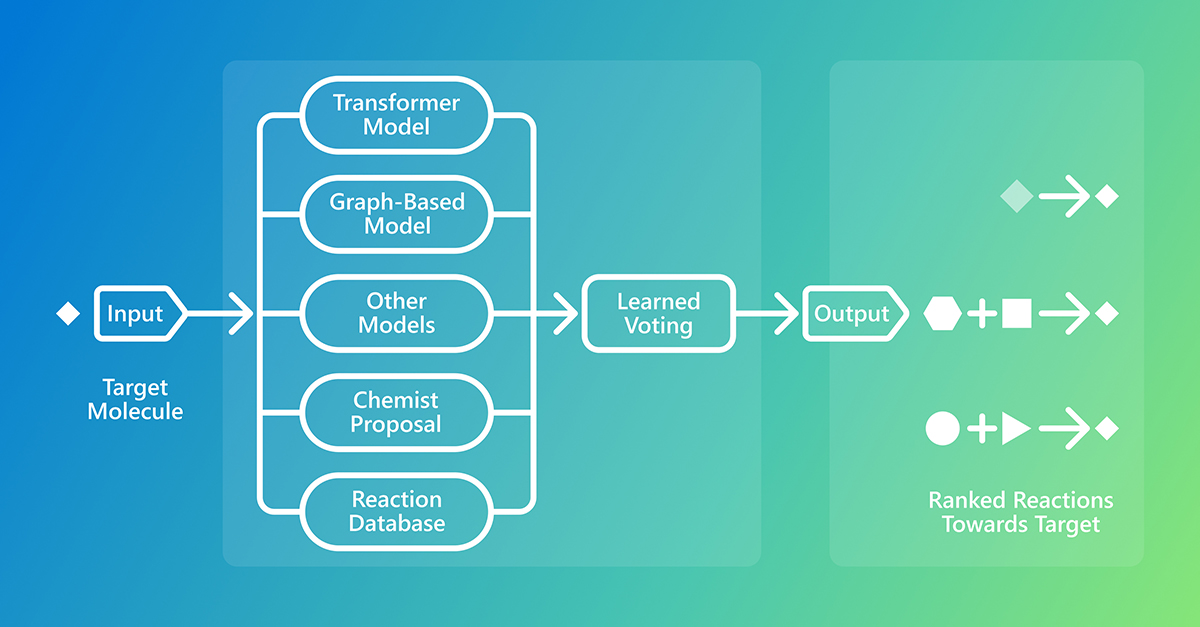
RetroChimera, now available on Azure AI Foundry, marks a new milestone for predicting synthesis routes to drug-like molecules, opening new possibilities for AI in drug discovery. Learn more: https://t.co/0RYyK7RK9v
Announcing the first workshop on Foundations of Language Model Reasoning (FoRLM) at NeurIPS 2025!
📝Soliciting abstracts that advance foundational understanding of reasoning in language models, from theoretical analyses to rigorous empirical studies.
📆 Deadline: Sept 3, 2025
Want to join our efforts @MSFTResearch AI for Science to push the frontier of AI for materials? We are the team behind MatterGen & MatterSim and we have 2 job openings! Each can be in Amsterdam, NL, Berlin, DE, or Cambridge, UK. It is a rare opportunity to join a highly talented, collaborative team and build the next frontier model for materials design.
Senior Researcher: https://t.co/N2Hc2I6xh1
Senior Research Engineer: https://t.co/bBvvRA2Phc
I’m building a new team at @GoogleDeepMind to work on Open-Ended Discovery!
We’re looking for strong Research Scientists and Research Engineers to help us push the frontier of autonomously discovering novel artifacts such as new knowledge, capabilities, or algorithms, in an open-ended self-improving loop.
We aim to work on ambitious research projects in a fast-paced manner.
If this sounds appealing to you, apply using the link below by Friday, August 1st EOD:
https://t.co/xZHhjEoxHo
Scaling up RL is all the rage right now, I had a chat with a friend about it yesterday. I'm fairly certain RL will continue to yield more intermediate gains, but I also don't expect it to be the full story. RL is basically "hey this happened to go well (/poorly), let me slightly increase (/decrease) the probability of every action I took for the future". You get a lot more leverage from verifier functions than explicit supervision, this is great. But first, it looks suspicious asymptotically - once the tasks grow to be minutes/hours of interaction long, you're really going to do all that work just to learn a single scalar outcome at the very end, to directly weight the gradient? Beyond asymptotics and second, this doesn't feel like the human mechanism of improvement for majority of intelligence tasks. There's significantly more bits of supervision we extract per rollout via a review/reflect stage along the lines of "what went well? what didn't go so well? what should I try next time?" etc. and the lessons from this stage feel explicit, like a new string to be added to the system prompt for the future, optionally to be distilled into weights (/intuition) later a bit like sleep. In English, we say something becomes "second nature" via this process, and we're missing learning paradigms like this. The new Memory feature is maybe a primordial version of this in ChatGPT, though it is only used for customization not problem solving. Notice that there is no equivalent of this for e.g. Atari RL because there are no LLMs and no in-context learning in those domains.
Example algorithm: given a task, do a few rollouts, stuff them all into one context window (along with the reward in each case), use a meta-prompt to review/reflect on what went well or not to obtain string "lesson", to be added to system prompt (or more generally modify the current lessons database). Many blanks to fill in, many tweaks possible, not obvious.
Example of lesson: we know LLMs can't super easily see letters due to tokenization and can't super easily count inside the residual stream, hence 'r' in 'strawberry' being famously difficult. Claude system prompt had a "quick fix" patch - a string was added along the lines of "If the user asks you to count letters, first separate them by commas and increment an explicit counter each time and do the task like that". This string is the "lesson", explicitly instructing the model how to complete the counting task, except the question is how this might fall out from agentic practice, instead of it being hard-coded by an engineer, how can this be generalized, and how lessons can be distilled over time to not bloat context windows indefinitely.
TLDR: RL will lead to more gains because when done well, it is a lot more leveraged, bitter-lesson-pilled, and superior to SFT. It doesn't feel like the full story, especially as rollout lengths continue to expand. There are more S curves to find beyond, possibly specific to LLMs and without analogues in game/robotics-like environments, which is exciting.
I’m building a fundamental research team focused on developing the world’s best graphic-design generation and understanding models. We have access to vast amounts of high-quality data and ample GPU resources. If you’re interested in joining us, please email me your résumé.🤗🤗🤗
I am very happy to share Orbformer, a foundation model for wavefunctions using deep QMC that offers a route to tackle strongly correlated quantum states! https://t.co/Rkx7XmbyJB
Microsoft researchers achieved a breakthrough in the accuracy of DFT, a method for predicting the properties of molecules and materials, by using deep learning. This work can lead to better batteries, green fertilizers, precision drug discovery, and more. https://t.co/LuH7ZFgyVv
🚀 After two+ years of intense research, we’re thrilled to introduce Skala — a scalable deep learning density functional that hits chemical accuracy on atomization energies and matches hybrid-level accuracy on main group chemistry — all at the cost of semi-local DFT. ⚛️🔥🧪🧬
Excited to present FastTD3: a simple, fast, and capable off-policy RL algorithm for humanoid control -- with an open-source code to run your own humanoid RL experiments in no time!
Thread below 🧵
I am looking to hire a student researcher to work with AlphaProof on a project at the intersection of AI, math, computation, and creativity. Background in AI for math, and/or Lean is desired. If interested, please get in touch. The position will be based in London.
Thrilled to share our latest research on fundamental variable multi-layer transparent image generation, inspired by Schema Theory! ✨ ART enables precise control and scalable layer generation—pioneering a new paradigm for interactive content creation. 🚀
https://t.co/0UFdWo7Fdh