Joachim works since 15y as dev. and consultant for software systems, architecture and processes. He's doing a PhD at Institute of Theoretical Physics in Ulm.
⟳ We updated #ERPL extension to 🦆 @DuckDb v1.3.1 bugfix release. (Now available for v.1.3.0 and v.1.2.2). #ERPL connects 🦆 @DuckDB to #SAP ecosystem via standard interfaces:
https://t.co/Z25xFnfJC6
@duckdb@polars@spark@snowflake Benchmarks https://t.co/VdmK1bDxIy Show This:
→ @DuckDB beats @Spark for small queries.
→ Even at 700GB, DuckDB (native files) is competitive.
→ Spark scales dynamically for 1TB+ workloads.
🔍 The lesson? If data fits a single-node go for it.
Scale to MPP only when needed.
MPP vs. Single-Node Engines
Small workloads? Use @DuckDb or @Polars for faster in-memory performance.
Massive datasets? MPP systems like @Spark or @Snowflake scale dynamically.
Experiment: @DuckDB outperformed Spark at <100GB
💡 Don't drive groceries shopping with a tank!
Why Are Object Stores So Attractive?
1️⃣ Scalability: Handle massive amounts of data.
2️⃣ Flexibility: Open formats like Iceberg for interoperability.
3️⃣ Advanced Features: Replication, immutability, and consistency.
They became the backbone of modern distributed systems.
The Future of Distributed Systems
Object storage like Amazon S3 has become a primary database—scalable & efficient for transactional & analytical workloads.
Emerging programming models:
1️⃣ Distributed DBs
2️⃣ Serverless
3️⃣ Wasm
The Iceberg Effect
Modern data is evolving:
→ Iceberg now leads open table formats (Snowflake & Databricks adoption confirms it).
→ Cloud-native storage is a must (legacy systems won’t keep up).
→ AI thrives on scalable, open architectures.
More innovation. Less lock-in.
Curious where the data comes from?
🔗 Snowset (Snowflake's dataset): https://t.co/vP40KU1d2z
🔗 Redset (Redshift's dataset): https://t.co/U0FYC1qpTO
Both share real-world query samples, packed with insights into how data warehouses are used. Check them out!
What Do Data Warehouses Really Do?
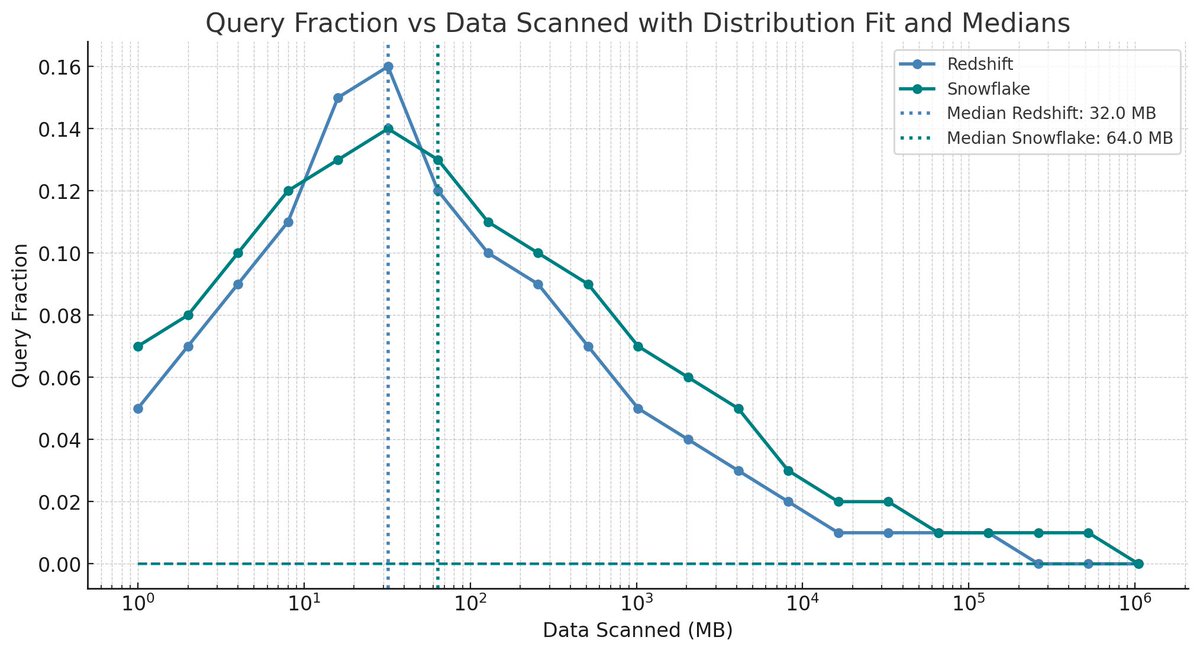
→ $300K/year on Snowflake, and 90% is spent on queries.
→ Most queries are tiny (median: 100MB, 99.9% <300GB).
→ Most workloads = ingestion + transformation (not analytics).
💡 Small Data > Massive Complexity.
We overpay for simplicity?
Think Small. Make Big Impact.
More Data ≠ Better Results.
→ Recent data is the most valuable.
→ Smaller AI models deliver bigger impact.
→ Local-first development works.
Stop relying on distributed complexity when single machines get the job done.
#SmallData. Are you in?
#BigData isn’t the problem—it never was.
Most enterprises have <100GB in active data but overpay for tools designed for massive scale (#Snowflake, #Databricks, etc.).
Focus on #SmallData:
→ Easier to analyze
→ Cheaper to manage
→ Faster insights
Time for #SmallData
@matsonj Thank you @matsonj for mentioning our work! In good old europe a lot of data projects in enterprises start and end in a SAP system. So it it was quite natural to try to eliminate the typical #databricks, #snowflake or #Excel file mess in between.
@illyism The mechanism is super powerful. We created an extension to transparently load data from #SAP into #duckdb. If one is interested: https://t.co/Nr4UB5YaNL
@duckdb Very cool 😎! Our extension to load data from #SAP ERP, BW or #ODP is ready for 1.0.0. Find out more at https://t.co/Nr4UB5YaNL. DuckDB, the data ecosystem of the future.
@duckdb@mraasveldt Great news from @duckdb on multi-database support! For those in #SAP environments, our ERPL extension
offers seamless integration into the SAP Business Warehouse, data replication with ODP or simply reading tables and calling RFC functions. Check out https://t.co/Nr4UB5XCYd
So excited to finally have the (restricted) beta of our Intuitive Bayes introductory course out (https://t.co/jJIT1xytu8), a long time in the making. Cool to see how people resonate with our code first approach and even come up with memes themselves for it (HT @robertmitchellv).