Surprised by the loss of LLaMA-7B still going down after 1 trillion tokens?
In a new blogpost, I explain why you shouldn't be and argue we haven't reached the limit of the recent trend of training smaller LLMs for longer:
https://t.co/E26sli9xTq
Analysis in 🧵👇
We're hiring!
Over the past few months, we’ve been building up our agent tech stack. Now we're ready to scale up.
If you live and breathe agentic systems and how they are going to impact work—DM me. We just opened a few engineering and product roles, see https://t.co/cIa1xMQfEG
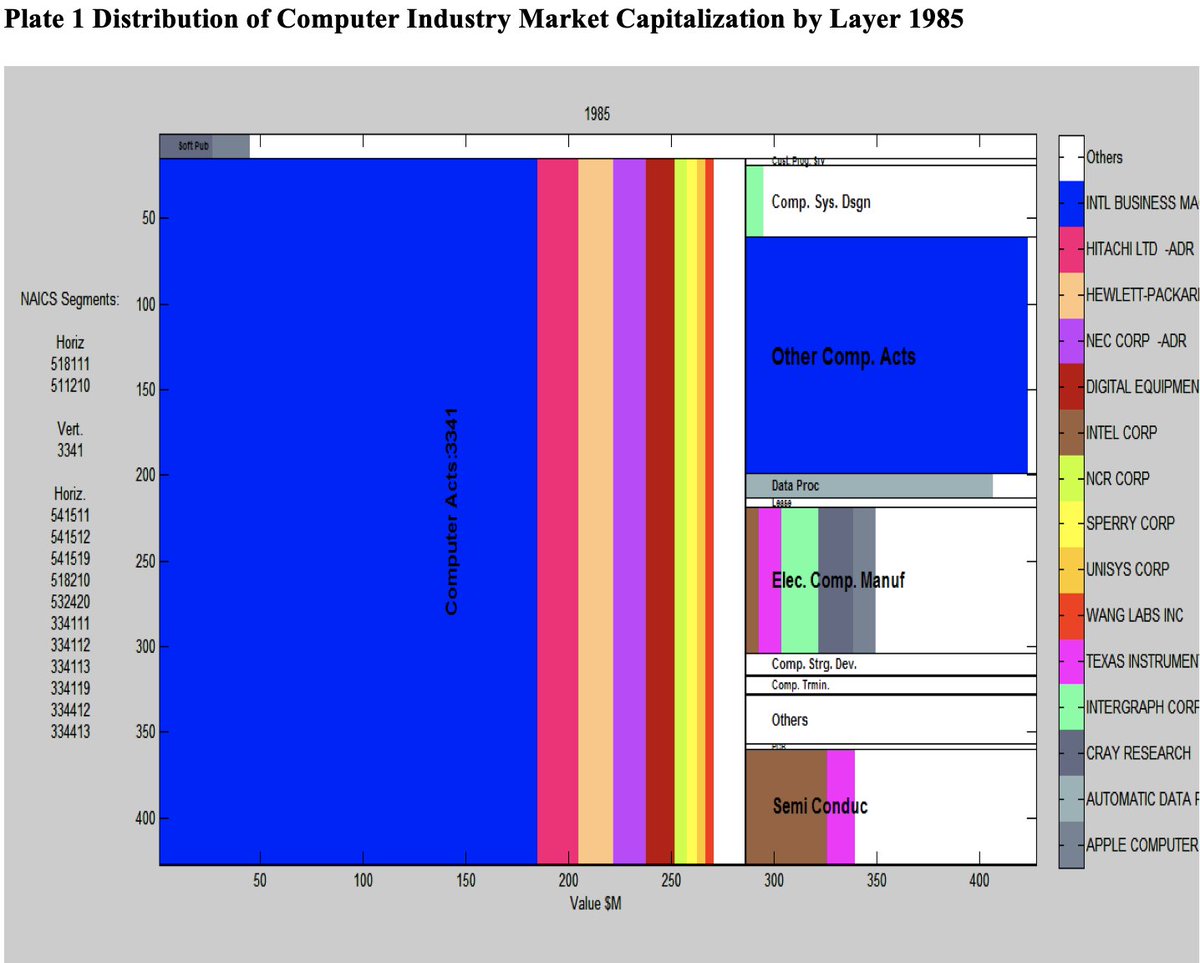
The microprocessor's invention in the mid 80s shifted the computer industry from a vertical to a more horizontal stack.
It was a METAMORPHOSIS.
The same transition is currently underway with the GenAI revolution. 🧵
Introducing 🌸BigCodeBench: Benchmarking Large Language Models on Solving Practical and Challenging Programming Tasks!
BigCodeBench goes beyond simple evals like HumanEval and MBPP and tests LLMs on more realistic and challenging coding tasks.
We are (finally) releasing the 🍷 FineWeb technical report!
In it, we detail and explain every processing decision we took, and we also introduce our newest dataset: 📚 FineWeb-Edu, a (web only) subset of FW filtered for high educational content.
Link: https://t.co/MRsc8Q5K9q
It’s been a year since the release of @BigCodeProject’s 💫 StarCoder models and paper: May the source be with you! Join us as we celebrate the anniversary, and share what you’ve done using #StarCoder. Read how StarCoder has helped ServiceNow developers: https://t.co/tICamMY7OQ
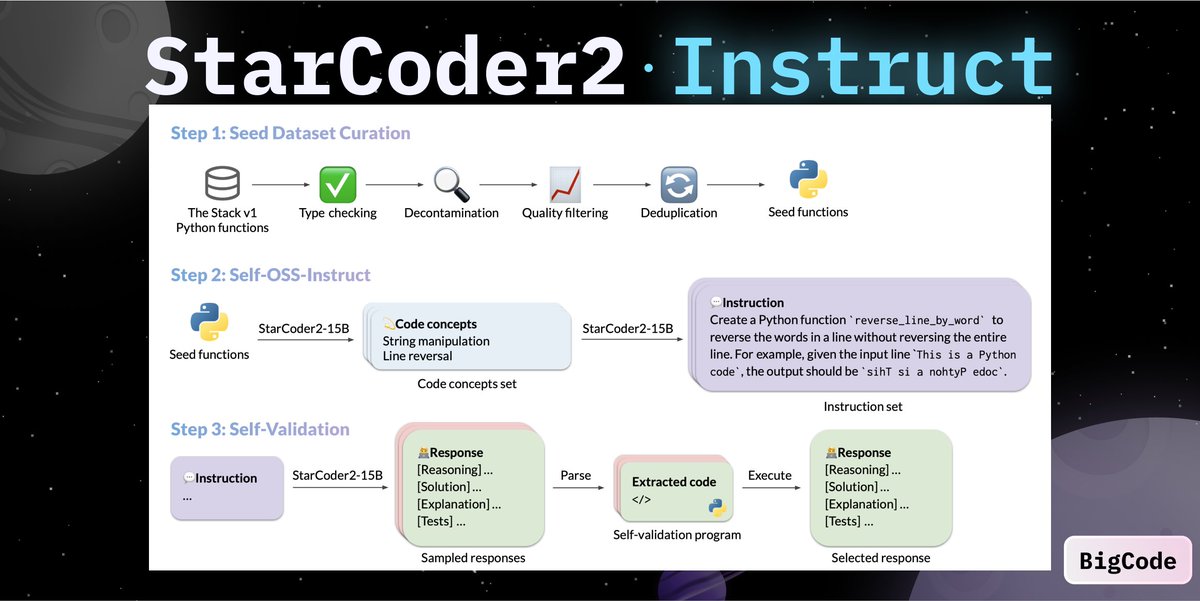
Self-Instruct for CodeLLMs! 👀 @BigCodeProject released a new StarCoder2-Instruct, the first entirely self-aligned code LLM trained with a transparent and permissive pipeline. 🧑🏻💻 It used itself to generate thousands of instruction-response pairs, which were then used to fine-tune—achieving 72.6 on HumanEval without relying on human annotations. 🤯
Implementation
1️⃣ Collect Seed Code Snippets, e.g., functions with docstrings.
2️⃣ Apply type checking, decontamination (benchmarks), Quality Filtering & Near-Deduplication
3️⃣ Employ in-context learning to self-generate coding tasks from these snippets.
4️⃣ For each instruction, generate answers and tests using in-context learning.
5️⃣ Execute these tests in a sandbox environment and select responses that pass for training.
6️⃣ Create a Training Dataset with the validated responses
7️⃣ Fine-Tune StarCoder2-15B on the generated self-instruct dataset
Insights
🧮 15B parameter version with 8192 context
🔓 Fully open-source datasets and pipeline for distillation
📝 Fully self-aligned without human annotation
🏆 Outperforms CodeLlama-70B-Instruct (72.0) and GPT-4 (march) on HumanEval
🥇 Outperforming other open Models like Grok-1, Command-R+, and DBRX, and closely matching Snowflake Arctic 480B and Mixtral-8x22B-Instruct
Test-of-time awards should maybe be handed out after a longer period of time but in my opinion this blog post (and the following) were incredibly prescient, and about one year later, everybody in LLMs is doing exactly what it suggested
@BG2Pod@altcap@bgurley@sundeep Great pod! Small correction @sundeep : chinchilla is not considered the point of diminishing returns but referred to as the compute-optimal point, the best model for a given FLOP budget. See my blogpost from last year: https://t.co/E26sli903S
Took some time to reflect on the past 1+year of the @BigCodeProject: Here are a few of my learnings from leading it during this time and some ingredients I think are important for a successful open collaboration in ML.
What is BigCode?
BigCode is an open scientific collaboration working on the responsible development and use of large language models for code. It is hosted by @ServiceNowRSRCH and @huggingface and recently also got additional support from @nvidia.
For more info see: https://t.co/wOUYiev9ns
Impact
The collaboration started in October 2022 and these are some of the most impactful outcomes the project delivered since then:
1⃣ StarCoder: the model is one of the most transparently built modles (e.g as measured by the Stanford Transparency index) and has been used widely. For example ServiceNow has successfully integrated it across their platform leading to a significant increase in valuation.
2⃣ The Stack: In my opinion the most impactful artefact of BigCode. Since we released it every code LLM and most general LLMs as well have use it (even if they don't publicly say it 🙃). It enables many to pretrain, fine-tune and build on top of it.
3⃣ Collaboration itself: I think BigCode showed that you can build great models and datasets in a transparent and responsible fashion. Some aspects of the collaboration are now serving as a blueprint for some similar projects - hopefully there will be more open research!
Community
BigCode is organised as an open collaboration with now over 1k people on our Slack channel. While many people are mostly watching, there are around 40-50 active people contributing on some level. BigCode was on purpose a bit less democratic than BigScience which helped to reduce noise and coordinate clearer. Also not everybody can contribute the same amount of hours and some people need a bit more assistance, but I think that's fine. Some people appeared throughout the collaboration while some others phased out. Overall I think it worked quite well.
Core team
Although the community is quite big, the core work has been done by maybe 2-3 full time people both at Hugging Face and at ServiceNow with the community helping out on specific tasks. E.g. dataset inspection and model evaluation was largely done by community members. I think 3-5 people is a great size even for a project at this scale and allows being very align and thus move fast.
Transparency
There is a bit of tension about being fully open and transparent. Other organisations can see your timeline and move their releases accordingly while you don’t have much visibility in return. This happened for both StarCoder releases and is quite stressful. Trying to keep releases/timelines a bit opaque might be a good idea.
On the other hand building something with controversial aspects in the open as a community effort helps with scrutiny. Overall people look at it already with a more positive view than other similar corporate project.
Collaborations
Collaborations even with large companies can work out! My learning is that two things are essential for this:
1⃣ Having a very aligned single point of contact that can move things forward internally. Doing this from the outside is very hard.
2⃣ Top-down support: things can move slower in big companies. Having support from the top helps pushing things forward for example if something needs to be pushed through legal or fast decisions need to be made.
Focus + motivation
There are many interesting things to work on and people bring a wide range of ideas to the table. It's important to go through the sometimes painful process to find focus for the collaboration and work on delivering concrete artefacts.
The fuel of the collaboration is traction: the more exciting things are released the more people join and the higher the motivation of the team to keep pushing and build more. Working on concrete milestones that can be released helps a lot. We did this with The Stack and SantaCoder which were stepping stones towards StarCoder.
Takeaways
➡️ Small, aligned teams can build great things fast.
➡️ Building datasets is long term more impactful than building models, but you still need to prove your dataset is good, usually by training a good model 🙂
➡️ Collaborations with other organizations/companies can work well, if there’s a lead pushing things forward on their side with top down support. Otherwise they can turn painful quickly.
➡️ Building in the open has cons and pros, striking the right balance is important.
➡️ Frequently releasing intermediate artefacts is better than just releasing big things and removes a bit the pressure from big releases.
Of course @BigCodeProject wasn't the first open collaboration and follows in big footsteps with projects run by for example @AiEleuther, @BigscienceW, @laion_ai, @CohereForAI and @allen_ai.
Overall it has been a great pleasure working on @BigCodeProject and I hope that there will be more open collaborations in ML as I think working on one of the most impactful technologies openly is important!
Introducing: StarCoder2 and The Stack v2 ⭐️
StarCoder2 is trained with a 16k token context and repo-level information for 4T+ tokens. All built on The Stack v2 - the largest code dataset with 900B+ tokens.
All code, data and models are fully open!
https://t.co/fM7GinxJBd
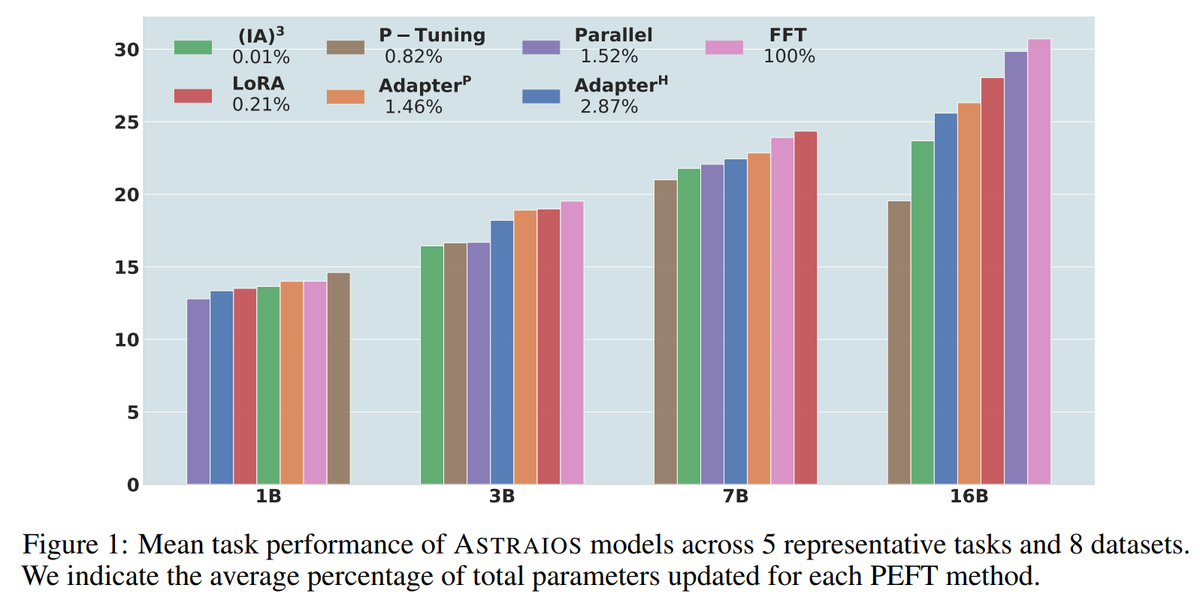
Instruction Tuning Code LLMs Using #PEFT methods? Introducing 🌠
✨Astraios Model Suite: A suite of 28 #StarCoder instruct-tuned using #OctoPack, 7 tuning methods & 4 model sizes, and up to 16B parameters.
📝Extensive Evaluation: 5 tasks & 8 datasets in both Code Comprehension 🧠 & Generation ✍️.
🔍Further Analysis: Model Robustness 🛡️ & Code Security 🔒
📜https://t.co/zZC6HszNSn
💻https://t.co/xqr9YxPhkg
1/9
Exciting times: we are working on the next generation of StarCoder trained on a new dataset! 🚀
If you would like to have your code excluded from the training run you can check if your data is in the dataset and follow the link to opt-out:
https://t.co/sLKdt0nLnP
First promising results for pre-training with related documents in the context window, nicely addressing the data issue I explained in my last blog post.
Looks de-risked enough to go into llama-3.
https://t.co/vo1gFG8H5K
@harmdevries77 raises a key issue: the lack of long pretraining data (<5% web docs exceed 2k tokens) poses challenges for pretraining LMs with long context windows. In-Context Pretraining offers a scalable solution for creating meaningful long contexts https://t.co/PwY5wfUuRa