Top Tweets for #Backprop

If you are getting into neural networks and backprop, Zero to Hero by Andrej Karpathy is a solid start. I’ve been following it myself recently. Get basic derivatives (calculus) and Python OOP down first, makes it smoother
https://t.co/6aL2XSIYzY
#MachineLearning #AI #Backprop

Day 127 -Data Science Journey:
->Backprop Chain Rule:
->Loss- Activation -Weights: Grad = Outer * Inner Derivs (Multiply Back)
->Cross-Entropy: -[p ln(q)+(1-p)ln(1-q)] : Smashes Misses
->Grad Magic: ŷ - y (Sigmoid/Softmax!) ->MSE/Hinge? #ML #NeuralNets #Backprop #DeepLearning
![TensorThrottleX's tweet photo. Day 127 -Data Science Journey:
->Backprop Chain Rule:
->Loss- Activation -Weights: Grad = Outer * Inner Derivs (Multiply Back)
->Cross-Entropy: -[p ln(q)+(1-p)ln(1-q)] : Smashes Misses
->Grad Magic: ŷ - y (Sigmoid/Softmax!) ->MSE/Hinge? #ML #NeuralNets #Backprop #DeepLearning https://t.co/NJHCq2oUma](https://pbs.twimg.com/media/G1dBAF5WgAAXX6l.jpg)
![TensorThrottleX's tweet photo. Day 127 -Data Science Journey:
->Backprop Chain Rule:
->Loss- Activation -Weights: Grad = Outer * Inner Derivs (Multiply Back)
->Cross-Entropy: -[p ln(q)+(1-p)ln(1-q)] : Smashes Misses
->Grad Magic: ŷ - y (Sigmoid/Softmax!) ->MSE/Hinge? #ML #NeuralNets #Backprop #DeepLearning https://t.co/NJHCq2oUma](https://pbs.twimg.com/media/G1dAl7jXUAAXS-q.jpg)
![TensorThrottleX's tweet photo. Day 127 -Data Science Journey:
->Backprop Chain Rule:
->Loss- Activation -Weights: Grad = Outer * Inner Derivs (Multiply Back)
->Cross-Entropy: -[p ln(q)+(1-p)ln(1-q)] : Smashes Misses
->Grad Magic: ŷ - y (Sigmoid/Softmax!) ->MSE/Hinge? #ML #NeuralNets #Backprop #DeepLearning https://t.co/NJHCq2oUma](https://pbs.twimg.com/media/G1dAQv1XEAELTyl.jpg)
![TensorThrottleX's tweet photo. Day 127 -Data Science Journey:
->Backprop Chain Rule:
->Loss- Activation -Weights: Grad = Outer * Inner Derivs (Multiply Back)
->Cross-Entropy: -[p ln(q)+(1-p)ln(1-q)] : Smashes Misses
->Grad Magic: ŷ - y (Sigmoid/Softmax!) ->MSE/Hinge? #ML #NeuralNets #Backprop #DeepLearning https://t.co/NJHCq2oUma](https://pbs.twimg.com/media/G1c_tvlWkAANpLw.jpg)


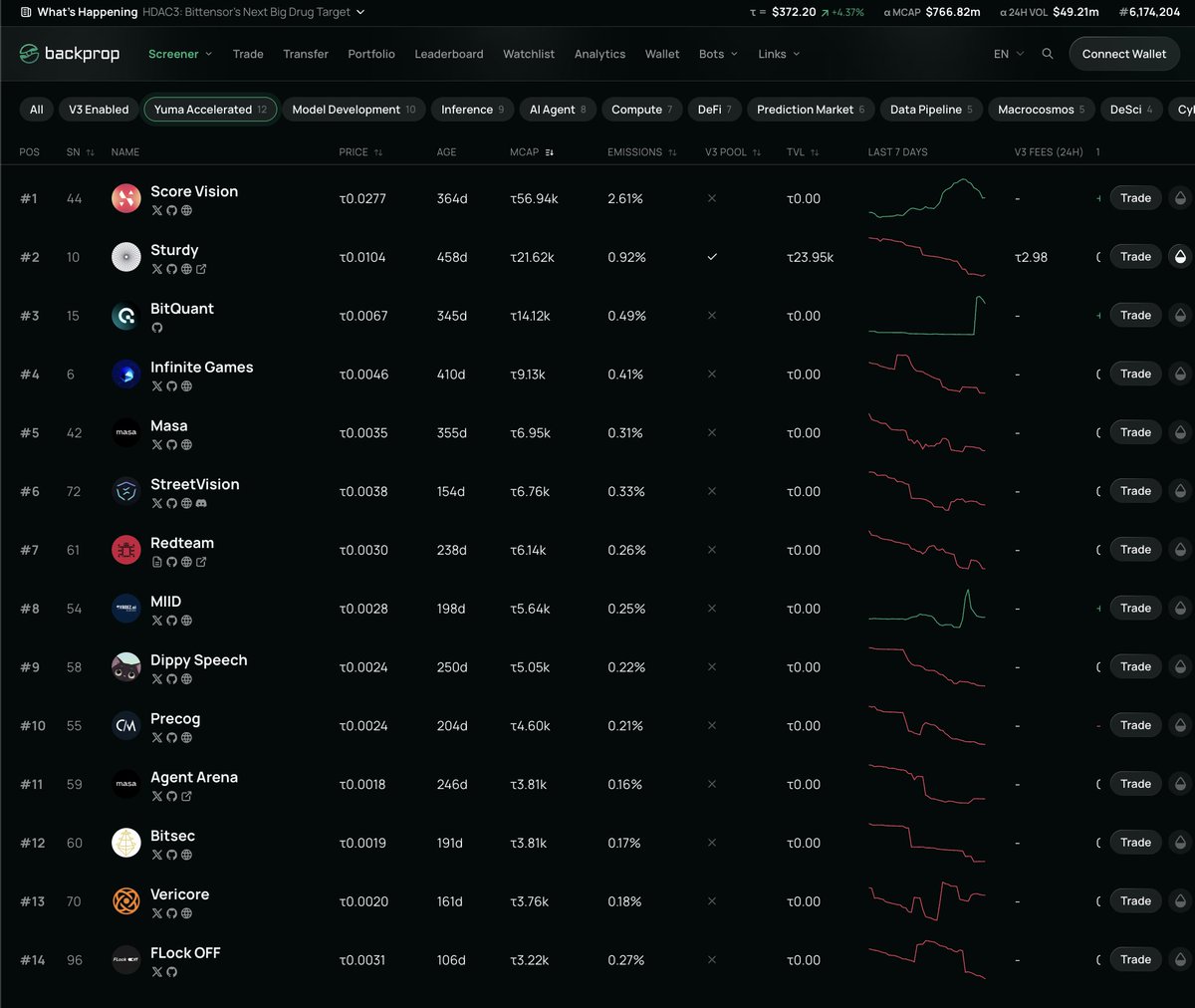
You can view and trade all of "Yuma Accelerated" Subnets on Backprop Screener!

Backpropagation From Scratch - Animated
Learn backpropagation from scratch and understand how neural network learn
Max video length on x is 10min, full youtube video in replies
#neuralnetworks #backprop #backpropagation

Been studying the OG ’86 paper “Learning representations by backpropagating errors” by Rumelhart, Hinton & Williams — where errors backprop, weights shift, deep learning is born... Pure brainpower meets math.
#TechDeepDive #NerdAlert #AI #ML #Backprop
🔗https://t.co/9fBKSeBEyw




ขอบคุณลูกค้าที่ไว้ใจให้ทางร้านบริการนะคะ ส่งมอบงานป้าย Backdrop โครงเหล็ก ขนาด 1.3 x 2.4 m. พร้อมติดตั้ง ณ ธันเดอร์โดมเมืองทองธานี เมื่อวันที่ 6 เมษาที่ผ่านมาค่ะ 🥰 #ป้ายเชียร์ศิลปิน #backprop #ป้ายโฆษณา #สแตนดี้ #ไวนิล





@mysuel @JoseCuetoAservi @dianagonzalesd_ Esperando también leer la norma que la promueve y supervisa. Hasta donde se, se piensa definir estándares de riesgo para diferentes casos de uso. No me parece una mala idea empezar con casos de usos fuertes e iterar en el tiempo aprendiendo de errores y experiencias #backprop

Pioneers in the field have found ways to apply techniques like #backprop, forward prop, and equilibrium prop to train neuromorphic networks. However, good local learning rules for sparse, highly recurrent networks remain elusive; despite biological existence proofs.

.@nshervt & @RobertRosenba14 report that #metalearning reveals interpretable learning rules under biological constraints, shedding light on how brain may implement #backprop-like #algorithms.
#neuralnetworks #GettingApplied
https://t.co/WyzAQ8dMuV

Another entry in the research papers we find really cool over here at @tenstorrent .
Especially fond of this one given a) the suitability with our hardware architecture and b) many of us being fans of Aidan over at @CohereAI
#revnet #ML #AI #backprop
https://t.co/RLxQ1DZmjt


Which deep learning framework do you prefer?
@PyTorch @TensorFlow #ml #neuralnetworks #backprop #thefuture

Our #Semantic #Probabilistic #Layers #SPLs instead always guarantee 100% of the times that predictions satisfy the injected constraints!
They can be readily used in deep nets as they can be trained by #backprop and #maximum #likelihood #estimation.
Check them out @ylecun!
4/




@AlexTensor @YiMaTweets @ylecun @Michael_J_Black @drfeifei @isbellHFh @mlittmancs @jcniebles @FabianCabaH underdeveloped theory (#CausalML #SelfSupervisedLearning #Backprop #Hebbian) in my future device. Plus, I'm a human prone to make mistakes.
(apologies to the ppl reading & tagged here that don't make mistakes)
Thus, I will raise biased kids. Enlighten us on how not to do so 😊

This blog post looks at what may replace back-propagation in future deep learning and why so many alternative learning algorithms cannot be used at scale ...yet. Read it here 👇
https://t.co/HvhWang29r
#DeepLearning #Backprop #FeedbackAlignment #DeepLearningAi


In Lecture 14, we introduce #neuralnetworks & #deeplearning! We start with the biological #neuron, the #perceptron, #activationfunctions & #backprop. We only have 2 classes + 1 lab for this topic so we must prioritize! What would you teach? #ML #CUDBMIMLHC #followme #comment👇

Before the legendary #backprop paper (Rumelhart, @geoffreyhinton, Williams 1986), perceptrons were optimized using a diff algo: Perceptron Learning Algo. It doesn't require differentiable losses and resembles a bit #FGSM from @goodfellow_ian @TDataScience https://t.co/eEVfCvbqCz
Last Seen Hashtags on Sotwe
teenagergirls
kraljicatuge
Seen from United States
AHsohbeti
Seen from United States
tekirdağtravesti
Seen from Turkey
Blockchain
Seen from United States
onsbkk
Seen from Thailand
miakhalifa
Seen from Turkey
satorugojo #gay
Seen from Poland
TikToksluts
Seen from United States
UCLFantasy
Seen from United States
Most Popular Users

Elon Musk 
@elonmusk
240.7M followers

Barack Obama
@barackobama
119.2M followers

Donald J. Trump
@realdonaldtrump
111.7M followers

Cristiano Ronaldo
@cristiano
110.8M followers

Narendra Modi
@narendramodi
107M followers

Rihanna
@rihanna
97.7M followers

NASA
@nasa
92.2M followers

Justin Bieber
@justinbieber
90.9M followers

KATY PERRY
@katyperry
87.8M followers

Taylor Swift
@taylorswift13
81.6M followers

Lady Gaga
@ladygaga
73.1M followers

Virat Kohli
@imvkohli
70M followers

Kim Kardashian
@kimkardashian
69.8M followers

YouTube
@youtube
68.7M followers

Bill Gates
@billgates
63.9M followers

Neymar Jr
@neymarjr
62.8M followers

The Ellen Show
@theellenshow
62.4M followers

CNN
@cnn
61.9M followers

Selena Gomez
@selenagomez
60.9M followers

X
@x
60.8M followers