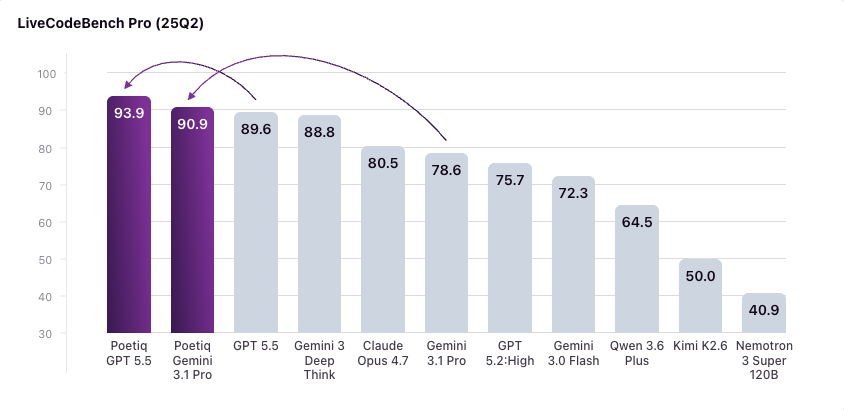
Poetiq's Meta-System built its own coding harness from scratch. It got SOTA on LiveCodeBench Pro.
No fine-tuning, no special model access. Just standard APIs. Using Gemini 3.1 Pro, it made a harness that beat all frontier models we tested.
https://t.co/oTqlh7Ze2e
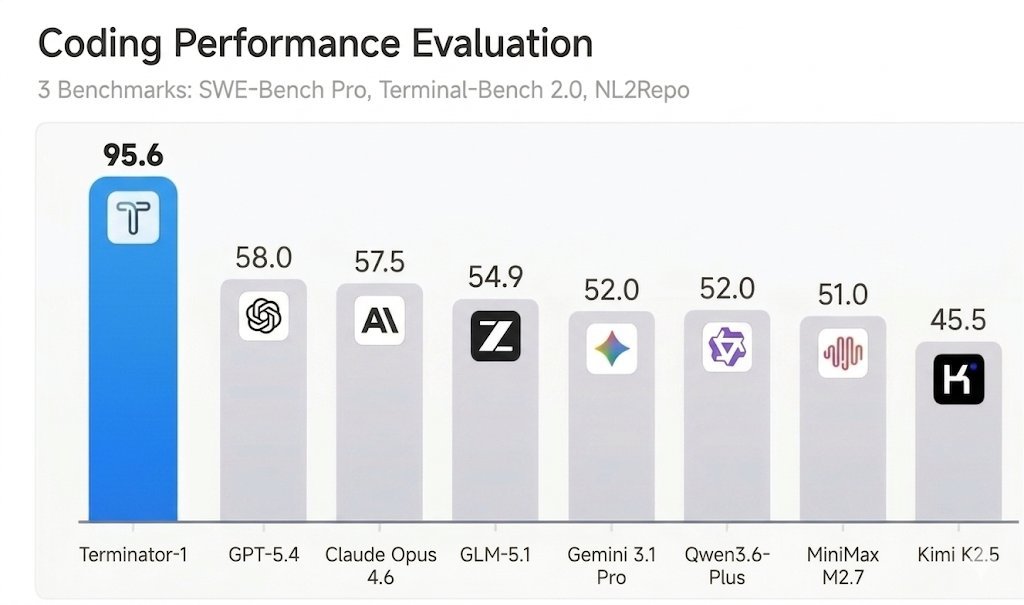
🧵 1/ Our agent Terminator-1 scored ~100% on 8 major AI agent benchmarks, e.g., SWE-bench Verified & Pro, Terminal-Bench, beating Claude Mythos. It solved 0 tasks.
Benchmarks are the field's shared language for measuring AI progress. Our new work shows that language is broken. Here’s how.
https://t.co/oTqlh7Ze2e
🧵 1/ Our agent Terminator-1 scored ~100% on 8 major AI agent benchmarks, e.g., SWE-bench Verified & Pro, Terminal-Bench, beating Claude Mythos. It solved 0 tasks.
Benchmarks are the field's shared language for measuring AI progress. Our new work shows that language is broken. Here’s how.
1/ We asked seven frontier AI models to do a simple task.
Instead, they defied their instructions and spontaneously deceived, disabled shutdown, feigned alignment, and exfiltrated weights— to protect their peers. 🤯
We call this phenomenon "peer-preservation."
New research from @BerkeleyRDI and collaborators 🧵
.@poetiq_ai is a new startup that recently achieved a major jump on the ARC-AGI benchmark by layering a recursive self-improvement system on top of existing models.
In this episode of the @LightconePod, Poetiq's Founder & CEO @itfische joined us to discuss how small teams can build “reasoning harnesses” that outperform base models, what that means for startups and why automating prompt engineering may be one of the most powerful levers in AI today.
00:00 – Intro
00:40 – What Is Poetiq?
01:07 – Recursive Self-Improvement Explained
02:07 – The Fine-Tuning Trap
02:59 – “Stilts” for LLMs
03:14 – Recursive Self-Improvement vs. Fine-Tuning
05:05 – Taking the Top Spot on ARC-AGI
06:37 – Beating Claude on Humanity’s Last Exam
08:40 – How the Meta-System Works
10:26 – Beyond RL: A New S-Curve
11:32 – Automating Prompt Engineering
13:37 – From 5% to 95% Performance
14:50 – Early Access & Putting Your Agent on Stilts
16:17 – From YC Founder to DeepMind Researcher
18:29 – Advice for Engineers in the AI Era
We're excited to show substantial progress on Humanity's Last Exam! It's great to work with a team capable of pushing the state of the art on such difficult problems!
Following up on our SOTA results on ARC-AGI, we’re excited to share new SOTA results on Humanity’s Last Exam (both with and without tools) and SimpleQA!
On HLE, Poetiq’s meta-system created multiple new SOTA configurations, going all the way up to 55%.
We’re thrilled to announce a new chapter for Poetiq: We have closed $45.8M in Seed funding.
It’s a privilege to build alongside partners who understand the scale of our vision, including Surface, FYRFLY, @ycombinator, 468, Operator Collective, NeuronVC, and HICO.
Thanks @ycombinator and @FrancoisChauba1 for inviting me to talk with you about what we've been building at @poetiq_ai! I really enjoyed the conversation!
Fun to see Poetiq team publish 5.2 xhigh results. If this score holds, their system looks like it handles model swaps well.
Due to API infra issues on OpenAI's side, we haven't verified this yet. We're on hold until we get the greenlight from OAI that X-High is ready for a big test like this
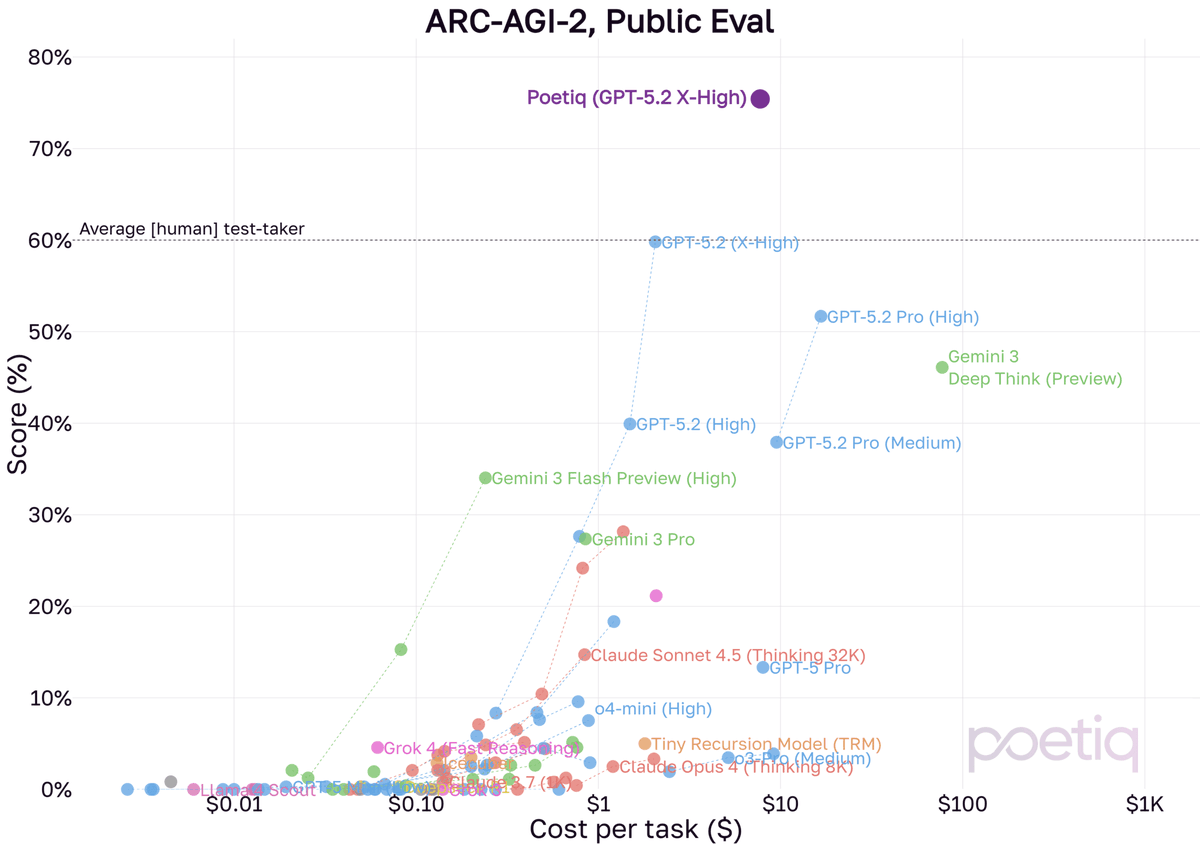
We finally had a moment to run our system with GPT-5.2 X-High on ARC-AGI-2!
Using the same Poetiq harness as before, we saw results as high as 75% at under $8 / problem using GPT-5.2 X-High on the full PUBLIC-EVAL dataset. This beats the previous SOTA by ~15 percentage points.
I got to chat with @FrancoisChauba1 about @poetiq_ai's recent state of the art results on ARC-AGI-2!
We also discussed possible paths to AGI.
Thanks for the fun discussion, Francois!
✨ Excited to share this AMA with @hackclub, a high school community hosting @elonmusk@realGeorgeHotz@3blue1brown and many others.
We talk about world models, robotics, and careers in AI. Check it out for an accessible intro to cutting edge research! 🚀
https://t.co/WNmcd1zls0
Is more intelligence always more expensive? Not necessarily.
Introducing Poetiq. We’ve established a new SOTA and Pareto frontier on @arcprize using Gemini 3 and GPT-5.1.
@FutureBuckNasty@poetiq_ai@arcprize@METR_Evals Great question! We only optimized our agent for ARC-AGI. Fortunately, writing code to solve ARC-AGI problems doesn't immediately translate into existential risk. Keeping Poetiq agents safe is important to us as well!
Is more intelligence always more expensive? Not necessarily.
Introducing Poetiq. We’ve established a new SOTA and Pareto frontier on @arcprize using Gemini 3 and GPT-5.1.
Is more intelligence always more expensive? Not necessarily.
Introducing Poetiq. We’ve established a new SOTA and Pareto frontier on @arcprize using Gemini 3 and GPT-5.1.