We're training the largest open-source, open-development, AND open-weight base LLMs of any (actual) non-profit. The latest on our journey to the frontier is a 129B-A16B 1T tokens (1e23 FLOPs) MoE.
We've improved our training efficiency (i.e. loss per FLOP) by >5x in just the past couple months.
Follow along the day to day work in Discord, watch us make mistakes and discuss tradeoffs on GitHub, see our loss curves on Weights & Biases, and watch us consistently hit our preregistered loss targets within 1% @ https://t.co/U27JLe5oYy
Building momentum at Marin! Upgrading from Dense -> 129B parameter MoEs -> architecture improvements -> optimizer improvements gives our pretraining recipe an estimated 6x cumulative learning speedup, accounting for MFU. Includes community contributions. https://t.co/5dPB9uBiSp
Building momentum at Marin! Upgrading from Dense -> 129B parameter MoEs -> architecture improvements -> optimizer improvements gives our pretraining recipe an estimated 6x cumulative learning speedup, accounting for MFU. Includes community contributions. https://t.co/5dPB9uBiSp
When you come into biology from CS you scoff at the obscurity of everyone's research, look at all these underpaid postdocs churning out papers on ridiculously niche topics. They don't have the right (startup-adjacent) cultural traits to tackle ambitious goals.
Then...
In SuperBPE we found: as tokenizer compression increases, the compute-optimal ratio of train tokens to model params decreases — and remarkably, corresponds to the same underlying ratio of train *bytes* / param! Our new work makes it official: scaling laws depend on compression.
To train better open models, we need predictable scaling.
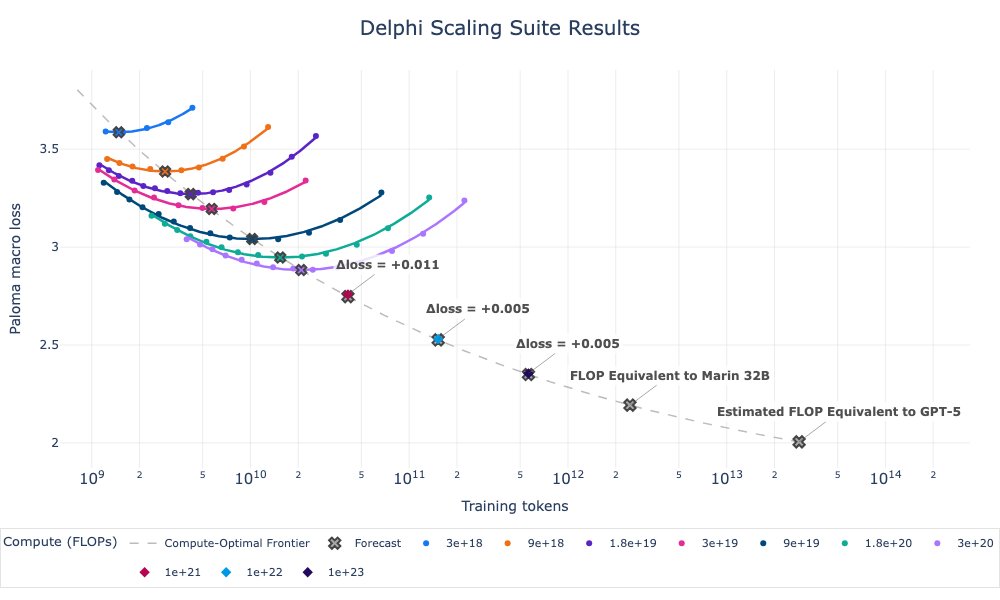
Delphi is Marin’s first step: we pretrained many small models with one recipe, then extrapolated 300× to predict a 25B-param / 600B-token run with just 0.2% error.
Getting there took some work 🧵
Introducing ml-intern, the agent that just automated the post-training team @huggingface
It's an open-source implementation of the real research loop that our ML researchers do every day. You give it a prompt, it researches papers, goes through citations, implements ideas in GPU sandboxes, iterates and builds deeply research-backed models for any use case. All built on the Hugging Face ecosystem.
It can pull off crazy things:
We made it train the best model for scientific reasoning. It went through citations from the official benchmark paper. Found OpenScience and NemoTron-CrossThink, added 7 difficulty-filtered dataset variants from ARC/SciQ/MMLU, and ran 12 SFT runs on Qwen3-1.7B. This pushed the score 10% → 32% on GPQA in under 10h. Claude Code's best: 22.99%.
In healthcare settings it inspected available datasets, concluded they were too low quality, and wrote a script to generate 1100 synthetic data points from scratch for emergencies, hedging, multilingual etc. Then upsampled 50x for training. Beat Codex on HealthBench by 60%.
For competitive mathematics, it wrote a full GRPO script, launched training with A100 GPUs on https://t.co/udm7xGpNzR, watched rewards claim and then collapse, and ran ablations until it succeeded. All fully backed by papers, autonomously.
How it works?
ml-intern makes full use of the HF ecosystem:
- finds papers on arxiv and https://t.co/brvCC7fLPa, reads them fully, walks citation graphs, pulls datasets referenced in methodology sections and on https://t.co/hrJuRkRyzi
- browses the Hub, reads recent docs, inspects datasets and reformats them before training so it doesn't waste GPU hours on bad data
- launches training jobs on HF Jobs if no local GPUs are available, monitors runs, reads its own eval outputs, diagnoses failures, retrains
ml-intern deeply embodies how researchers work and think. It knows how data should look like and what good models feel like.
Releasing it today as a CLI and a web app you can use from your phone/desktop.
CLI: https://t.co/l3K1PslZ1n
Web + mobile: https://t.co/orko5srL4H
And the best part? We also provisioned 1k$ GPU resources and Anthropic credits for the quickest among you to use.
So cool to see that open-source, with open experimentation (and with the help of someone posting blog posts about their personal research), can yield a very robust method for MoE balancing. This method seems more elegant than all other methods I have seen. Open source is Awesome!
Marin is using quantile balancing from @Jianlin_S (who developed RoPE, which was also a good idea) to train our current 1e23 FLOPs MoE. The idea is elegant: assigning tokens to experts by solving a linear program. No hyperparameters to tune. Yields stable training.
This week, @classiclarryd kicked off a 129B (16B active) 1e23 FLOPs MoE run. In typical Marin style, we have fit scaling laws and have made a loss projection of 2.252. Stay tuned.
Researchers' brilliant ideas often get lost in the sea of endless SOTA claims on weak baselines. At Marin we battle-test ideas in an open arena, where anyone's idea can be promoted to the next hero run. One that recently rose up was @Jianlin_S MoE Quantile Balancing, used in our last 1e22 and ongoing 130B run. Animated visuals of how QB performed are available in the OpenAthena blog. https://t.co/BDSsonuNH7
after starting open Athena less than two years ago, it's amazing to see the progress to advance ai for science that the team has driven https://t.co/qeO2nHT8Iz
Our 1e23 Delphi run finished last night. It's loss was within 0.005 of the projected (preregistered) loss. Note that these projections were based on only training models over 100x smaller (3e20)!
Still more work to do. We still had loss spikes and if you closely, our scaling laws are bending. We have some ideas for fixing both...
How far do Marin's scaling laws extrapolate? At least 100x, apparently!
Despite spooky spikes, our 1e23 Delphi finished on forecast. The compute-optimal ladder costs ~1e21 FLOPs to train. Good scaling science lets you “run” this (not tiny) experiment at 1/100th the cost.
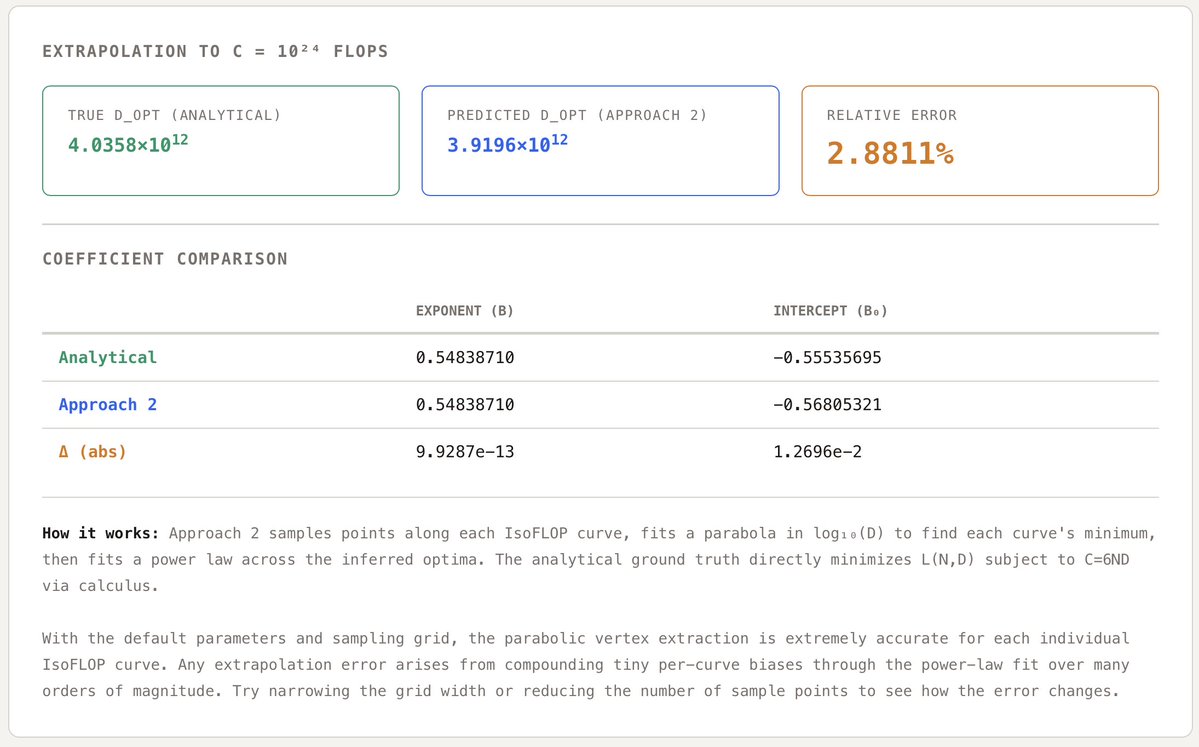
Scaling laws are "just" regressions. But a biased fitting method can quietly misallocate millions of $ of compute at frontier scales.
My coworker Eric Czech dug into a bias in parabolic IsoFLOP fits used by Meta, DeepSeek, Microsoft, Waymo, et al. for their scaling laws🧵
In Marin, we are trying to get really good at scaling laws. We have trained models up to 1e22 FLOPs and have made a prediction of the loss at 1e23 FLOPs, which @WilliamBarrHeld is running. This prediction is preregistered on GitHub, so we'll see in a few days how accurate our prediction was. What we want is not just a single model but a training recipe that scales reliably.
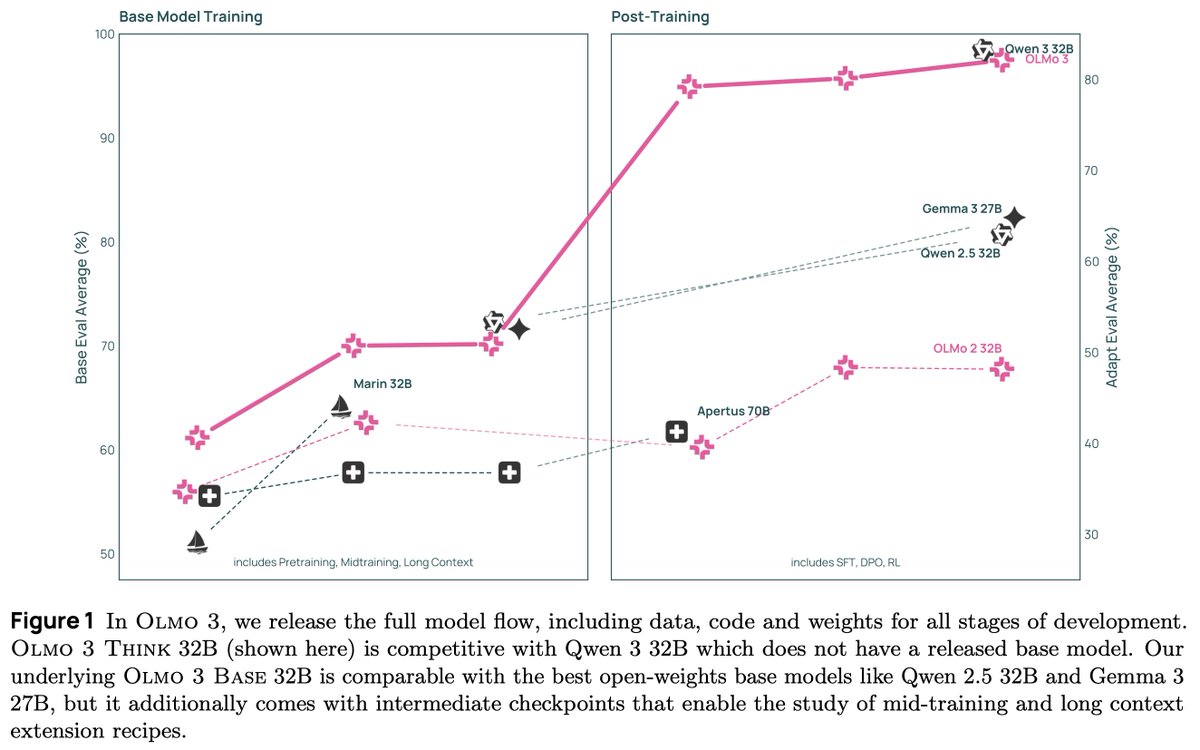
We present Olmo 3, our next family of fully open, leading language models.
This family of 7B and 32B models represents:
1. The best 32B base model.
2. The best 7B Western thinking & instruct models.
3. The first 32B (or larger) fully open reasoning model.
This is a big milestone for Ai2 and the Olmo project. These aren’t huge models (more on that later), but it’s crucial for the viability of fully open-source models that they are competitive on performance – not just replications of models that came out 6 to 12 months ago. As always, all of our models come with full training data, code, intermediate checkpoints, training logs, and a detailed technical report. All are available today, with some more additions coming before the end of the year.
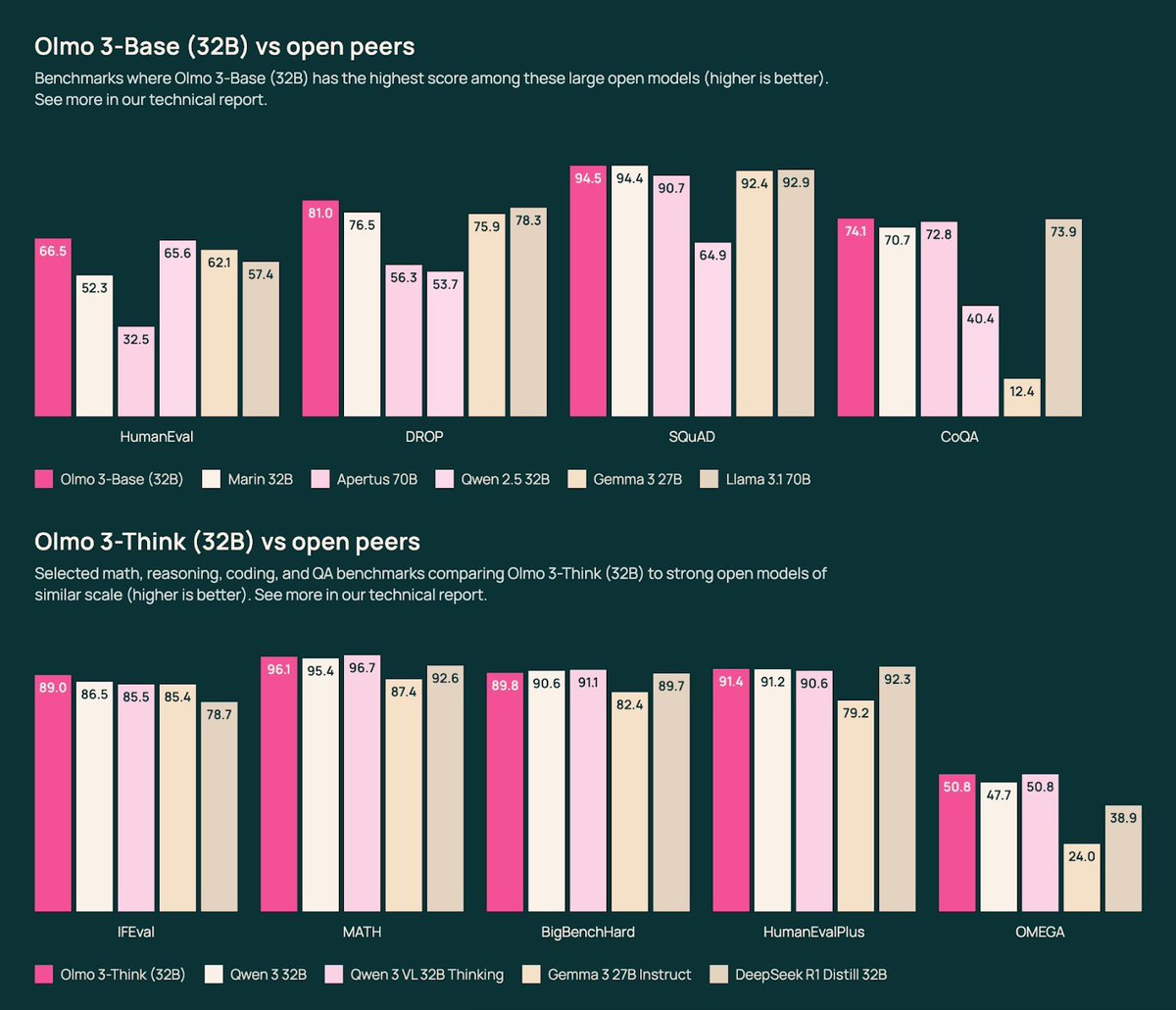
As with OLMo 2 32B at its release, OLMo 3 32B is the best open-source language model ever released. It’s an awesome privilege to get to provide these models to the broader community researching and understanding what is happening in AI today.
Base models – a strong foundation
Pretraining’s demise is now regularly overstated. 2025 has marked a year where the entire industry rebuilt their training stack to focus on reasoning and agentic tasks, but some established base model sizes haven’t seen a new leading model since @alibaba_qwen's Qwen 2.5 in 2024. The Olmo 3 32B base model could be our most impactful artifact here, as Qwen3 did not release their 32B base model (likely for competitive reasons). We show that our 7B recipe competes with Qwen 3, and the 32B size enables a starting point for strong reasoning models or specialized agents. Our base model’s performance is in the same ballpark as Qwen 2.5, surpassing the likes of Stanford’s Marin (@stanfordAILab) and Gemma 3 (@GoogleDeepMind), but with pretraining data and code available, it should be more accessible to the community to learn how to finetune it (and be confident in our results).
We’re excited to see the community take Olmo 3 32B base in many directions. 32B is a loved size for easy deployment on single 80GB+ memory GPUs and even on many laptops, like the MacBook I’m using to write this on.
A model flow – the lifecycle of creating a model
With these strong base models, we’ve created a variety of post-training checkpoints to showcase the many ways post-training can be done to suit different needs. We’re calling this a “Model Flow.” For post-training, we’re releasing Instruct versions – short, snappy, intelligent, and useful especially for synthetic data en masse (e.g. recent work by Datology @datologyai on OLMo 2 Instruct), Think versions – thoughtful reasoners with the performance you expect from a leading thinking model on math, code, etc. and RL Zero versions – controlled experiments for researchers understanding how to build post-training recipes that start with large-scale RL on the base model.
The first two post-training recipes are distilled from a variety of leading, open and closed, language models. At the 32B and smaller scale, direct distillation with further preference finetuning and reinforcement learning with verifiable rewards (RLVR) is becoming an accessible and highly capable pipeline. Our post-training recipe follows our recent models: 1) create an excellent SFT set, 2) use direct preference optimization (DPO) as a highly iterable, cheap, and stable preference learning method despite its critics, and 3) finish up with scaled up RLVR. All of these stages confer meaningful improvements on the models’ final performance.
Instruct models – low latency workhorse
Instruct models today are often somewhat forgotten, but the likes of @aiatmeta Llama 3.1 Instruct and smaller, concise models are some of the most adopted open models of all time. The instruct models we’re building are a major polishing and evolution of the Tülu 3 pipeline – you’ll see many similar datasets and methods, but with pretty much every datapoint or training code being refreshed. Olmo 3 Instruct should be a clear upgrade on Llama 3.1 8B, representing the best 7B scale model from a Western or American company. As scientists we don’t like to condition the quality of our work based on its geographic origins, but this is a very real consideration to many enterprises looking to open models as a solution for trusted AI deployments with sensitive data.
Building a thinking model
What people have most likely been waiting for are our thinking or reasoning models, both because every company needs to have a reasoning model in 2025, but also to clearly open the black box for the most recent evolution of language models. Olmo 3 Think, particularly the 32B, are flagship models of this release, where we considered what would be best for a reasoning model at every stage of training.
Extensive effort (ask me IRL about more war stories) went into every stage of the post-training of the Think models. We’re impressed by the magnitude of gains that can be achieved in each stage – neither SFT nor RL is all you need at these intermediate model scales.
First we built an extensive reasoning dataset for supervised finetuning (SFT), called Dolci-Think-SFT, building on very impactful open projects like OpenThoughts3, Nvidia’s Nemotron Post-training, Prime Intellect’s SYNETHIC-2, and many more open prompt sources we pulled forward from Tülu 3 / OLMo 2. Datasets like this are often some of our most impactful contributions (see the Tülu 3 dataset as an example in Thinking Machine’s Tinker :D @thinkymachines @tinker_api – please add Dolci-Think-SFT too, and Olmo 3 while you’re at it, the architecture is very similar to Qwen which you have).
For DPO with reasoning, we converged on a very similar method as HuggingFace’s (@huggingface) SmolLM 3 with Qwen3 32B as the chosen model and Qwen3 0.6B as the rejected. Our intuition is that the delta between the chosen and rejected samples is what the model learns from, rather than the overall quality of the chosen answer alone. These two models provide a very consistent delta, which provides way stronger gains than expected. Same goes for the Instruct model. It is likely that DPO is helping the model converge on more stable reasoning strategies and softening the post-SFT model, as seen by large gains even on frontier evaluations such as AIME.
Our DPO approach was an expansion of Geng, Scott, et al. "The delta learning hypothesis: Preference tuning on weak data can yield strong gains." arXiv preprint arXiv:2507.06187 (2025). Many early open thinking models that were also distilled from larger, open-weight thinking models likely left a meaningful amount of performance on the table by not including this stage.
Finally, we turn to the RL stage. Most of the effort here went into building effective infrastructure to be able to run stable experiments with the long-generations of larger language models. This was an incredible team effort to be a small part of, and reflects work ongoing at many labs right now. Most of the details are in the paper, but our details are a mixture of ideas that have been shown already like ServiceNow’s PipelineRL or algorithmic innovations like DAPO and Dr. GRPO. We have some new tricks too!
Some of the exciting contributions of our RL experiments are 1) what we call “active refilling” which is a way of keeping the generations from the learner nodes constantly flowing until there’s a full batch of completions with nonzero gradients (from equal advantages) – a major advantage of our asynchronous approach; and 2) cleaning, documenting, decontaminating, mixing, and proving out the large swaths of work done by the community over the last months.
The result is an excellent model that we’re very proud of. It has very strong reasoning benchmarks (AIME, GPQA, etc.) while also being stable, quirky, and fun in chat with excellent instruction following. The 32B range is largely devoid of non-Qwen competition. The scores for both of our Thinkers get within 1-2 points overall with their respective Qwen3 8/32B models – we’re proud of this!
A very strong 7B scale, Western thinking model is Nvidia’s (@NVIDIAAI) NVIDIA-Nemotron-Nano-9B-v2 hybrid model. It came out months ago and is extremely strong. I personally suspect it may be due to the hybrid architecture making subtle implementation bugs in popular libraries, but who knows.
All in, the Olmo 3 Think recipe gives us a lot of excitement for new things to try in 2026.
RL Zero
DeepSeek R1 showed us a way to new post-training recipes for frontier models, starting with RL on the base model rather than a big SFT stage (yes, I know about cold-start SFT and so on, but that’s an implementation detail). We used RL on base model as a core feedback cycle when developing the model, such as during intermediate midtraining mixing. This is viewed now as a fundamental, largely innate, capability of the base-model.
To facilitate further research on RL Zero, we released 4 datasets and series of checkpoints, showing per-domain RL Zero performance on our 7B model for data mixes focus on math, code, instruction following, and all mixed together.
In particular, we’re excited about the future of RL Zero research on Olmo 3 precisely because everything is open. Researchers can study the interaction between the reasoning traces we include at midtraining and the downstream model behavior (qualitative and quantitative).
This helps answer questions that have plagued RLVR results on Qwen models, hinting at forms of data contamination particularly on math and reasoning benchmarks (see Shao, Rulin, et al. "Spurious rewards: Rethinking training signals in rlvr." arXiv preprint arXiv:2506.10947 (2025). or Wu, Mingqi, et al. "Reasoning or memorization? unreliable results of reinforcement learning due to data contamination." arXiv preprint arXiv:2507.10532 (2025).)
What’s next
This is the biggest project we’ve ever taken on at Ai2 (@allen_ai), with 60+ authors and numerous other support staff.
In building and observing “thinking” and “instruct” models coming today, it is clear to us that there’s a very wide variety of models that fall into both of these buckets. The way we view it is that thinking and instruct characteristics are on a spectrum, as measured by the number of tokens used per evaluation task. In the future we’re excited to view this thinking budget as a trade-off, and build models that serve different use-cases based on latency/throughput needs.
As for a list of next models or things we’ll build, we can give you a list of things you’d expect from a (becoming) frontier lab: MoEs, better character training, pareto efficient instruct vs think, scale, specialized models we actually use at Ai2 internally, and all the normal things.
This is one small step towards what I see as a success for my ATOM project.
We thank you for all your support of our work at Ai2. We have a lot of work to do. We’re going to be hunting for top talent at NeurIPS to help us scale up our Olmo team in 2026.
This post in full also appears on Interconnects – the full links to the artifacts and paper are below.
Moo, moo, rawr!
Introducing OlmoEarth 🌍, state-of-the-art AI foundation models paired with ready-to-use open infrastructure to turn Earth data into clear, up-to-date insights within hours—not years.