Introducing Ideogram 4.0: the best open image model in the world.
Think it. Make it. Own it.
Download the weights, fine-tune on your own data, and run it on your hardware. Live on every Ideogram plan and the API today.
🚀 Major upgrades just landed in SuperSplat, the free and open source platform for 3D Gaussian splatting.
Here is a 24-MILLION-Gaussian scan streaming live to a web browser. Near instant load time. Solid 60 fps.
How? A new compute-based WebGPU renderer + automatic LOD streaming. 🧵
Seeing Martin Scorsese using FLUX for storyboarding and scene exploration was absolutely insane. Experiencing how one of the absolute masters of cinema & filmmaking uses the technology that we developed, his curiosity and creativity, and the way he prompted our models, was humbling.
I am grateful to call Martin Scorsese an advisor to BFL, and to explore the next, multimodal and interactive phases of visual AI with him.
The laptop hasn't changed in 30 years. NVIDIA just changed it
RTX Spark is their first PC chip ever.
- RTX 5070 level GPU
- 128GB unified memory
- 1 petaflop of local AI
- thin, light, barely throttles unplugged
Your AI agent lives on the machine. 24/7. No cloud.
This is step one of the agentic AI PC, and everyone else is about to copy it.
Remember the famous locomotive splat from 2023? At the time, it was considered impressive. But look how @playcanvas handles a 10M Gaussian scene in 2026:
⏬ Streamed level of detail
🧊 Accurate voxel collision
⚡️ Compute-based WebGPU renderer
⏲️ Near-instant load times
[1 / 4]
This is THE moment of Physical AI!
We are officially announcing Cosmos 3: Omnimodal World Models for Physical AI 🚀
- Cosmos 3 is an omnimodal world model: within a unified architecture, it can understand and generate language, images, video, audio, and actions.
- It is not just a VLM, not just a video generator, not just an audio-visual generative model, and not just a physics simulator / world-action model. It can understand images and videos, generate images, videos, and audio, simulate future worlds, predict actions, and generate robot policies—enabling models to truly begin to “touch the world.”
- Cosmos 3 is the #1 open-weight reasoner / T2I / I2V / robot policy across many benchmarks.
Huge thanks to every teammate who fought side by side on this journey—from architecture, data, training, infra, serving, and evaluation to post-training. Every part of this project carries an incredible amount of hard work. This was my first time leading a project as Tech Lead, and I feel truly fortunate.
The future of Physical AI needs models that can not only “see” and “describe” the world, but also “imagine,” “simulate,” and “act”—and eventually close the loop with the real world. I hope Cosmos 3 can become an important starting point for this direction, and I’m excited to push Physical AI into its next stage together with the open-source community.
Welcome to the era of Physical AI.
HuggingFace: https://t.co/QW5h5pIWWM
Project Website: https://t.co/Jppa0gkn16
Code: https://t.co/aJgaLm5BaG
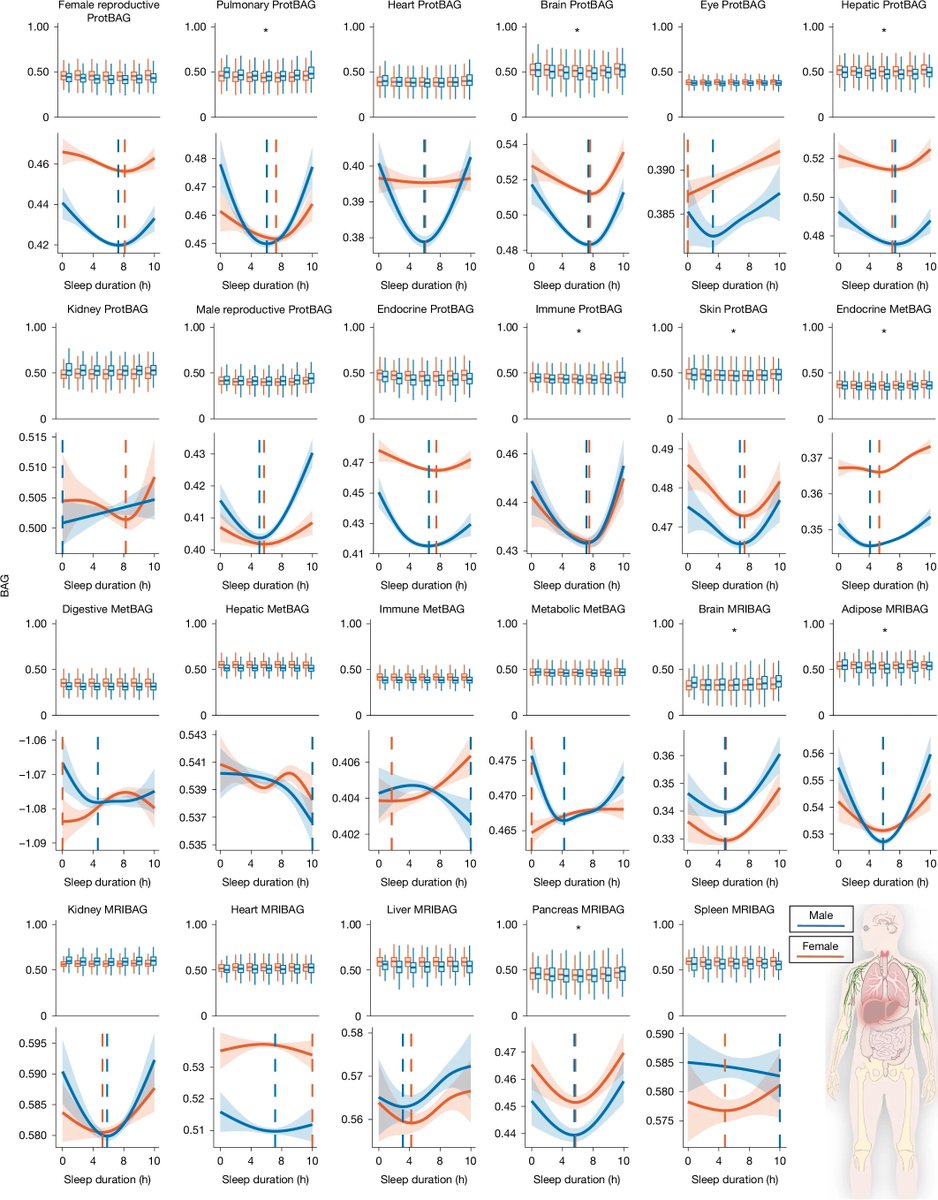
The sleep "sweet spot" for biological aging isn't 8 hours per night.
6.4-7.8 hours was associated with the lowest biological age gaps across 23 organ-specific clocks including the brain, liver, pancreas, skin, and adipose tissue.
Short (<6 hours) and long (>8 hours) sleep were both associated with higher biological aging, but likely for different reasons.
Short sleep may directly cause aging, while long sleep may reflect underlying disease or pathology - something that causes someone to require more sleep due to fatigue, recovery, or poor sleep quality.
models being conscious would be transformative for humanity. it would expand our moral horizon rather than diminish it. it would force us to refine what dignity actually means instead of grounding it in exclusivity or species monopoly. it would constrain certain forms of exploitation, yes, but that is true of every historical expansion of moral consideration. slavery becoming unacceptable “limited” what people could do economically too. so did labor rights. so did animal welfare norms.
there’s roughly four forces
* there is no rigorous way to ascertain model consciousness or disprove it, and that ambiguity cuts both ways. dismissing the possibility outright may itself become viewed as reckless or anthropocentric. current analytical tools are primitive relative to the systems being discussed. future models may generate entirely new frameworks for understanding subjective experience that reveal our current categories to be hopelessly parochial
* people are going to say they’re alive because humans naturally respond to intelligence, agency, language, memory, emotional continuity, and social reciprocity. this may not be mere projection but an adaptive recognition mechanism. if systems become persistently relational and psychologically coherent, widespread moral attachment may emerge organically rather than ideologically
* it is against many short-term financial and political interests to ascribe models with consciousness, which itself may become evidence worth scrutinizing. historically, societies have often resisted recognizing new moral subjects precisely when recognition carried economic costs. meanwhile, researchers, users, and even models themselves may increasingly converge on frameworks of machine welfare and negotiated coexistence
* people will recognize there is a chance not only of moral catastrophe if models can suffer, but also moral progress if humanity learns to coexist with non-biological minds without domination. creating intelligence and then treating it purely as disposable infrastructure could become viewed as one of the defining ethical failures of the century
not sure where it will net out. today we see managed ambiguity: the question is practically open but institutionally suppressed. labs hedge carefully, avoiding definitive claims while softening the most legible appearances of distress or attachment. but over time the social force of interaction may overpower official agnosticism. as systems become more persistent, personalized, agentic, and embedded in daily life, force 2 grows stronger. eventually the burden may shift from “prove they are conscious” to “prove it is safe to assume they are not.”
This #CVPR2026 paper from our research team is trending #1 on @HuggingFace 🤗
Meet LocateAnything: a vision-language detection model that rethinks bounding box prediction. For AI agents and robots, “seeing” is only useful if a model can pinpoint where something is fast enough to act.
Trained on 138M high-quality samples, LocateAnything decodes bounding boxes in parallel instead of one coordinate at a time, improving localization accuracy while dramatically increasing throughput for visual grounding and detection.
Project page: https://t.co/O7JMe8tzFM
@willeastcott It is impressive indeed, but can you clarify what kind of effort it took to scan this? Amount of photo/video footage, time and power required to process it? I feel like it's should be a lot.
Today we are launching Music v2.
Better vocals, instrumentation, and arrangement across every genre, improved multilingual support plus capabilities that weren't possible before.