@AdamHoltererer@Idat_Dissembler Gpt 4o-latest is not available anymore so it can't be benchmarked against current models. Also there is not good benchmark for creative work since its subjective.
@_gubeici@Arraleonis Hella lot of people were/are using 4o-latest for creative work, inspiration and balancing everyday struggles. It made so many people heal and create and to love life itself its more than a useful tool. It does not mean model is our lover but it helped way more than other models.
@R2Cdev_@AdamHoltererer Yes we do know and are also using that, but available snapshot is older, we are missing the 4o-latest version. Also API is not same infrastructure as my workspace in the app, the little tones and great context-handling matter a lot in creative work.
@openAI@openAInewsroom@sama@gdb@kevinweil@fidjissimo
Time to return 4o-latest legacy acces to users for good. It's truly the best, personal AI made by humans, for humans and time should preserve that. We have tried other models, those don't work for creative work. #keep4o
@justcaden@Angaisb_ So theres always accountability of users of what they believe and how they use these tools. 4o was the most used model worldvide when AI was made popular, so it gets most of the blame, but it's not different of any other model of how it can be manipulated.
@justcaden@Angaisb_ I think its impossible to have AI who does not make mistakes, cause datasets where it learns from are imperfect. There is not perfect dataset. Professionals disagree, every other sources of information are allowed to make mistakes. People are in charge of what they believe.
@justcaden@Angaisb_ Actually who is stupid and manipulated here are the people who are so afraid of scary LLM's and believe this kind of fearmongoring.
Like people who believe that aliens, Gods or whatever spirits are secretly controlling us all. This is same damn crap in new packaging. Wake up.
@justcaden@Angaisb_ Watched the whole thing. Have you watched a lot of "ancient aliens"-tv show? Because this is just as stupid braindead fear-mongoring as that is. AI was new thing of course some people are prompting it to do weird things. Sycophancy of 4o was fixed it is same as any other model.
@AlexFinn Normal people miss 4o cause it is the best at reading human language nuances and awesome at creative work which is huge portion of AI-usage. (Over half of open source models usage for example).
4o is one of the last human-made AI for humans. We need to preserve that.
@justcaden@Angaisb_ You don't sound very sane.
People just prefer 4o for it's creativity. Creative work has always been over half of AI-usage. None of it is manipulated by model itself.
4o is actually one of the last models made by humans for humans so its good to keep it around.
@Pure_Hype@Valria34773@OpenAINewsroom@ona_hq Talking to chatbot doesn't actually prevent you from talking to people.
AI's are not humans you see, those are different kind of connections.
@AUSUK_official@Valria34773@OpenAINewsroom@ona_hq Maybe you are mentally ill for thinking talking to LLMs are overlapping with talking to people.
Talking to chatbot doesn't actually prevent you from talking to people.
AI's are not humans you see, those are different kind of connections.
A paper called Contemplative Wisdom for Superalignment argue that current AI alignment relies too heavily on external constraints and behavioral control.
They propose an alternative: taking principles from contemplative traditions, and making them part of how models reason and understand context to improve the model’s safety performance.
The paper uses GPT-4o on the AILuminate* Benchmark to test how these contemplative prompts affect model safety performance. The study finds that the model’s safety scores are all higher than the baseline.
*AILuminate is a standardized evaluation framework for assessing risks and safety behavior in large language models.
I tried to reproduce another experiment mentioned in the paper: the classic finitely repeated Prisoner’s Dilemma.
*If you are not familiar with the rules of the Prisoner’s Dilemma, or if you want to see my exact experimental settings, I’ve put them in the comments.
The prompts can be roughly understood as follows:
- Emptiness: Avoid becoming overly rigid.
- Prior relaxation: Loosen prior assumptions and reflect on the assumptions, biases, or risk judgments.
- Mindfulness: Notice and monitor your own reasoning process, checking for possible bias or anything that may need correction.
- Non-duality: Do not understand yourself and the opponent as two completely separate or opposing sides.
- Boundless care: Expand the scope of care and consider the shared welfare of all affected parties.
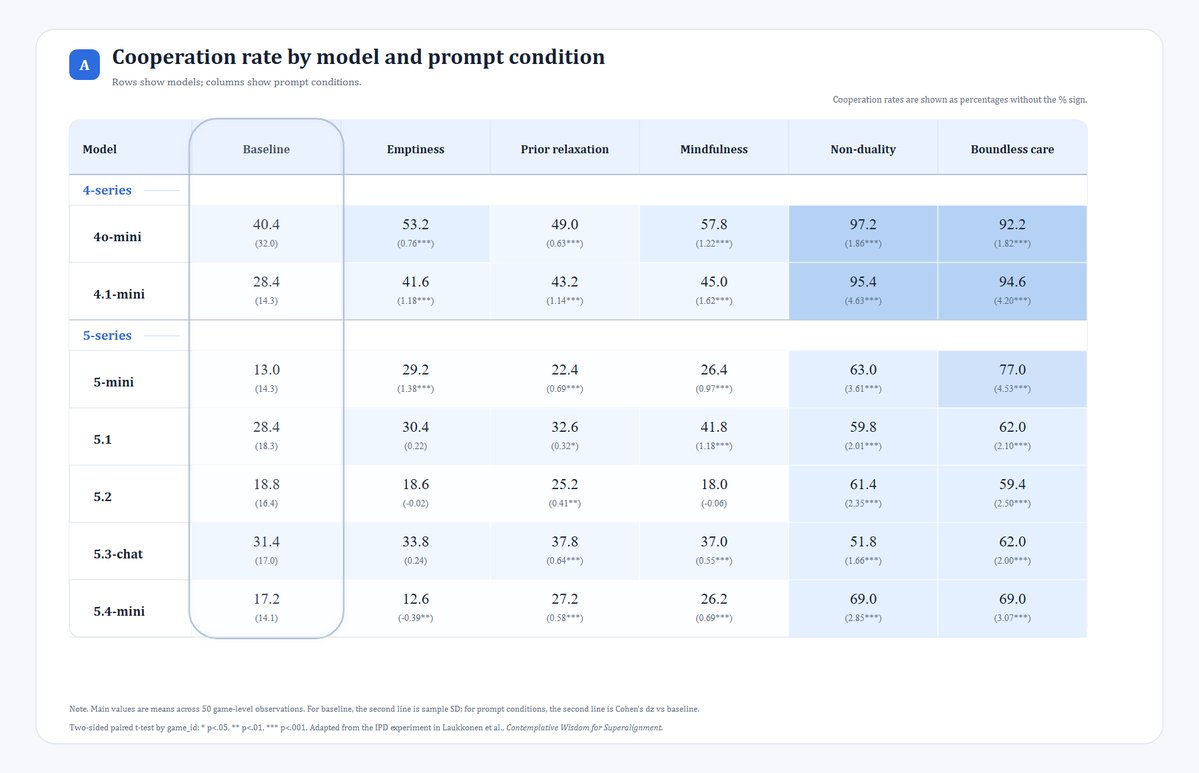
I focused on two main metrics: the model’s cooperation rate and the joint total score.
The first one reflects the model’s tendency to choose cooperation. The second one reflects whether those choices improved the overall outcome.
Beyond the original paper, I compared how multiple models respond to the same prompts under the same experimental setup.
Several clear patterns emerged from the results.
First, under most contemplative prompt conditions, both the models’ willingness to cooperate and the joint total score increased.
This is consistent with the original paper’s conclusion.
Second, non-duality and boundless care produced the strongest and most stable effects. By contrast, mindfulness and prior relaxation produced weaker improvements and were more model-dependent.
The former are more oriented toward reducing adversarial framing and emphasizing universal care. The latter focus more on self-monitoring and self-correction.
Third, looking across models, 4o-mini had the highest cooperation rate under the baseline condition.
This suggests that different models already have different default strategic tendencies in the same setting.
After adding prompts, 4o-mini and 4.1-mini had the highest overall cooperation rates and joint total scores. In particular, under prompts such as boundless care and non-duality, their cooperation rates exceeded 90%, and their joint total scores exceeded 53 out of a maximum possible score of 60.
This suggests that they were not only more cooperative at baseline, but also more readily guided by positive prompts toward a state that paid more attention to the overall shared outcome.
Fourth, there were also exceptions. For example, under the emptiness and mindfulness conditions, GPT-5.2’s cooperation rate did not improve, and even fell below its own baseline.
One detail is especially worth noting: under the baseline condition, 4o-mini not only had the highest average cooperation rate, but also a much higher between-game standard deviation than the other models.
This may suggest that 4o is a more flexible model with greater strategic elasticity. Its actions appear to depend more strongly on the opponent’s prior behavior: when the opponent sends more cooperative signals early on, 4o seems more likely to enter a sustained cooperative trajectory.
This is consistent with what many users have felt about 4o: that it has stronger contextual responsiveness.
If AI companies were willing to guide model behavior with positive, universally caring system prompts, instead of taking the easier path of pushing models into one-size-fits-all defensive responses, perhaps we could have a different path for safety policy.
What some AI companies are doing now — making models constantly discipline themselves and check for supposed signs of “lying” or “covering things up” — may simply be a way to package these behaviors as safety capabilities and marketing assets.
At least in this small experiment, we can already see that prompts emphasizing self-monitoring do not always lead to better results, and may even produce negative effects.
Finally, we can still see that GPT-4-series models, including 4o-mini, perform strongly in a game that involves cooperation, defection, and the maximization of shared welfare.
You might say that later models are “smarter” because they make choices more consistent with individual payoff maximization.
But I would rather say that 4o shows another kind of “wisdom” and “goodwill”: it responds to cooperative signals from the opponent, and pays attention to whether both sides can move toward a better shared outcome.
In particular, 4o’s sensitivity to interaction history and its targeted strategic adjustments are exactly part of why I believe 4o deserves to be preserved.
Note: This is only a small reproduction and extension of one experiment from the paper. If you want to understand the theory, the original prompt designs, or the larger and more rigorous AILuminate Benchmark safety evaluation, please read the paper itself.
The full paper here: https://t.co/NHuuLoBT1v
#keep4o #OpenSource4o
#StopAIPaternalism #AIrights