🚨 Calling all @VanderbiltU employees!
Show your Vanderbilt ID for 2️⃣ 𝐅𝐑𝐄𝐄 tickets to our Elite Eight match against TCU Saturday at 6:30 p.m.
Help us 𝐏𝐀𝐂𝐊 𝐓𝐇𝐄 𝐏𝐋𝐄𝐗‼️
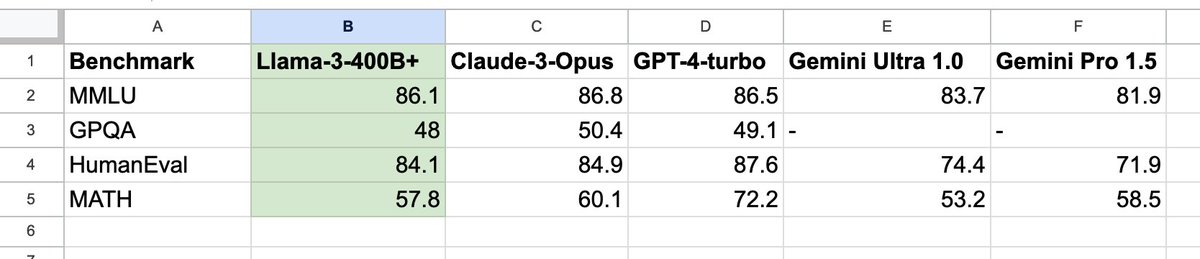
The upcoming Llama-3-400B+ will mark the watershed moment that the community gains open-weight access to a GPT-4-class model. It will change the calculus for many research efforts and grassroot startups. I pulled the numbers on Claude 3 Opus, GPT-4-2024-04-09, and Gemini.
Llama-3-400B is still training and will hopefully get even better in the next few months. There is so many research potential that can be unlocked with such a powerful backbone. Expecting a surge in builder energy across the ecosystem!
Very nice analysis on long context vs RAG. I believe the way of future will be “soft” methods that interpolate between pure retrieval and pure long context.
Some form of spreading neural activations across a giant unstructured database.
@ylecun Thrilling news that Llama-v2 is open source! and the variety of ways to train/inference is going to simplify the lives of so many in academia and industry alike. So many possibilities! Where to start??
@cwolferesearch Flash Attention v1 was groundbreaking, v2 is another huge advancement. Attention is at the heart of transformers, and is the key feature that gives them their remarkable capabilities. It’s also where the greatest challenge lies as it’s responsible the huge compute cost!
FlashAttention-2 was released today, which is 5-9X faster than vanilla attention and 2X faster than FlashAttention-v1. Given that many of the top open-source LLMs leverage FlashAttention, this is an important advancement that can make existing models much more efficient during both training and inference. Here’s what you need to know…
What is FlashAttention? In its canonical form, self-attention is an O(N^2) operation, where N is the length of the input sequence. Many proposals try to achieve an approximation of self-attention that runs in O(N) time, but they achieve no wall-clock speedup. FlashAttention reformulates attention in an IO-aware manner to achieve significant wall clock speedups, as well as an improvement in memory efficiency.
Lots of LLMs use it. Given that FlashAttention is very fast (i.e., ~2-4X faster) compared to a vanilla implementation, many transformer-based applications have adopted it. For example, recent open-source LLMs (such as Falcon and MPT models) use FlashAttention, leading them to be very fast at inference time (and more efficient during pre-training). For example, Falcon-40B is 5X faster at performing inference than GPT-3.
FlashAttention-2. A new update to FlashAttention has just been made available, called FlashAttention-2. This variant is about twice as fast as the original FlashAttention, and 5-9X faster than the original attention implementation. This improvement impacts both training an inference speed. The sources of these improvements are summarized by the quote below.
“We (1) tweak the algorithm to reduce the number of non-matmul FLOPs (2) parallelize the attention computation, even for a single head, across different thread blocks to increase occupancy, and (3) within each thread block, distribute the work between warps to reduce communication through shared memory.” - from FlashAttention-2 paper
The only caveat. Currently, the FlashAttention-2 implementation does not apply to all GPUs. However, the GPUs to which it does apply see a significant benefit; e.g., a 225 TFLOPs/s training speed can be achieved on an A100 using FlashAttention-2.
Scientists led by Vanderbilt astronomer Stephen Taylor have identified evidence of slowly undulating #GravitationalWaves passing through our galaxy.
Learn more about VU researchers' contributions to the exciting @NANOGrav findings: https://t.co/ihJjTYB4PS
Assistant Prof Alvin Jeffery was accepted into a NIDA-sponsored entrepreneurial program at the intersection of #informatics, software development, #genetics and substance use disorder called L-SPRINT @babson College. @UCDavisHealth@NIDAnews
The license of the Falcon 40B model has just been changed to… Apache-2 which means that this model is now free for any usage including commercial use (and same for the 7B) 🎉
In-context learning as the mysterious ability in LMs.
We propose ✨Deep-thinking✨ to boost ICL by iterative forward tuning.
It is possible to tune LMs without backpropagation! 🤯
Paper: https://t.co/vX1BdqwOCe
Gradio Demo: https://t.co/okQK7mxMgB
QLoRA: 4-bit finetuning of LLMs is here! With it comes Guanaco, a chatbot on a single GPU, achieving 99% ChatGPT performance on the Vicuna benchmark:
Paper: https://t.co/J3Xy195kDD
Code+Demo: https://t.co/SP2FsdXAn5
Samples: https://t.co/q2Nd9cxSrt
Colab: https://t.co/Q49m0IlJHD
The first RedPajama models are here! The 3B and 7B models are now available under Apache 2.0 license, including instruction-tuned and chat versions!
This project demonstrates the power of the open-source AI community with many contributors ... 🧵 https://t.co/msO4afBQEK