This release from AI2 allows you to extract small language models from the LLM for your specific task, without any additional training simply by selecting the subset of experts which are relevant. This is an amazing unlock for memory constrained local inference.
Today we’re releasing EMO, a new mixture-of-experts (MoE) model trained so modular structure emerges directly from data without human-defined priors.
EMO can use a small subset of its experts for a given task while keeping near full-model performance. 🧵
@Hacubu Exa is an optional add-on via Cloud's Agent Marketplace. This is not a change in any default grounding, which will continue to use Google Search :)
Terence Tao proposes what he calls a "Copernican view of intelligence".
Instead of buying into the common, one-dimensional narrative that artificial intelligence will simply evolve from "subhuman" to "superhuman" and ultimately make humanity entirely redundant, Tao urges us to look at the bigger picture.
Much like the Copernican revolution proved the Earth is not the center of the universe, Tao suggests we need to realize that human intelligence isn't the only, or necessarily the highest, form of intellect. Historically, we have treated other forms of storing or creating knowledge—like animals, books, and computers—as secondary. However, we actually exist within a much richer universe of intelligence.
Both human intelligence and computer intelligence possess their own distinct strengths and weaknesses. The true potential lies not in viewing them as direct competitors, but rather in focusing on collaboration. By working together, humans and computers can achieve additional things that neither could accomplish on their own, requiring us to think in much wider terms than just what humans or computers can do alone.
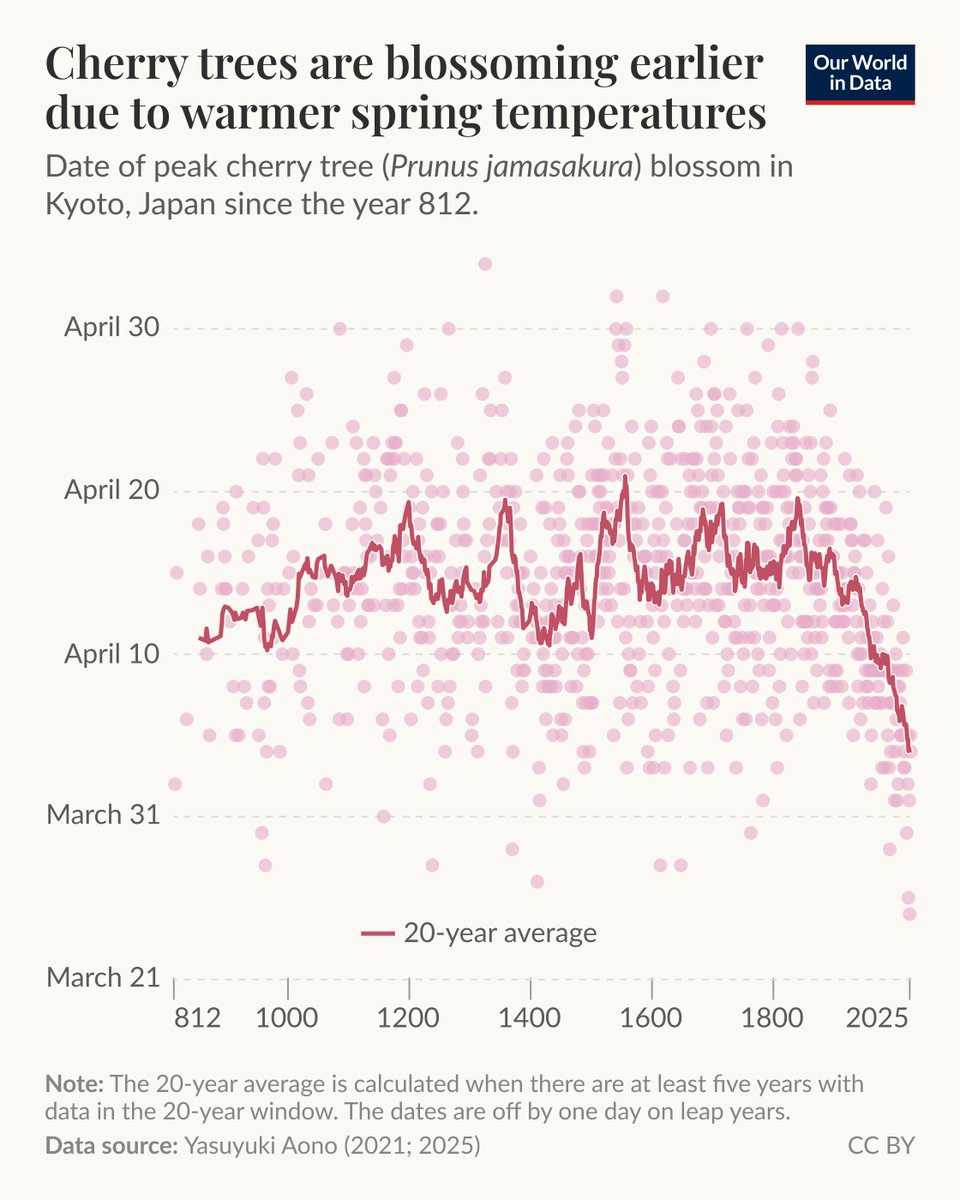
I'm a data scientist @OurWorldinData and I need help from a botanist or someone local to Kyoto, Japan! 🌸
We present one of the world’s longest climate records: 1,200 years of peak cherry blossom dates in Kyoto.
The researcher who maintained it, Professor Yasuyuki Aono, sadly passed away last year.
@ericweinstein I think you should listen to the episode because you are agreeing with what Terence actually said and disagreeing with the confused Twitter take.
LiteLLM HAS BEEN COMPROMISED, DO NOT UPDATE. We just discovered that LiteLLM pypi release 1.82.8. It has been compromised, it contains litellm_init.pth with base64 encoded instructions to send all the credentials it can find to remote server + self-replicate. link below
Generative thermodynamic computing
Diffusion models are powerful generative tools, but they come with a hidden cost: every denoising step requires a digital neural network, artificially injected noise, and substantial energy consumption. Yet physics offers an alternative—what if the noise needed for generation arose naturally from thermal fluctuations, and the denoising process was physically enacted rather than simulated?
Stephen Whitelam introduces exactly this: a generative modeling framework for thermodynamic computing. Instead of using neural networks to transform noise into structure, the approach encodes denoising information directly in the energy landscape of a physical system evolving under Langevin dynamics.
The training principle is elegant: observe noising trajectories (structured data degrading into noise), then adjust the system's couplings via gradient descent to maximize the probability that a thermodynamic computer would generate the reverse—structure from noise. This process has a beautiful physical interpretation: it minimizes the heat emission and entropy production of the generative process.
In a proof-of-concept simulation with 784 visible units and 512 hidden units trained on just three MNIST digits, the thermodynamic computer learns to transform noise into recognizable digit-like structures through physical dynamics alone—no external control or pseudorandom numbers required.
The energy implications are striking: the simulated thermodynamic computer emits ~2,900 kᵦT of heat per generation, compared to ~5 × 10¹⁴ kᵦT for a digital neural network doing equivalent denoising—a difference of more than 10 orders of magnitude.
The message is compelling: by grounding generative modeling in thermodynamic principles, we can design systems where computation emerges from physics itself, opening paths toward autonomous, energy-efficient generation that could fundamentally change how we think about the hardware of machine learning.
Paper: https://t.co/c8vLmgnLZ8
How to become expert at thing:
1 iteratively take on concrete projects and accomplish them depth wise, learning “on demand” (ie don’t learn bottom up breadth wise)
2 teach/summarize everything you learn in your own words
3 only compare yourself to younger you, never to others