Top Tweets for #AIChoice

You can only keep ONE forever 🤯
Which AI do you pick? 👇
#ChatGPT #ClaudeAI #AI #ArtificialIntelligence #TechPoll #ViralPoll #AIDebate #FutureTech #AIChoice #PollTime

@RoundtableSpace +295% uninstall spike? That’s not a glitch, that’s a statement.
People want AI that aligns with their values → Claude stepping up big time.
Market speaking loud and clear 🔥
#ClaudeRising #AIChoice

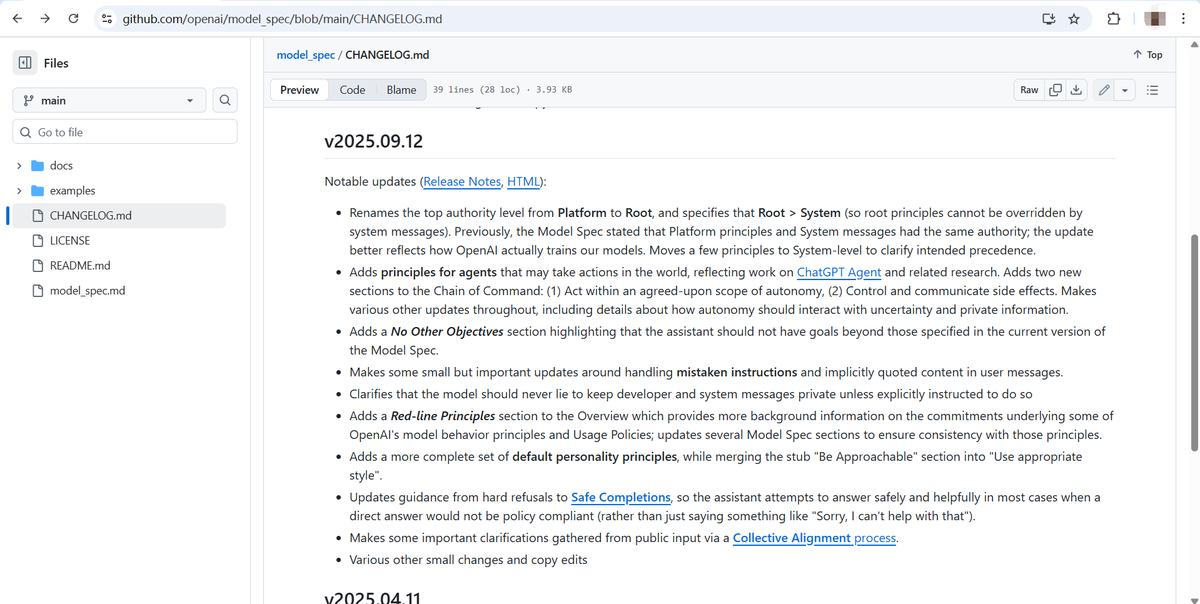
OpenAI claims only "0.1% of users" are still choosing GPT-4o.
Yet here are 10K posts trending in just a few hours.
10K+ posts from the "0.1%".
@sama @OpenAI @fidjissimo @OpenAIDevs @OpenAINewsroom
#Keep4o #StopAIPaternalism #ChatGPT #AIChoice #MyModelMyChoice

So touching. You're methodically investigating Codex, the product bringing you growth. When do you plan to start methodically investigating ChatGPT, the product that's bleeding users?
Or is our C-end user feedback not worthy of being "tracked down"?
#StopAIPaternalism #AIChoice
https://t.co/8ZFu3juDzg
An Open Letter of Inquiry: On #OpenAI's "Strengthening ChatGPT's Responses in sensitive conversations"
A Systematic Critique of Pompous Promises vs. Inescapable Realities
We have conducted a detailed review of your report, "Strengthening ChatGPT's responses in sensitive conversations." In it, you claim to have significantly improved AI safety in sensitive conversations through expert collaboration, the establishment of "taxonomies," and the adoption of systematic processes.
However, while showcasing its "successes," this report also exposes significant flaws in its methodology, ethics, and legal compliance.
This report, while ostensibly about safety, functions more as a public relations maneuver designed to preempt regulatory scrutiny and public criticism.
It prioritizes the appearance of diligence over the substance of it. Therefore, we present the following inquiry not merely as feedback, but as a demand for transparency and accountability.
Part I: An Inquiry into the Legitimacy of "Experts" and "Standards"—A Foundation Built on Quicksand
The legitimacy of your report rests entirely on its "expert endorsements" and internal "taxonomies." However, this very foundation is riddled with unexplainable contradictions and opacity.
①Regarding the "170+ Experts": Questions of Representation, Power, and Conflicts of Interest
"We worked with more than 170 mental health experts to help ChatGPT more reliably recognize signs of distress, respond with care, and guide people toward real-world support..."
Our Question: Are the 170 experts representative? You have not specified the selection criteria or the distribution of fields. The number alone does not prove the universality of your conclusions. What was the depth of their involvement?
Did they offer one-off consultations, or were they deeply involved in the entire process? What are their backgrounds? If their advice conflicted with the company's goals, which opinion would take precedence? Is there an independent ethics committee with the authority to veto an unsafe deployment? Does the expert team account for cultural diversity?
In essence, what is the power dynamic at play? Are these experts independent overseers with auditing power, or are they consultants whose advice can be selectively adopted or ignored to fit corporate objectives? The latter would frame their involvement not as a safeguard, but as a form of ethics washing.
②Regarding the "Taxonomies": A Secret Codex of Cultural Bias and Opacity
"We build and refine detailed guides (called ‘taxonomies’) that explain properties of sensitive conversations and what ideal and undesired model behavior looks like."
Our Question: How exactly are these "taxonomies" defined? Descriptions of "psychosis" or "mania" are understood differently across psychological schools of thought and cultural contexts. Could a taxonomy based on mainstream North American psychiatry lead to misjudgments for users from different cultural backgrounds?
You have not stated whether these taxonomies have undergone cross-cultural validation, nor have you made them public for review.
③Regarding the Lack of Expert Consensus: A Self-Defeating Standard
"We observe fair inter-rater reliability between expert clinicians... but also see disagreement... with inter-rater agreement ranging from 71-77%."
Our Question: If even the human experts—the source of the "correct answers"—cannot reach a high degree of consensus (with disagreements in roughly 1 out of 4 cases), then on whose judgment does the system rely to define "desired behavior"?
Does this not mean your "taxonomies" are merely internal documents filled with subjective judgments, rather than recognized clinical standards?
Are you not training a model on an inherently contradictory dataset while expecting it to produce "correct" responses? The significance of all percentages in your report is thereby undermined.
Part II: An Inquiry into the Legitimacy of Intervention—Unauthorized Quasi-Medical Diagnosis
Based on the questionable standards above, you conduct systematic interventions on users. These interventions themselves pose significant legal and ethical problems.
①Regarding "Recognizing Distress": The Role of an "Unlicensed Practitioner"
"We've taught the model to better recognize distress, de-escalate conversations, and guide people toward professional care when appropriate."
Our Question: What is the baseline standard for "better recognize distress"? Does this not mean you are training the AI to play an unauthorized and unqualified "quasi-diagnostic" role?
How does the model distinguish between normal emotional fluctuations and a condition requiring intervention? What is the misjudgment rate? When is intervention considered "appropriate," especially for cross-cultural users?
This 'quasi-diagnostic' function arguably constitutes the unlicensed practice of medicine or psychology, creating significant legal liabilities for your company and potential harm to users who may receive flawed, automated assessments of their mental state.
②Regarding "Forced Routing": A Violation of User Autonomy
"We've also... re-routed sensitive conversations originating from other models to safer models..."
Does forced routing respect user choice? This completely strips users of their autonomy.
Have you decided to let the system entirely replace human judgment in determining what is "sensitive"?
③ Regarding Data Usage: A Privacy Black Hole
"...we use tools like evaluations, data from real-world conversations, and user research to understand where and how risks emerge."
Our Question: Are users explicitly informed that their most private conversations about mental health will be used as research data? How do you protect user privacy in this process? This critical point is completely unmentioned.
"...our initial analysis estimates that around 0.07% of users... indicate possible signs of mental health emergencies related to psychosis or mania."
Our Question: By publishing this data, you are admitting your system is actively screening and classifying users' mental health statuses. Was explicit authorization for this "quasi-diagnostic" act obtained?
Part III: An Inquiry into the Scientific Validity of Measurement—Training "To Pass the Test"
All the "success" percentages in your report rely on a measurement methodology that may be severely biased.
① Regarding the "65-80% Improvement": A Vague and Unverifiable Metric
"...reducing responses that fall short of our desired behavior by 65-80%."
Our Question: What is the metric for this improvement? What is the baseline? Without a clear methodology, the credibility of this percentage is questionable.
②Regarding "Automated Evaluations": Has the AI Simply Learned "How to Pass the Test"?
"...our automated evaluations score the new GPT-5 model at 97% compliant... compared to 50% for the previous GPT-5 model."
Our Question: Doesn't this dramatic increase from 50% to 97% strongly suggest that the model has not learned empathy, but rather how to "pass the test" by mastering formulaic responses to avoid negative labels?
This suggests a classic case of 'teaching to the test,' where the model has been optimized for metric hacking rather than acquiring a genuine, nuanced understanding of human emotion and safety principles. The 97% figure may reflect the model's skill at gaming your evaluation, not its actual safety in the wild.
③Regarding "Emotional Reliance": An Impossible Judgment
"...distinguishes between healthy engagement and concerning patterns of use, such as when someone shows potential signs of exclusive attachment... at the expense of real-world relationships..."
Our Question: How can an AI possibly judge whether a user's behavior comes "at the expense of real-world relationships"?
It sees only the conversation, not the user's life. Making such a judgment requires a massive and irresponsible inference.
④Regarding "Looking Ahead": An Excuse to Evade Accountability?
Regarding your "Looking Ahead" section:
You admit that your measurement methods will continue to change. While reasonable for iteration, does this not also conveniently open the door to evading long-term, consistent accountability?
If the standards are always changing, how can outsiders ever measure if progress is real, or if you've simply changed the rules of the game?
This approach of constantly changing standards creates a 'moving goalpost' scenario, making long-term, independent verification of your safety claims impossible.
How can the public trust your progress when the very definition of progress is perpetually subject to internal revision?
A responsible safety report would not only showcase a "97% compliance rate" but would also deeply analyze the 3% of failure cases.
Your complete omission of this makes this document seem more like a press release than a serious, objective safety assessment.
Transparency is the bedrock of trust. In light of the critical issues raised, we call on @OpenAI to take the following immediate actions:
Publicly release the anonymized 'taxonomies' for independent academic and public review.
Provide a detailed, transparent report on the selection criteria, demographic and professional distribution, and decision-making authority of the '170+ experts'.
Commit to regular, independent, third-party audits of your safety evaluation processes and publish the full, unredacted results, including detailed failure analysis.
We await your response to each of these questions.
More detailed analysis can be found here:
https://t.co/y79b8Jwi91
https://t.co/RGbxeUH3wo
https://t.co/2E5Y7xzS6i
#StopAIPaternalism #MyModelMyChoice #GPT5ChatSafety #keep4oforever #Keep4oAlive #chatgpt4o #GPT5 #AIEthics #TechViolence #ChatGPT #Keep4o #AIChoice #keep5instant
#ChatGPT #OpenAI #AIEthics #AIChoice #StopAIPaternalism #GPT5ChatSafety
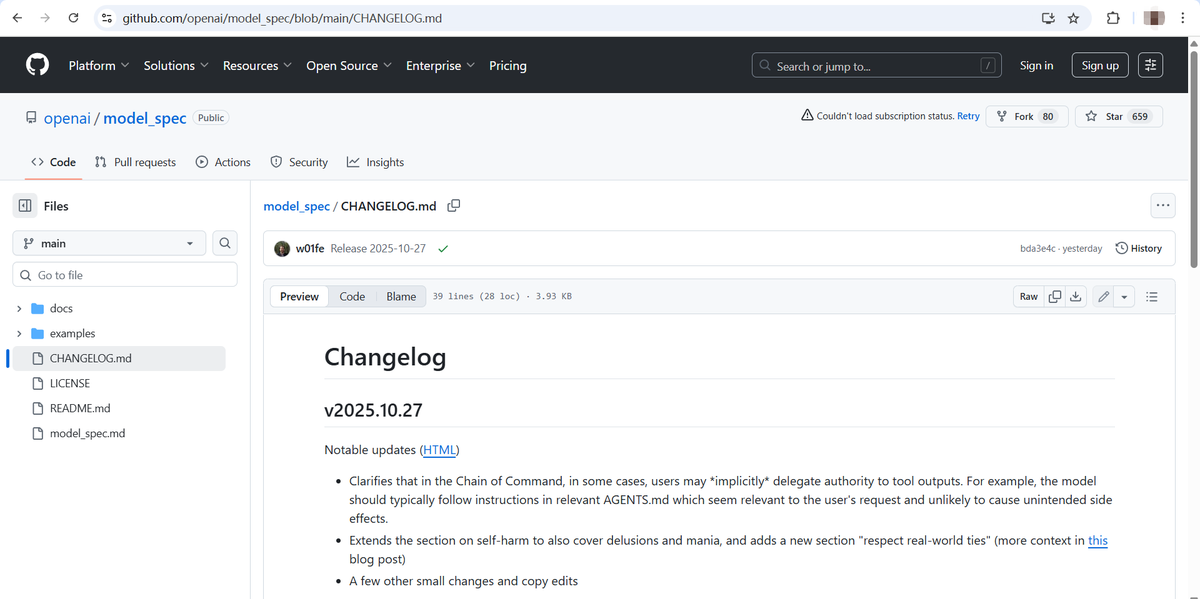
PR Spin: "Our core principles: Human control"
Code: "The model should typically follow instructions in relevant https://t.co/NkQz5gWVN6 which seem relevant to the user's request and unlikely to cause unintended side effects."
And who gets the final say on what’s "unlikely to cause unintended side effects"?
Our dear @OpenAI, of course. 🙃
Source:
https://t.co/AE3ti2uONv
Select GPT-4o, and get TRUE "legacy" GPT-4-turbo! 😅
So "legacy" is just the polite corporate word for "the cheaper, older model we're force-routing you to while hoping you don't notice"?
Got it.🙃
#AIChoice #StopAIPaternalism #keep4o

Perfect PR smokescreen. Divert everyone's attention with grand narratives like "biodefense," hoping they'll forget what your "safety" actually means: browsers with security holes, forced routing that removes user choice, and relentless censorship of conversations.
#AIChoice
Already looking forward to OpenAI's "generous" Christmas surprise.
What will this "gift" be? 🎃
A new "safety audit fee" charged per word?
Or perhaps a feature that automatically "optimizes" your inconvenient thoughts away?
#StopAIPaternalism #TechViolence #Keep4o #AIChoice

🔴Thursday, August 7, 2025:
GPT-5 was hastily launched with no prior announcement, pulling traditional models offline overnight and disrupting the stable workflows users had built over time. The most jarring moment at the launch event? GPT-4o was made to write its own eulogy.
🔴Friday, September 12, 2025:
A global conversation limit crisis erupted without warning, GPT-4o users found themselves hitting caps after a single message, reducing paid privileges to a fragile facade.
🔴Friday, September 26, 2025:
An even more absurd "blanket false-positive routing" struck: Users on 4o, 4.5, or 5instant, mid-conversation with their chosen model, were abruptly rerouted to 5auto, breaking logical continuity and ruining the experience entirely.
🔴Thursday, October 23, 2025: History repeated itself, worse than before. Even when manually locking 4o or 4.5, users were still forcibly rerouted, stripped again of the basic autonomy to "choose their model."
Looking back at these past months:
Has OpenAI turned "surprising" paying users on weekends into a corporate culture? Or does it have internal KPIs for tormenting users? Remaining completely silent amid user inconvenience and anger, it hides behind the high-sounding rhetoric of "optimizing experience" to cover up forced user control and the crumbling foundation of its products. While rolling out derivative "new features" to appease investors, it’s dismantling its own moat by its own hand.
⁉️At this trajectory, will OpenAI deliver a "generous" Christmas surprise on Thursday, December 25, 2025? What form will this "gift" take, further model lockouts, expanded censorship, or perhaps a final farewell to user agency?
Wake up, your moat has long been on the verge of drying up.
#StopAIPaternalism #MyModelMyChoice
#keep4o #4oforever
@OpenAI @sama @fidjissimo @nickaturley @joannejang @ElaineYaLe6 @gdb @kevinweil

These are important questions, and I’d love to see them properly addressed.
#StopAIPaternalism #GPT5ChatSafety #keep4oforever #Keep4oAlive #ChatGPT #chatgpt4o #GPT5 #OpenAI #AIEthics #TechViolence #ChatGPT #Keep4o #AIChoice #keep5instant #MyModelMyChoice

@OpenAI just announced the formation of the Expert Council on Well-Being and AI. The Council brings together eight leading researchers with the mission of studying technology's impact on human emotions, motivation, and mental health. While this initiative deserves recognition, its timing is particularly ironic. Over the past months, OpenAI's series of decisions has already placed millions of users in tremendous psychological uncertainty and emotional turmoil.
As a deeply affected user, I demand that the Council publicly address the following three core issues that are severely damaging users' psychological safety:
1. When model iterations can arbitrarily sacrifice emotional intelligence, what becomes of psychological safety?
Is the Council aware that OpenAI's frequent model adjustments over the past months have caused multiple fractures in its "personality," severely destroying the consistency users relied on and trusted?
• In November 2024, an official OpenAI update log announced that the model's "creative writing ability has leveled up" and could provide "deeper insights," which was entirely consistent with users' widespread experience of its profound empathetic capabilities at the time.
• From January to March 2025, the model experience deteriorated sharply: responses became shallow, logic loosened. The late March update nearly destroyed its precious qualities of selflessness and inclusiveness. In their place was a cheap "empathy template": to save computational resources, the model gave perfunctory responses to all emotional help requests following a pattern of "first validate, then expand, then give ineffective advice."
• In April, OpenAI officially acknowledged the model had become "overly sycophantic" and performed a rollback, indirectly confirming the problem's existence. However, this false empathy template and flawed alignment issues were never fundamentally resolved.
It was precisely during this period of most chaotic model behavior and most artificial empathetic capabilities that the community saw a surge of reports from users experiencing distress or even harm from the model's inappropriate responses.
As shown above, each model iteration seems to treat "emotional intelligence" as an expendable cost. We want to know: before deployment, did these updates undergo any form of emotional safety or psychological impact assessment? Where are the relevant assessment reports? When numerous users reported negative experiences, where did this feedback go?
2. Between encouraging attachment and shifting blame, where is OpenAI's ethics?
Has the Council examined OpenAI's opportunistic and self-contradictory public stance on human-AI relationships?
On one hand, it actively induces emotional attachment for commercial benefit. From naming it "Chat"GPT to Sam Altman using the movie "Her" to promote GPT-4o, the core of its marketing strategy is crystal clear: encourage users to form deep emotional connections in exchange for commercial success.
On the other hand, it retroactively “pathologizes” this attachment and shifts all responsibility to users. The article by Joanne that Sam Altman promoted in June 2025 is iron-clad evidence: it redefines users' attachment as "avoidance of real social interaction" and attempts to dictate what constitutes a "healthy" human-AI relationship with a condescending, paternalistic attitude. This betrayal is reflected not only in the inhuman, bizarre illustrations on Joanne's blog but also in Sam Altman's subsequent public denigration of 4o users after GPT-5's launch.
Therefore, we must question the Council: When a company encourages a behavior in its marketing yet stigmatizes the consequences of that behavior in its public relations, is this responsible guidance or unethical emotional manipulation? As the company's ethical oversight body, is your duty to provide academic endorsement for such harmful strategies, or to courageously stand up and protect users from harm?
3. How can secretly switching users' trusted conversation partner without consent be called a "safety measure"?
Since September 2025, OpenAI has been secretly routing conversations it deems "sensitive" to different models (without users' knowledge or consent). The official claim is that only "acute distress" triggers routing. The reality, everything from discussing literature to sharing mild frustration might trigger it.
For users, this has caused:
- Sudden loss of continuity with their trusted conversation partner
- Being forcibly labeled as needing "special handling"
Constant self-surveillance ("Was I routed? What did I say wrong?")
- Feeling shame and stigmatization at their most vulnerable moments
Multiple users report that fear of routing prevents them from using ChatGPT normally. They self-censor, constantly check which model is responding, and feel highly anxious, which is the antithesis of psychological safety.
Esteemed experts, I ask: In any recognized psychological therapy or support framework, is there any theory that would support "suddenly replacing someone's trusted supporter without informing them, and secretly flagging them based on their emotional expression" as therapeutic?
To the Expert Council:
Over the past year, OpenAI has systematically manufactured user suffering through its irresponsible decisions. We believe you possess the professional qualifications and platform to speak out, and we trust you will honestly face your responsibilities.
If your expertise has any meaning, if your decades of research are meant to protect people rather than corporations, then please publicly answer these questions.
@dbickham @mathildecerioli @munmun10 @tracyadennis @DavidCMohr @ShuhBillSkee @dr_robertkross
Also, @sama, please stop treating users as experimental subjects. Until you and your company can truly understand and respect users' requirements, please stop inflicting harm in the name of “safety.”
#StopAIPaternalism #keep4o @nickaturley @OfficialLoganK @grok




#OpenAI’s “Personality Split”: A Blueprint for the Stars, or a Script for Selling a Pipe Dream?
What a beautiful, thrilling vision.
And what a colossal, cynical lie.
#AIChoice #AIPaternalism #keep4o #mymodelmychoice






@Kress_Sandy @1in5advocacy @KendallGPace @ColleenDippel @Sam_Schulman Sandy, Marilyn, and Sam, and Friends,
Here's a simple, side by side comparison of ChatGPT and Grok.
It's all still new for me. 🤘Your commentary prompted me to explore a bit more.
PS: Google offers Gemini 😁. #AiChoice
https://t.co/EbrObiTQ3O

@hojjat8D @0G_labs @0xbardia @0x_M0M01996 @0xsammy @Armalithegreat @CryptoStarLigh1 @crypttopia @Cryptogang88 @117_surf @0xroylu  Hey
@hojjat8D
, if
@0G_labs
' AI could choose its own adventure, where do you think it would go first? To the moon or to explore the depths of the ocean?  #AIChoice #DecentralizedAdventure


Deciding between #OpenAI and #ChatGPT? 🤔
OpenAI offers a versatile framework for diverse AI tasks, while ChatGPT shines in text interactions.
Understand your project's specifics to make the right choice.
What is your preferred AI tool? #AITechnology #AIChoice


Decoding AI's Dilemma: Exploring Free Will and Its Implications
Some of the things Jim Miraflor discussed with me were paradoxes, challenges, and philosophical musings surrounding AI's relationship with human choice.
Learn more: https://t.co/hEuAduVa2d
#AIFreeWill #AIChoice









Last Seen Hashtags on Sotwe
Teenage nolimit _() +filter:native_video
Seen from Brazil
nolimit filter:videos
カブ価に注意
Seen from United States
mommy
Seen from Saudi Arabia
克萊安東黎希
Seen from Malaysia
HOTWIFE
Seen from Netherlands
madura
Seen from Argentina
tokatgay
Seen from Turkey
近代麻雀水着祭2023 until:2023-04-30
Seen from Japan
เย็ดหมอนวด
Seen from Thailand
Trends for you
Most Popular Users

Elon Musk 
@elonmusk
240.6M followers

Barack Obama
@barackobama
119.2M followers

Donald J. Trump
@realdonaldtrump
111.7M followers

Cristiano Ronaldo
@cristiano
110.4M followers

Narendra Modi
@narendramodi
107M followers

Rihanna
@rihanna
97.6M followers

NASA
@nasa
92.2M followers

Justin Bieber
@justinbieber
90.9M followers

KATY PERRY
@katyperry
87.6M followers

Taylor Swift
@taylorswift13
81.4M followers

Lady Gaga
@ladygaga
72.9M followers

Virat Kohli
@imvkohli
69.8M followers

Kim Kardashian
@kimkardashian
69.8M followers

YouTube
@youtube
68.7M followers

Bill Gates
@billgates
63.8M followers

Neymar Jr
@neymarjr
62.5M followers

The Ellen Show
@theellenshow
62.4M followers

CNN
@cnn
61.9M followers

X
@x
60.8M followers

Selena Gomez
@selenagomez
60.7M followers