🚀 Introducing MDocAgent! 🧐📄
📚 Ever struggled with AI that can’t handle complex documents filled with text, images, tables, and figures?
💡 Enter MDocAgent 🧠🤖—a next-gen multi-modal multi-agent framework that revolutionizes document understanding!
#AI#DocQA#LLM#Agent
KV cache compression techniques
▪️KV caching (basic) – stores previously computed Keys and Values in memory and calculates attention only for new tokens.
▪️ Quantization – represents KV cache with fewer bits.
▪️ Low-rank decomposition – compresses the KV cache into smaller spaces.
▪️ Slim Attention – stores only Keys and recovers Values from them using math tricks.
▪️ XQuant – quantizes and stores only the layer input activations (X), and recalculates Keys and Values from X on the fly during inference.
Read about XQuant method (the newest one) and other methods with their limitations in this overview: https://t.co/6viuCwd5bu
🤯 There is no AI, at present, that can solve this problem. Not ChatGPT Pro, not Grok Expert, not Gemini, not anything.
What’s more, there are very few humans in the planet who can solve it. And there is NO decent explanation available on the internet.
Good luck :)
OpenAI, Google, and Anthropic just published guides on:
• Prompt engineering
• Building agents
• AI in business
• 601 AI use cases
9 of the best guides you can't miss:
The best fine-tuning guide you'll find on arXiv this year.
Covers:
> NLP basics
> PEFT/LoRA/QLoRA techniques
> Mixture of Experts
> Seven-stage fine-tuning pipeline
this is the most comprehensive and in-depth blog to understand vLLM. must read if you are into inference and ML systems and also helpful for beginners who want to contribute to vLLM. thank you aleksa!!
This Resume has an ATS score of more than 88🤯
This Resume helped many in getting an interview calls from companies like Google, Microsoft, Amazon, and many more. 💼
I have personally used this single-column resume in my job hunting and got amazing results
I am sharing the exact similar editable ATS Friendly Resumes templates!
To get it:
1. Follow me @krishnasagrawal
(So that I can DM)
2. Like & Repost
3. Reply "Resume"
Follow me so I will dm immediately 💯
this book actually exists for free, “the little book of deep learning” by @francoisfleuret. best to refresh your mind about DL basics:
> foundations of machine learning
> how models train
> common layers (dropout, pooling…)
> basic intro to LLMs
actually optimized for mobile.
I think everyone should watch @Karpathy's latest video on how he uses LLMs, even those who think AI is already a big part of their lives because:
1. One of the best minds in AI is spending time showing how he uses AI personally rather he could have spent his time building AGI , that's one of the reason to watch & learn
2. @karpathy clearly explains a first-principles approach to leveraging these tools & the visual explanation really helps you build a mental model for specific use cases.
below is short high level summary & some note's that I had taken from the video
- karpathy takes us through the practical applications of various tools with lots of examples & different settings one can play around with while using these tools
- he starts off with -> to get a general Idea about what are the best models at anytime , one can always look that up In https://t.co/WuMWeCp9u7 & @scale_AI seal leaderboard ( https://t.co/HOSlEwPr0d)
- he starts with @OpenAI's ChatGPT ( the OG & the most feature rich AI tool that Is available currently & the one that has been there for the longer time) which started the era of where one can give a text Input and get a text output via an Interface.
- my fav part was he explaining from first principles what exactly is happening under the hood when we Interact with Chatgpt - it's amazing how he visually thinks about this & presents It 😅
- difference between a pre-training stage vs the post-training stage (🙂) which is the final model that we get to interact with , basically a fine tuned version of the base model via SFT , RLH or RL -> all of this compressed Into a single zip file
- one cannot directly use the base model (pre-trained) since in this stage we optimise the model to predict the next token In the sequence , but during the post-training we can actually use this for real world applications as this model can now act as an assistant basically combining loads of knowledge with some style ,form, personality & yet this knowledge has a cut-off date.
Google presents PlanGEN for complex planning and reasoning.
PlanGEN is a multi-agent framework designed to enhance planning and reasoning in LLMs through constraint-guided iterative verification and adaptive algorithm selection.
Key insights include:
Constraint-Guided Verification for Planning – PlanGEN integrates three agents: (1) a constraint agent that extracts problem-specific constraints, (2) a verification agent that evaluates plan quality and assigns scores, and (3) a selection agent that dynamically chooses the best inference algorithm based on instance complexity.
Improving Inference-Time Algorithms – PlanGEN enhances existing reasoning frameworks like Best of N, Tree-of-Thought (ToT), and REBASE by iteratively refining outputs through constraint validation.
Adaptive Algorithm Selection – Using a modified Upper Confidence Bound (UCB) policy, the selection agent optimally assigns problem instances to inference algorithms based on performance history and complexity.
State-of-the-Art Performance – PlanGEN achieves +8% improvement on NATURAL PLAN, +4% on OlympiadBench, +7% on DocFinQA, and +1% on GPQA, surpassing standard multi-agent baselines.
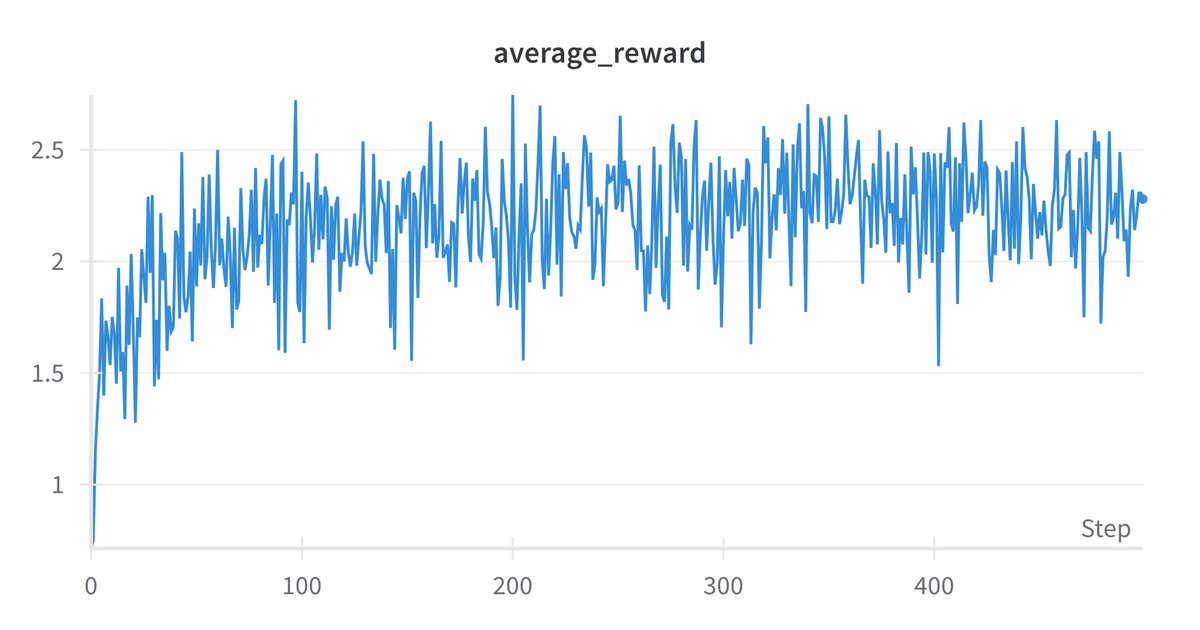
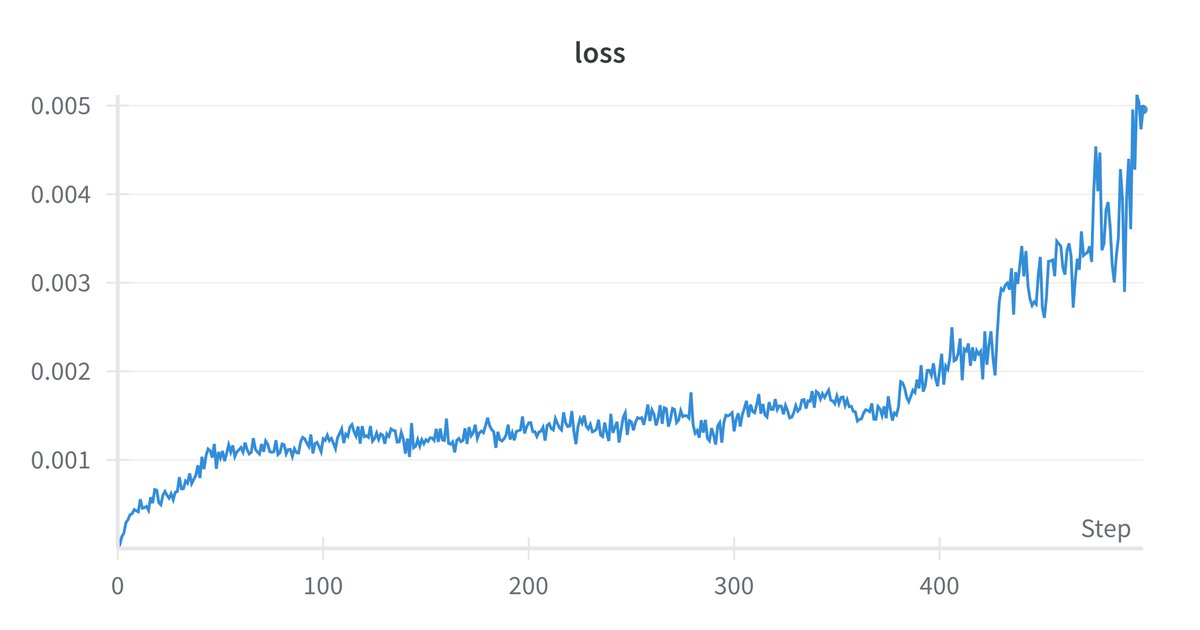
I just published a detailed tutorial on how to code GRPO (the reinforcement learning algorithm used to train DeepSeek R1) from scratch and how to finetune the Qwen-2.5-1.5B-Instruct model using GRPO to solve 90% of the problems from the GSM8K dataset of high-quality, linguistically diverse grade school math problems created by human problem writers.
The tutorial also shows how to use PyTorch's DataParallel to distribute the training across several GPUs:
https://t.co/hstMLdckBB
To reproduce the DataParallel code, you will need a node with at least 2 GPUs with 80GB of VRAM or more (8 GPUs recommended). If you purchased my The Hundred-Page Language Models Book, you can claim $150 in free cloud GPU credits on @LambdaAPI by sending me proof of purchase at [email protected]. With these credits, you can run an 8xA100 node on Lambda. I adjusted the tutorial for running on this node.
Happy hacking!
The biggest startup opportunities right now:
biggest b2c: solving loneliness
biggest b2b: vertical ai agents
biggest saas: pay-per-result saas
biggest consumer social: social apps designed for friend-to-friend communication, not creators
biggest e-commerce: ai personal shoppers
biggest creator: tools that make creators go viral or monetize more efficiently
biggest edtech: personalized learning
biggest health: gut health
biggest wellness: anti-microplastic products
biggest overlooked: elder tech
LLMs Know More Than They Show: On the Intrinsic Representation of LLM Hallucinations
Overview:
LLMs exhibit errors known as "hallucinations," but their internal states hold more truthfulness information than previously understood.
The study finds that this information is concentrated in specific tokens, improving error detection, though these detectors don't generalize well across datasets, indicating complexity in truthfulness encoding.
Additionally, internal representations can predict likely error types, aiding in tailored mitigation efforts.
Despite possibly encoding correct answers internally, LLMs might still produce incorrect outputs, highlighting a gap between internal encoding and performance.
These insights enhance understanding of LLM errors and guide future error analysis and mitigation strategies.
Paper:
https://t.co/1bwSMNqdNp