Minibwa is a hybrid of bwa-mem and minimap2 and the successor of bwa-mem for short-read mapping. ~4X/2.5X as fast as bwa-mem/bwa-mem2 for WGS reads at comparable accuracy. Native support of directional bisulfite-seq. Applicable to long reads. Preprint at https://t.co/y5ZTr9btE6
Delighted to share our latest research from the @23andMeResearch Team, just published in @Nature
! We looked at data from >27,000 participants to uncover how human genetics influences weight loss efficacy and side effects of GLP-1 medications like semaglutide. A thread 🧵👇
🚨 Our parent-of-origin study is out in @Nature ! 🧬
Maternal and paternal alleles can have distinct — even opposite — effects on human traits, revealing a hidden layer of genetic architecture that standard GWAS miss.
🔗https://t.co/OWW6vGxGYI
Highlights below!
Thrilled to receive the Early Career Award for my presentation at #ESHG2025! 🧬
Big thanks to all the amazing collaborators on this project — couldn't have done it without you.
Grateful to the organizers and inspired by the science shared this week!
🚨 Our preprint on parent-of-origin effects (POEs) is out!
With our new method, we inferred the parental origin of >220,000 individuals, revealing new insights into the genetic architecture of complex traits.
👉 Read here: https://t.co/dm4limMAqM
👇 Highlights below!
Thrilled to be in Denver with 14 colleagues from @AstraZeneca’s Centre for Genomics Research, ready for 5 days of human genomics #ASHG24
The perfect chance to learn about how genomics is transforming drug discovery!
Here’s a thread of our presentations - see you there 😀
Very proud to be part of this study led by Anna Malaspinas, published in @Nature, exploring the genomic history of Rapa Nui. Huge shoutout to Barbara and Victor for their amazing work! Check out our findings here: https://t.co/pJYMdFWil1
Excited to share our new work on the common and rare variant genetic architecture of cognitive ability across childhood and adolescence, using data from @CO90s, @CLScohorts, and @uk_biobank.
https://t.co/EBmPZjY9r5
Only 3 weeks left to apply!
We're looking for computer scientists and statisticians to join our lab in solving cool and important biological puzzles.
Check out: https://t.co/kLdoi83cGl
Previous papers have shown that drug targets with supporting genetic evidence can have twice the success rate when reaching clinical trials. In our most recent paper (https://t.co/Rq5ZVaOwgj), we looked at how data from @23andMe can provide additional genetic evidence. 🧵1/8
The Hinch lab is looking for an enthusiastic statistician, mathematician or physicist to join us as a postdoc!
If you'd like to use big data to decode the inner workings of our cells, apply now: https://t.co/KQeytZRo0H
Please RT!
#PhDjobs#Postdocs#STEM#meiosis#genomics
Not sure what's the causal gene at your favorite GWAS locus? Ask ChatGPT :)
Interesting preprint on the value of LLMs in causal gene prediction by 23andme scientists (@suyashss et al.)
"Here, we demonstrate that large language models (LLMs) can accurately identify genes likely to be causal at loci from GWAS."
The authors claim GPT-4o outperforms the state-of-the-art methods like nearest gene, PoPs, Open Target's L2G etc. However, the performance seems to be biased towards genes that are well studied in the literature. The prediction accuracy increases with increase in the number of publications for the gene (but that's true for other methods too)
And, like any other methods, ChatGPT struggles to predict causal genes when there are so many genes in the vicinity. The prediction accuracy drops with increasing number of genes in the locus.
Interestingly, there are few scenarios where ChatGPT perform very poorly. When phenotype names are not informative enough. It's obvious to us that 'total protein' is total protein levels in the blood, but not to ChatGPT.
ChatGPT doesn't know that a locus can have multiple GWAS signals, each pointing to a unique gene, which can be sometimes obvious based on coding variants.
Finally, ChatGPT hallucinates occasionally (<1%) predicting causal genes that are not even there in the locus.
Causal gene prediction is an obvious application for LLM, and it was only a matter of time before someone looked into it. Glad to see that 23andMe team did it.
@adamauton
https://t.co/yGQzpsZlse
@23andMeResearch@amythewilliams And our preprint is live! A great collab w @amythewilliams and @23andMeResearch, led by my amazing grad student Cole Williams ! “Phasing millions of samples achieves near perfect accuracy, enabling parent-of-origin classification of variants.” bioRxiv doi: https://t.co/oY5o5EDGvw
23andMe is hiring a Senior Bioinformatics Scientist! Please apply, or share with those that may be interested! Feel free to DM me for more details.
https://t.co/si8ebntnmL
Oops! Samtools 1.19.1 had a bug which broke filtering on unordered BED files. This is now fixed in release 1.19.2. See https://t.co/oBT6uOcTtz for links to tarballs and release notes.
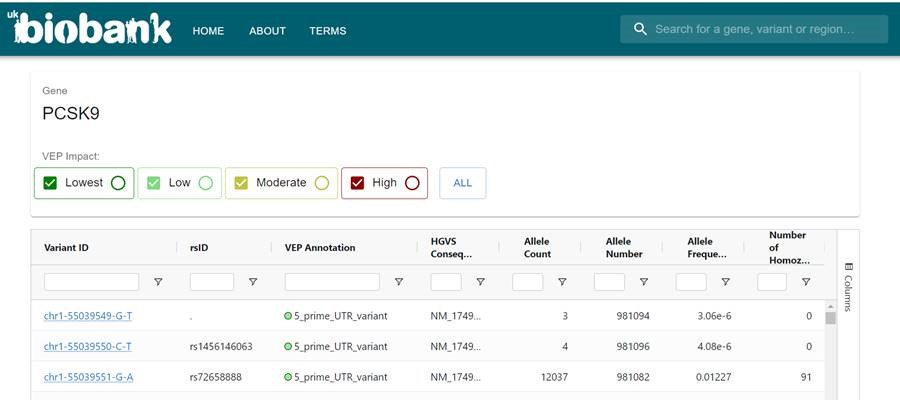
Great news! You can now browse the #500KGenomes summary statistics for all UK Biobank participants free of charge using our Allele Frequency Browser. The browser was launched on behalf of the Whole Genome Sequencing consortium.
🧬https://t.co/SZEtSs2He0
We have a new preprint out! This work shows the protective effects of LoFs in MAP3K15 in Type II diabetes risk (even on high risk PRS backgrounds), and importantly the "genetics driven recruitment" capabilities of the @23andMe database. https://t.co/sYEejt4Jfa
Hi #ASHG2023 ! 👋
Interested in the UK Biobank phased data I presented yesterday? Accessible to approved UKB researchers via #dnanexus.
--> Meet @ODelaneau at poster 4261 today at 2:15 to delve into the application of these haplotypes for genotype imputation!