Jeff Bezos: “People who are right a lot change their mind a lot”
“Because of AI, new technologies, and all the dynamism in the world, so many things are changing — and they’re changing rapidly,” Jeff observes.
The best solution he’s found for dealing with this rapid change is “thinking long-term” because it forces you to ask yourself, “What are the points of stability?” and “What is not going to change?”
He continues:
“One of the things that changes very slowly is customer needs. So you can build a strategy around customer needs. That will have durability.”
When building Amazon, for example, Jeff built the company around the customer needs of fast delivery, low prices, and vast selection.
“The technologies will change. Your competitive set will change. Everything will change, except those customer needs,” Jeff argues.
And it’s this idea that is behind Jeff’s core idea of “Be stubborn on the vision, and flexible on the details.”
He explains:
“You have to be [flexible on the details] because the world is changing and so you change your mind. I’ve noticed that people who are right a lot change their mind a lot. People who are wrong a lot are very stubborn on the details.”
Source: @reuters (Oct 2025)
My conversation with @RickRubin
0:00 Less Is More But Harder
2:00 Def Jam From The Dorm Room
4:00 Capturing Club Energy On Record
6:00 Going Deep On Influences
12:30 Why Reduced By Rick Rubin
14:00 Beatles Structure Meets Rap
16:00 The Ruthless Edit
19:30 Eminem: The Most Obsessive Artist
22:00 Lazy Workaholic
25:30 Protecting The Moment Of Magic
29:00 Dana White And Becoming A Podcaster
32:30 Professional Listener
44:00 Fishing And Showing Up
47:00 Johnny Cash And Constraints
55:30 Church Business vs. Banking Business
58:50 Run On Intuition Alone
1:01:00 Jay-Z vs. Eminem Process
1:04:30 In Service Of The Artist
1:09:00 Work As Diary Entries
1:13:30 Four Ways Success Destroys You
1:16:00 How To Sustain Success
1:21:00 The House On The Mountain
Includes paid partnerships.
Jeff Bezos: “I once asked Warren Buffett, why don’t more people copy your investment strategy? It’s not that difficult to understand in principle. And he said, ‘Oh, Jeff, that’s easy. My approach is a get-rich-slowly scheme.’ And people don’t like those.”
“If you can think in terms of seven years instead of three years, and you can defer gratification and think long term, that will give you a head start against all of your competitors, because most people can’t do that.”
La tecnología amplifica la sociedad que la adopta.
Si una sociedad tiene buena educación, la IA convierte a un alumno curioso en alguien mucho más capaz. Si la educación es débil, la IA convierte la ignorancia en un texto bien escrito.
Si una empresa sabe vender, medir, ejecutar y atender clientes, el software la vuelve más productiva. Si la empresa sólo usa tecnología para aparentar modernidad, cambia la pantalla pero no cambia el negocio.
Si un hospital tiene protocolos claros, datos ordenados, auditoría y médicos responsables, la IA reduce errores y detecta riesgos antes. Si el sistema está desorganizado, la IA sólo añade otra capa de confusión con apariencia científica.
Si un Estado sabe decidir, comprar bien, licenciar rápido y medir resultados, la tecnología transforma servicios públicos. Si el Estado está capturado por ministerios, consultoras, ventanillas y relatos, la tecnología se convierte en otro presupuesto que anunciar.
Por eso la pregunta importante no es si una sociedad tiene acceso a IA, robots o software. Casi todas lo tendrán. La pregunta es qué estructura humana hay debajo.
La misma herramienta puede producir prosperidad o dependencia. Puede liberar tiempo o destruir atención. Puede mejorar la medicina o multiplicar diagnósticos opacos. Puede enseñar mejor o ayudar a fingir que se sabe.
La tecnología no sustituye carácter, criterio, instituciones ni responsabilidad. Los multiplica.
Y ahí está la gran diferencia entre países en esta década. No ganará el que tenga más discursos sobre innovación. Ganará el que convierta tecnología en aprendizaje, productividad, salud, vivienda, energía, empresas y mejores decisiones.
La IA no arregla una sociedad que no quiere mirar sus problemas. Pero acelera mucho a una sociedad que sí quiere resolverlos.
The honest secret of running AI agents inside a real company is this: the model is not the bottleneck anymore. The bottleneck is what happens when the agent is wrong.
I run agents across several of my companies. They sort emails, manage dashboards, block bots on X, draft replies, summarize calls. The first version is always magical. The tenth version is where you learn the real lessons.
The model is rarely the problem. The problem is that nothing in the stack tells you, in production, that the agent quietly drifted. It does not crash. It does not error. It just becomes slowly worse at the job, and three weeks later you realize half of its outputs are subtly wrong.
What you actually need is unglamorous: evals you trust, logs you can search, the ability to roll a single agent back to last week, and a human review queue for anything that touches money, legal text or a customer. Most teams skip all four because they are not as fun as a new model.
The companies that win with agents will not be the ones with the smartest model. They will be the ones whose engineers treat agents like junior employees with bad memory and worse judgment, and build the supervision around them accordingly.
Intelligence is cheap now. Accountability is what will be priced.
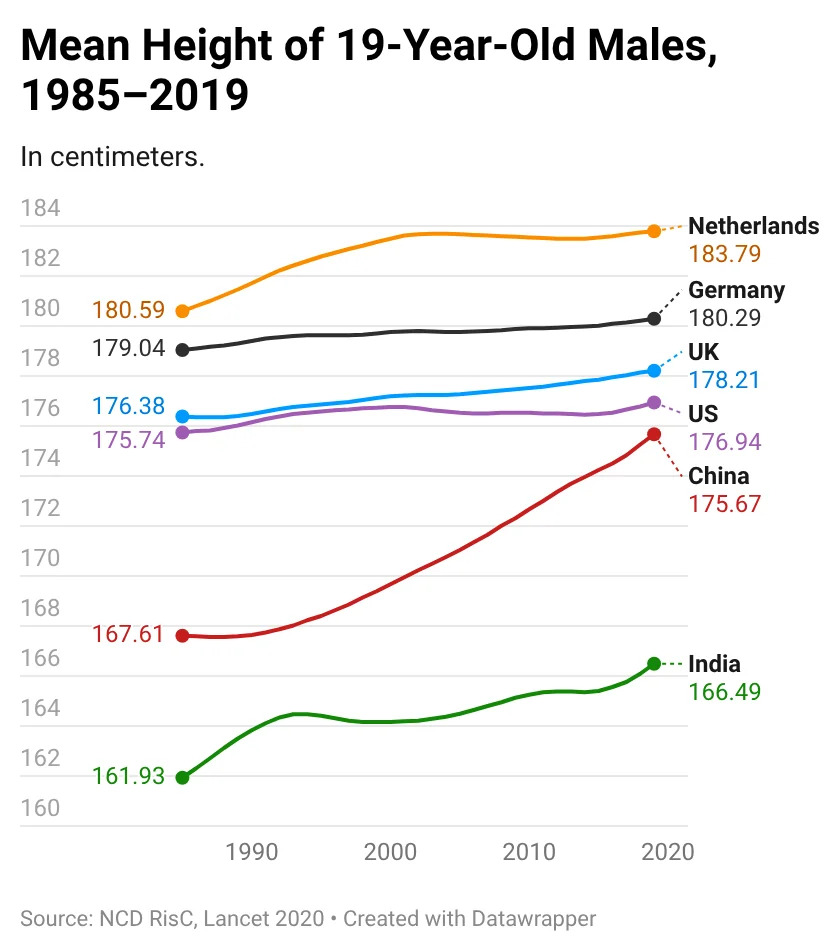
Over the past 34 years the average Chinese man became, on average, 3 inches taller than his grandfather.
But entire population can't rewrite its DNA in 35 years.
So what made them grow so fast? The answer might surprise you.
Mexicana llora porque se hizo autónoma en España.
Factura poco… y le meten 1.500-1.700 € extra cada trimestre solo de IVA + contribuciones.
Entre eso y la cuota de autónomos, le sale más barato cerrar: “España no es para emprendedores”, dice.
Two weeks without mobile internet improved mental health more than antidepressants and reversed roughly 10 years of attentional decline.
Screen time dropped 49% (314 to 161 min/day).
I'm lucky enough to have a great doctor and access to excellent Bay Area medical care. I've taken lots of standard screening tests over the years and have tried lots of "health tech" devices and tools.
With all this said, by far the most useful preventative medical advice that I've ever received has come from unleashing coding agents on my genome, having them investigate my specific mutations, and having them recommend specific follow-on tests and treatments.
Population averages are population averages, but we ourselves are not averages. For example, it turns out that I probably have a 30x(!) higher-than-average predisposition to melanoma. Fortunately, there are both specific supplements that help counteract the particular mutations I have, and of course I can significantly dial up my screening frequency. So, this is very useful to know.
I don't know exactly how much the analysis cost, but probably less than $100. Sequencing my genome cost a few hundred dollars.
(One often sees papers and articles claiming that models aren't very good at medical reasoning. These analyses are usually based on employing several-year-old models, which is a kind of ludicrous malpractice. It is true that you still have to carefully monitor the agents' reasoning, and they do on occasion jump to conclusions or skip steps, requiring some nudging and re-steering. But, overall, they are almost literally infinitely better for this kind of work than what one can otherwise obtain today.)
There are still lots of questions about how this will diffuse and get adopted, but it seems very clear that medical practice is about to improve enormously. Exciting times!
Stanford paid 35,000 people to quit Facebook and Instagram for 6 weeks
Depression dropped. Anxiety dropped. Happiness went up. Women under 25 on Instagram saw the biggest gains
That was 6 weeks. I'm going a full year.
Se terminó la fiesta de la IA "All You Can Eat"... desde 2022 vivimos en la ficción del subsidio de adopción: OpenAI, Anthropic, Gemini quemando caja para que te enamores del producto.
Como decian en Battlestar Galactica: “All of this has happened before, and it will all happen again.”
Porque "la tarifa plana nunca es plana" y los subsidios se terminan cuando hay un ganador o cuando la matemática no da... y aca creo que el "Agentic Workflow" mató el calculo.
El modelo de suscripción plana se basaba en la curva de un chat: pregunta -> respuesta. Un humano chateando no quiebra a nadie, pero un Agente (como Claude Code) corren loops, encadenan herramientas y ejecutan procesos sin preguntar u optimizar :)
Un solo usuario "power" haciendo tokenmaxxing puede quemar en un ciclo lo que pagan 200 usuarios casuales. Literalmente, un subsidio de 25 a 1. Los números no cierran para ninguna IPO.
En los ultimos 30 dias cambio la facturacion de todos los grandes (Anthropic pasa a modo consumo, OpenAI a transparencia tipo Azure/AWS/GCP, Github con el "overage") y se acabo la fiesta...
Encima te suben el precio con un uptime mediocre (98.95% en Claude). ¿Se puede construir un negocio serio con 94 veces más downtime que AWS? y esto lo vi en un chat con @DamianCatanzaro de @paywithamplify
Si yo hoy fuese emprendedor me preguntaria: ¿puedo construir un negocio sin que los grandes subsidien el costo de los tokens? y encima ¿puedo construir un negocio sin saber siquiera el SLA de los proveedores de IA?
Todo esto lo escribi con ejemplos y mas desarrollado en mi blog (@dfgonzalez lo vio antes que tenga tiempo de poner el tweet este :P)
https://t.co/NDkJCMIPCX
#AI #GenerativeAI #StartupEconomics #Tokenomics #CloudComputing
Llevo décadas contrubuyendo con la educación (https://t.co/9Nf2tt9Hkw, EducarChile) y enseñando en NYU y Columbia University lo que a veces me frustra es que el conocimiento existe, pero el acceso cuesta una fortuna.
En España un profesor particular para la EBAU cobra 30 a 60 euros la hora. En Argentina, una clase particular sigue siendo un gasto importante para la mayoría de las familias.
DeepTutor es un proyecto open source de la Universidad de Hong Kong que convierte tus propios materiales (libros, apuntes, PDFs) en un tutor personal. No es un chatbot genérico: trabaja con tu contenido, cita tus fuentes, genera exámenes adaptados a tu nivel, y todo corre en local. Tus datos no salen de tu ordenador.
Si estás preparando la EBAU, oposiciones, ingreso a la UBA o cualquier materia universitaria, esto te puede ahorrar cientos de euros o miles de pesos al mes. Funciona perfectamente con contenido en español. Más de 10.000 estrellas en GitHub, comunidad activa.
https://t.co/vjcyqlumLc
La educación personalizada por IA no va a reemplazar a un buen profesor. Pero sí va a hacer que la diferencia entre quien puede pagarse uno y quien no deje de ser determinante.
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
One of my favorite lessons I’ve learnt from working with smart people:
Action produces information. If you’re unsure of what to do, just do anything, even if it’s the wrong thing. This will give you information about what you should actually be doing.
Sounds simple on the surface - the hard part is making it part of your every day working process.
Descripción del hundimiento de Europa por parte de @BillAckman uno de los inversores más exitosos del mundo.
Europa está en camino de destruirse a sí misma.
Inmigración no controlada de millones de inmigrantes que agobian sus estados de bienestar, traen violencia y terrorismo a sus costas y se hacen cargo del gobierno local, una ciudad a la vez.
Las políticas anticapitalistas que dificultan que las empresas adapten su fuerza laboral a un entorno competitivo que cambia rápidamente y que se están acelerando debido a la IA.
Un entorno empresarial y un régimen fiscal que es antitético a las nuevas empresas.
La ausencia de cualquier progreso o innovación en IA y acceso limitado a la computación necesaria para competir.
Dependencia de la energía debido al movimiento verde en un momento en que la demanda de energía está aumentando rápidamente.
Y ahora, el abandono de los Estados Unidos cuando hemos pedido asistencia limitada, acceso a la base y derechos de sobrevuelo, en medio de nuestros esfuerzos para eliminar la amenaza nuclear y balística de Irán, que ya está dentro del alcance de Europa, después de haber invertido casi 200 mil millones de dólares en ayudar a Ucrania.
La OTAN está a punto de ser una tostada. La carga de defensa de Europa está a punto de aumentar masivamente mientras sus economías continúan cada vez más atrás.
En resumen, Europa necesita despertar antes de que sea demasiado tarde, y puede que sea demasiado tarde.