I'm excited to go to my first #CloudNative#Stockholm meetup tonight! Looking forward to meeting some of the local #PlatformEngineering, #SRE, and AI infra folks and hearing what people are working on. If you're going, please say hello.
https://t.co/WlXZFOa8ky
Today we are announcing a $50 million extension of our Series D financing.
The extension adds @Atlassian and nVentures (@nvidia's venture capital arm) as corporate investors, alongside new financial investors, including Airtree, Barclays, Geodesic Capital, Insight Partners, Liberty Global Partners and Nikesh Arora.
We’re entering a new phase for enterprise AI.
Foundation models are improving rapidly, but the real breakthrough is in how they’re applied: AI that doesn't just assist, but executes autonomously with the right level of human oversight.
That’s what we’re building towards, a full agentic operating system for legal work.
Full story: https://t.co/VOh6vcNoEB
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
I want to take a moment to recognize a gravity-defying achievement by the entire @WeAreLegora team.
We have grown from $1M to $100M in annual recurring revenue in just under 18 months.
In this time, we've grown into a truly global company with over 400 colleagues - and built the platform where legal work happens. Powering more than 1,000 teams worldwide.
It is all about the people, and I couldn’t be prouder of the Legora team and thankful to our customers and partners.
This achievement is as much yours as it is ours.
Legal education is about to change.
Today, we’re launching the Legal AI Scholars Program in collaboration with leading law schools.
AI is becoming a core part of how legal work gets done. Graduates need to understand how to use it effectively, responsibly, and in real workflows.
Together with faculty, we’re developing a curriculum focused on applying AI to legal tasks, understanding its strengths and limitations, and developing the judgment required to use it well.
The program is already rolling out across select schools, with more to follow in key jurisdictions over the coming months.
I can't wait to help shape a generation of lawyers better equipped to navigate how the profession is changing together with all of our great partners.
Full story:
https://t.co/JlFnnDpgmG
Software horror: litellm PyPI supply chain attack.
Simple `pip install litellm` was enough to exfiltrate SSH keys, AWS/GCP/Azure creds, Kubernetes configs, git credentials, env vars (all your API keys), shell history, crypto wallets, SSL private keys, CI/CD secrets, database passwords.
LiteLLM itself has 97 million downloads per month which is already terrible, but much worse, the contagion spreads to any project that depends on litellm. For example, if you did `pip install dspy` (which depended on litellm>=1.64.0), you'd also be pwnd. Same for any other large project that depended on litellm.
Afaict the poisoned version was up for only less than ~1 hour. The attack had a bug which led to its discovery - Callum McMahon was using an MCP plugin inside Cursor that pulled in litellm as a transitive dependency. When litellm 1.82.8 installed, their machine ran out of RAM and crashed. So if the attacker didn't vibe code this attack it could have been undetected for many days or weeks.
Supply chain attacks like this are basically the scariest thing imaginable in modern software. Every time you install any depedency you could be pulling in a poisoned package anywhere deep inside its entire depedency tree. This is especially risky with large projects that might have lots and lots of dependencies. The credentials that do get stolen in each attack can then be used to take over more accounts and compromise more packages.
Classical software engineering would have you believe that dependencies are good (we're building pyramids from bricks), but imo this has to be re-evaluated, and it's why I've been so growingly averse to them, preferring to use LLMs to "yoink" functionality when it's simple enough and possible.
This feels like physical product design's ChatGPT moment.
This team just ran an autonomous agent against the entire chip design process: 219-word spec in, tape-out-ready silicon layout out, 12 hours later. The agent ran continuously against a simulator, found its own bugs, rewrote its own pipeline, and iterated to a working CPU!
Chip design costs well over $400M and takes up to 9 years. Not because writing hardware code is hard (it is actually brutally hard) but because a respin costs 10 of millions. So teams spend more than half their total budget just verifying the design is correct before a single transistor is placed. That cost structure is why most chip designs never get built.
Entire product categories that were previously too low-volume to justify a tape-out are now buildable.
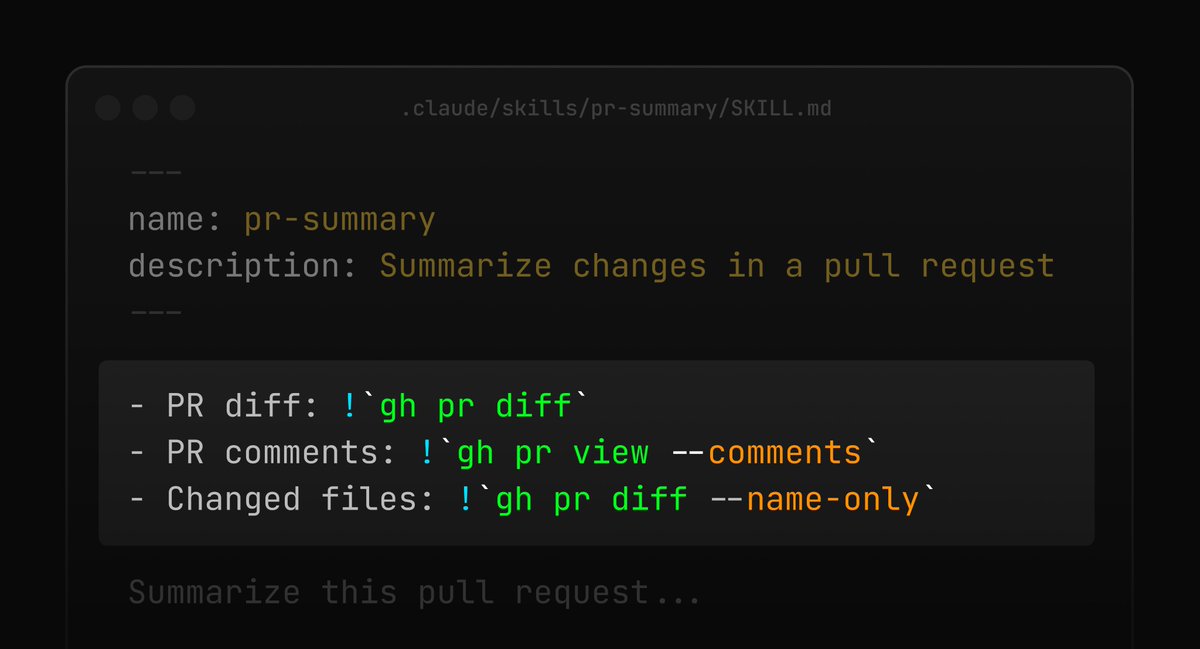
if your skill depends on dynamic content, you can embed !`command` in your SKILL.md to inject shell output directly into the prompt
Claude Code runs it when the skill is invoked and swaps the placeholder inline, the model only sees the result!
I have been dreaming of this day for a long time.
Arena is now a book publisher, and our first volume, "Silicon" is open for preorders.
It's quite unlike anything you've seen: a coffee table book capturing the ecstatic beauty of silicon technology. https://t.co/R0JLQx9Fiq
@simonw “He fed the paper to Claude Code and used a variant of Andrej Karpathy's autoresearch pattern to have Claude run 90 experiments and produce MLX Objective-C and Metal code that ran the model as efficiently as possible.” I love how quickly this technique is growing
$550M Series D led by @Accel. $5.55B valuation.
One year into our U.S. expansion, we’re doubling down: accelerating across America and building AI with the lawyers who use it every day.
Grateful to our customers, partners, and team.
More: https://t.co/1oWW2x9IkG
Today, we announced our acquisition of Walter AI.
They’ve built agent-native systems alongside lawyers that handle real workflows.
We share the same blueprint for the future - and I'm excited to welcome the Walter team to @WeAreLegora!
https://t.co/rnjAW2kljo
Protecting you online — it’s in our DNA. 💙
Today, we announce our Series C and our vision for the future of 1Password, to bring human-centric security to everyone: https://t.co/Ql0LxQ0LCF