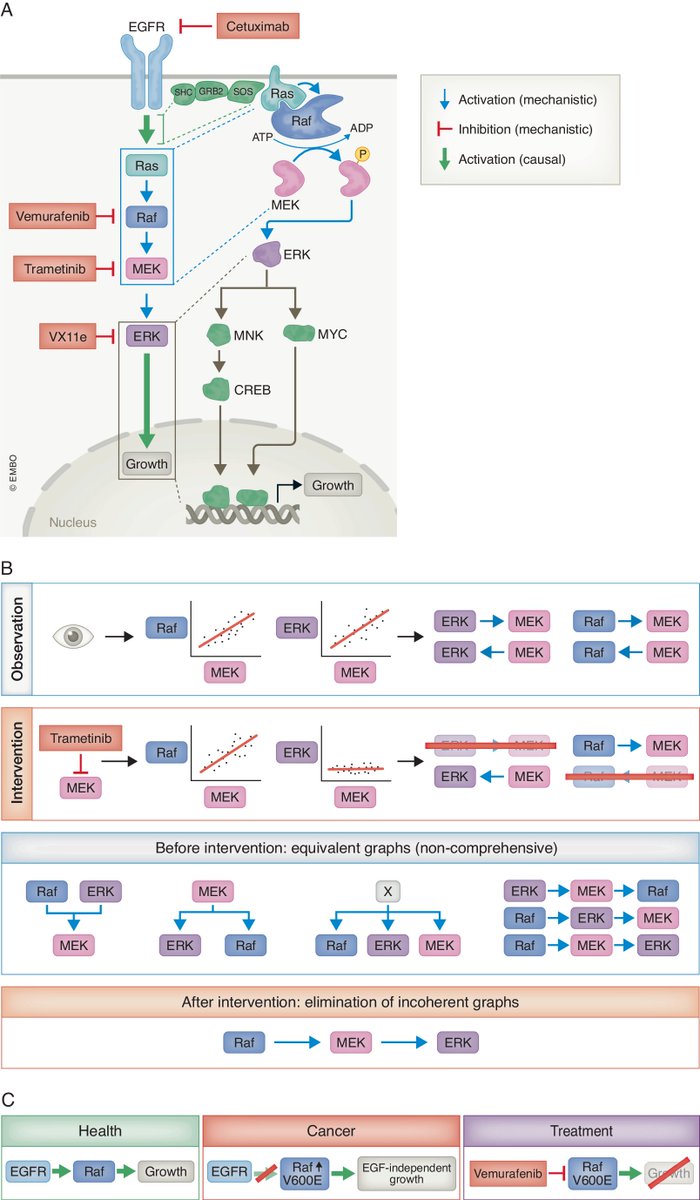
Correlation is not causation. In our new perspective, we connect systems biology, causal reasoning, and machine learning to inform future approaches in systems biology and molecular medicine in the wake of current deep learning advances: https://t.co/8OSgbmR93M 🧵👇
🌟Announcing "Lineax" - our newest #JAX library! For fast linear solves and least squares.
GitHub: https://t.co/KT0vNa6tta
* Fast compile time
* Fast runtime
* Efficient new algorithms (e.g. QR) + existing ones (GMRES, LU, SVD, ...)
* Support for general linear operators🔥
1/
(1/n) some thoughts about foundation models for single-cell biology upon publication of an interesting paper (geneformer) today in @Nature introducing a foundation model trained on 30M cells with cool applications https://t.co/el9J81Ojiv
Crick to Watson: “I must also point out to you, once again, the risks you will run if you publish such a book. The picture which emerges of yourself is not only unfavourable but misleadingly so. Moreover I do not think you realize what others will see in it.”
Re: the history of the DNA structure, see this blistering 1967 letter from Crick to Watson objecting to the draft of Watson’s book on their work. “...it shows such a naive and egotistical view of the subject as to be scarcely credible.” https://t.co/nDeb0UfDYH
How can we learn to rapidly compose new genetic circuits?
In a new essay, I explore recent work from the frontier of ML-driven biodesign 🧬
We're expanding from models of genetic parts, to models of genetic circuits:
Thought experiment: If we sequenced every butterfly species on earth, would we have enough data for a generative ML model for butterfly genomes?
What if we sampled 100 individual genomes from every species? What if we sequenced all the other insects too? What would it take?
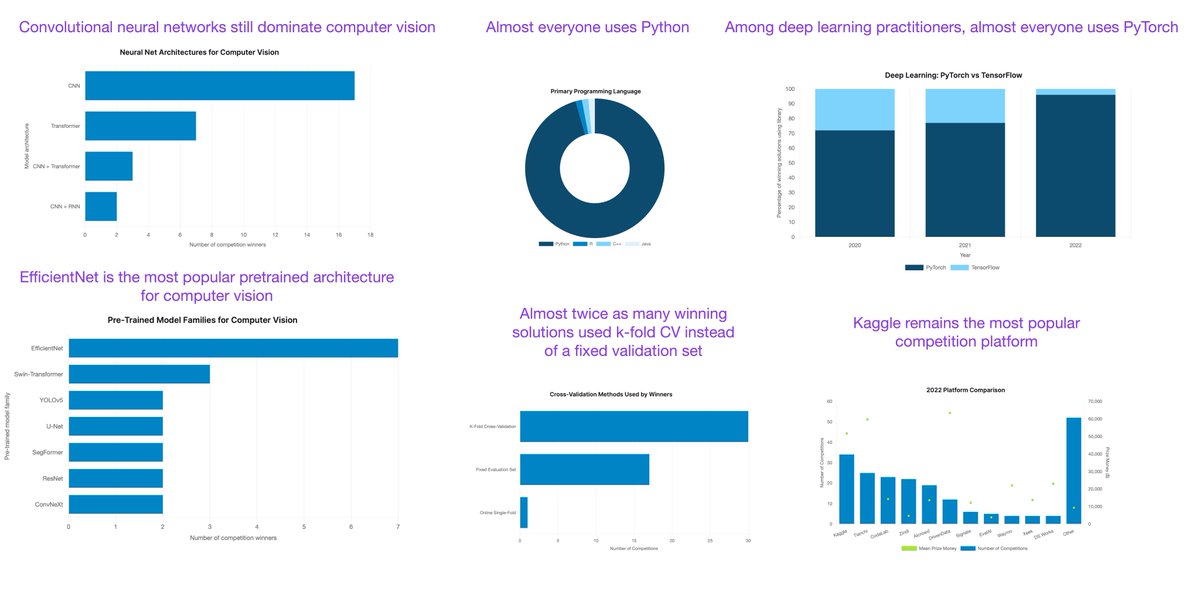
Machine learning competitions are often a good indicator of what techniques actually work well in practice on new datasets.
The very comprehensive State of Competitive Machine Learning 2022 report just came out and contained many interesting and surprising insights!
1) As expected, transformers dominate natural language processing (NLP). ALL NLP-related winning solutions used transformers.
2) Convolutional neural networks still dominate computer vision. And EfficientNet is the most popular pretrained architecture for computer vision -- most people finetune pretrained models rather than training from scratch.
3) Almost twice as many winning solutions used k-fold CV instead of a fixed validation set.
4) Kaggle (barely) remains the most popular competition platform.
5) Almost everyone uses Python.
6) Out of 46 winning solutions using deep learning, 44 used PyTorch, and only 2 used TensorFlow.
7) A big surprise for tabular competitions: the reign of XGBoost seems over. While gradient boosting still wins most tabular competitions, LightGBM is now the preferred approach, with CatBoost coming in second. XGBoost is third.
8) Winning solutions of 7 out of the 10 tabular competitions used gradient boosting, 5 out of 10 used deep neural networks (implemented in PyTorch), and most winning solutions were ensemble methods.
Here's a link to the full report: https://t.co/p9dleTZ80R
As a casual reminder to reviewers and authors: if you are working on a biology task and you use random cross-validation, you are making a mistake. It's truly disheartening to review a paper and see this because you have no idea just how distorted the results are.
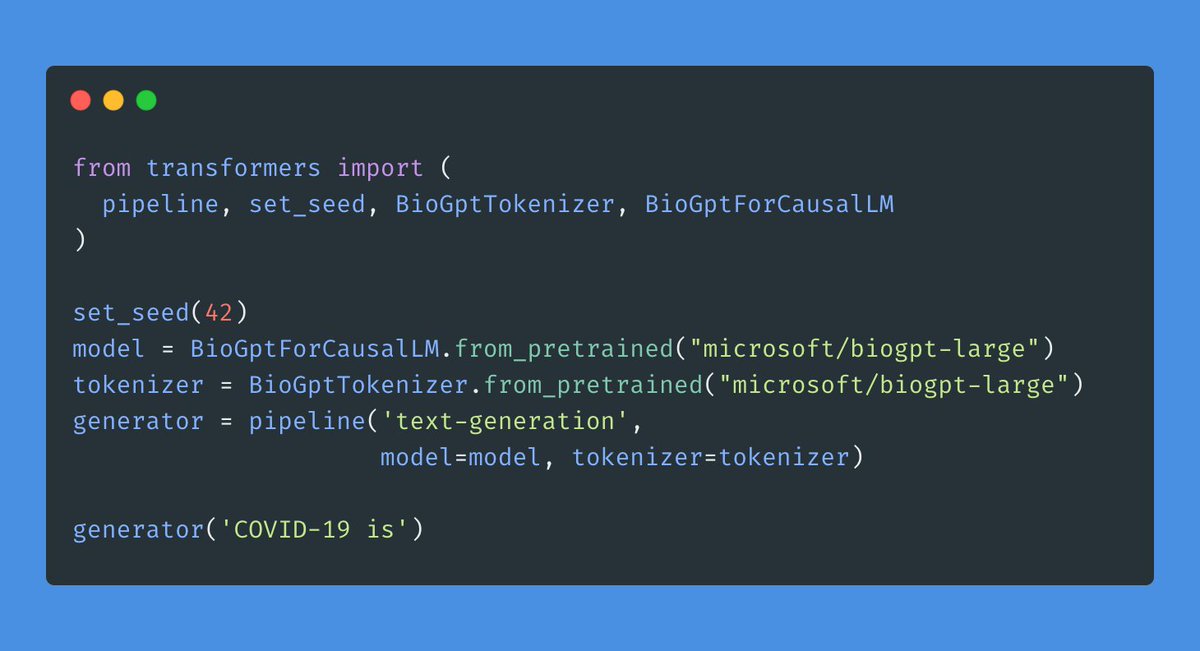
BioGPT-Large was just released by Microsoft 🤩
Trained from scratch on biomedical text, it's the current leader on the PubMedQA benchmark at 81% accuracy (human performance = 78%).
It's also freely available on the @huggingface hub to try out (and fine-tune)!