[3/3] I’m also grateful for the wonderful mentoring by @johntzwei, @ameya_godbole1 and @robinomial! I learned a lot from this project and am really thankful for their guidance throughout. 🎉
[1/3] Excited to finally share what I’ve been working on the past few months! Spiking intentionally contaminates training data to measure test set contamination. We show it can estimate contamination and adjust test scores for a more truthful evaluation.
🧵[1/5] Works on test set contamination focus on detection, but we show *correction* of inflated test scores is possible. https://t.co/7D6lr63d40
Our proposal is to spike the training data and insert some test examples at known rates. The spiked examples are used to calibrate...
[2/3] @johntzwei and I believe spiking opens a new direction for model evaluation for devs/labs. In the age of internet-scale training data, building robust models across a multitude of domains and environments starts with accurately measuring what our current models can truly do
🧵[1/5] Works on test set contamination focus on detection, but we show *correction* of inflated test scores is possible. https://t.co/7D6lr63d40
Our proposal is to spike the training data and insert some test examples at known rates. The spiked examples are used to calibrate...
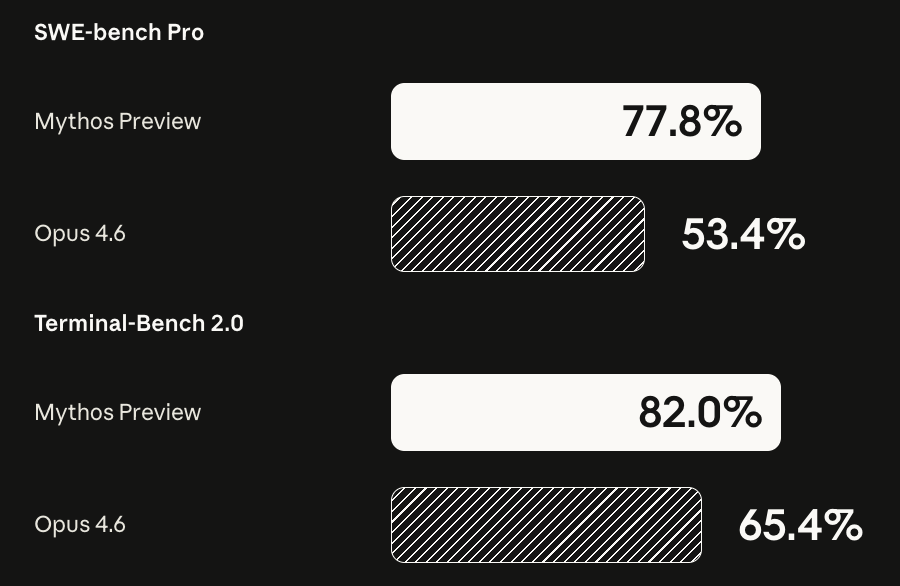
Great to see Thinking Machines taking a slightly different route instead of just trying to compete with the other big players in the LLM space (Meta).
And what’s even better is a technical report with details on their architecture! Was bearish before on TM but more excited now.
People talk, listen, watch, think, and collaborate at the same time, in real time. We've designed an AI that works with people the same way.
We share our approach, early results, and a quick look at our model in action.
https://t.co/AFJZ5kH7Ku
People talk, listen, watch, think, and collaborate at the same time, in real time. We've designed an AI that works with people the same way.
We share our approach, early results, and a quick look at our model in action.
https://t.co/AFJZ5kH7Ku
@awnihannun Contextual token compaction is pretty good but in the long run it’ll always be capped by whatever the models capabilities are. More people should probably be focused on figuring how to do local updates within the model weights without being overly expensive like full backprop
Instead of forcing models to hold everything in an active context window, we can use hypernetworks to instantly compile documents and tasks directly into the model's weights. A step towards giving language models durable memory and fast adaptation.
Blog: https://t.co/iHoifpsLMu
We discovered an emergent property of VLAs like π0/π0.5/π0.6: as we scale up pre-training, the model learns to align human videos and robot data!
This gives us a simple way to leverage human videos. Once π0.5 knows how to control robots, it can naturally learn from human video.
We’ve developed a new way to train small AI models with internal mechanisms that are easier for humans to understand.
Language models like the ones behind ChatGPT have complex, sometimes surprising structures, and we don’t yet fully understand how they work.
This approach helps us begin to close that gap.
https://t.co/g4zOcdezPU