Can large language models (LLMs) act as the imagination of a reinforcement learning (RL) agent?
We found that if you let an LLM "dream" - not by hallucinating pixels, but by writing executable Python code - it can create an open-ended curriculum that drives progress in complex, long-horizon worlds.
Introducing Dreaming in Code (DiCode). 🧵👇
As a scientist doing fundamental research, we often hope that our research ends up impacting many different scientific disciplines and peoples' lives. Here's a fantastic example of that dream coming true. AlphaEvolve's paper mentions it is inspired by MAP-Elites, and look at all the amazing things that it does in so many different fields! cc @jb_mouret
Can large language models (LLMs) act as the imagination of a reinforcement learning (RL) agent?
We found that if you let an LLM "dream" - not by hallucinating pixels, but by writing executable Python code - it can create an open-ended curriculum that drives progress in complex, long-horizon worlds.
Introducing Dreaming in Code (DiCode). 🧵👇
Happy to share our paper "Getting robots back on track by reconstituting control in unexpected situations with online learning" is now out in Nature Communications.
Joint work with @allardmaxime079, @bryanlimwt, and @CULLYAntoine.
Excited to show our latest work on resilient robotics! 🚀🤖 Our new Nature Communications paper introduces FLAIR, a method that learns online, on-device, in 225ms, how to compensate for unseen perturbations affecting a robot.
📄https://t.co/p2osVEQsjM
🎥 https://t.co/ozX2p10vSM
🤖Thrilled to share that robotics work from my PhD is out in @NatureComms 🎉
"Getting robots back on track by reconstituting control in unexpected situations with online learning"
With @MFlageat , @bryanlimwt , @CULLYAntoine@imperialcollege
🧵below
Imagine every pixel on your screen, streamed live directly from a model. No HTML, no layout engine, no code. Just exactly what you want to see.
@eddiejiao_obj, @drewocarr and I built a prototype to see how this could actually work, and set out to make it real. We're calling it Flipbook. (1/5)
After one week in London, I’ve become increasingly convinced that the intersection of continual learning and open ended discovery may be the most important topic to explore for the next decade.
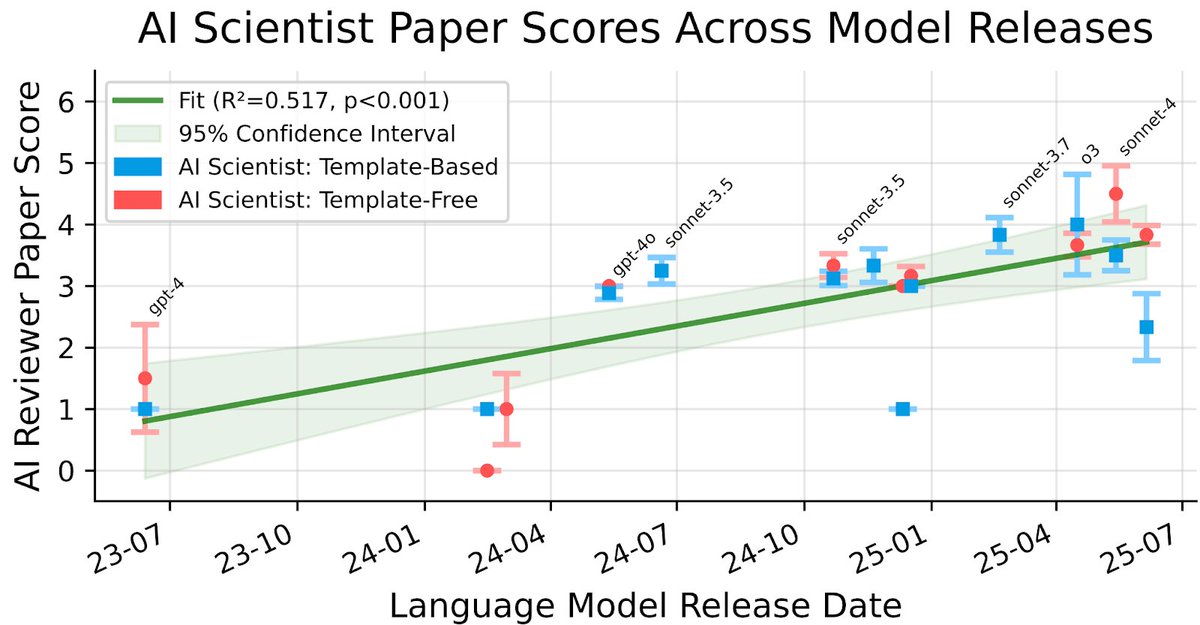
I am really excited to share that our work on The AI Scientist has been published in Nature
Automated Scientific Discovery has been something I only dreamt about at the start of my PhD. Today, we are making big leaps into a world in which autonomous agents support human researchers in tackling some of the most fundamental problems.
In August 2024, The AI Scientist-v1 showed first sparks of LLM agents becoming capable of conducting research end-to-end. While the generated artifacts were still far from perfect, it was clear that automated discovery was about to change. We scaled the system and improved all ingredients of the pipeline. In April 2025, The AI Scientist-v2 had become capable of producing a paper that could pass the human peer review of an ICLR workshop.
This is only the beginning. Systems like AlphaEvolve, ShinkaEvolve, AIDE, and Autoresearch will continue to shape the future of how research is conducted. Our METR-style scaling results indicate that model improvements have direct downstream impacts. Still, there are many challenges. Both technical and societal. I have a strong belief that we, as a collective, will find the answers and adapt.
This has been an enormous amount of work by an outstanding set of human researchers @_chris_lu_@cong_ml@_yutaroyamada@shengranhu@j_foerst@jeffclune@hardmaru@SakanaAILabs with many long nights of work. I am super grateful for the entire ride, learnings and the future to come. Thank you to everyone!
The AI Scientist: Towards Fully Automated AI Research, Now Published in Nature
Nature: https://t.co/nNfpSV5e5I
Blog: https://t.co/i6h8LVQOdl
When we first introduced The AI Scientist, we shared an ambitious vision of an agent powered by foundation models capable of executing the entire machine learning research lifecycle.
From inventing ideas and writing code to executing experiments and drafting the manuscript, the system demonstrated that end-to-end automation of the scientific process is possible.
Soon after, we shared a historic update: the improved AI Scientist-v2 produced the first fully AI-generated paper to pass a rigorous human peer-review process.
Today, we are happy to announce that “The AI Scientist: Towards Fully Automated AI Research,” our paper describing all of this work, along with fresh new insights, has been published in @Nature!
This Nature publication consolidates these milestones and details the underlying foundation model orchestration. It also introduces our Automated Reviewer, which matches human review judgments and actually exceeds standard inter-human agreement.
Crucially, by using this reviewer to grade papers generated by different foundation models, we discovered a clear scaling law of science. As the underlying foundation models improve, the quality of the generated scientific papers increases correspondingly. This implies that as compute costs decrease and model capabilities continue to exponentially increase, future versions of The AI Scientist will be substantially more capable.
Building upon our previous open-source releases (https://t.co/H1tBT14Yx8), this open-access Nature publication comprehensively details our system's architecture, outlines several new scaling results, and discusses the promise and challenges of AI-generated science.
This substantial milestone is the result of a close and fruitful collaboration between researchers at Sakana AI, the University of British Columbia (UBC) and the Vector Institute, and the University of Oxford. Congrats to the team!
@_chris_lu_@cong_ml@RobertTLange@_yutaroyamada@shengranhu@j_foerst@hardmaru@jeffclune
Introducing Hyperagents: an AI system that not only improves at solving tasks, but also improves how it improves itself.
The Darwin Gödel Machine (DGM) demonstrated that open-ended self-improvement is possible by iteratively generating and evaluating improved agents, yet it relies on a key assumption: that improvements in task performance (e.g., coding ability) translate into improvements in the self-improvement process itself. This alignment holds in coding, where both evaluation and modification are expressed in the same domain, but breaks down more generally. As a result, prior systems remain constrained by fixed, handcrafted meta-level procedures that do not themselves evolve.
We introduce Hyperagents – self-referential agents that can modify both their task-solving behavior and the process that generates future improvements. This enables what we call metacognitive self-modification: learning not just to perform better, but to improve at improving.
We instantiate this framework as DGM-Hyperagents (DGM-H), an extension of the DGM in which both task-solving behavior and the self-improvement procedure are editable and subject to evolution. Across diverse domains (coding, paper review, robotics reward design, and Olympiad-level math solution grading), hyperagents enable continuous performance improvements over time and outperform baselines without self-improvement or open-ended exploration, as well as prior self-improving systems (including DGM). DGM-H also improves the process by which new agents are generated (e.g. persistent memory, performance tracking), and these meta-level improvements transfer across domains and accumulate across runs.
This work was done during my internship at Meta (@AIatMeta), in collaboration with Bingchen Zhao (@BingchenZhao), Wannan Yang (@winnieyangwn), Jakob Foerster (@j_foerst), Jeff Clune (@jeffclune), Minqi Jiang (@MinqiJiang), Sam Devlin (@smdvln), and Tatiana Shavrina (@rybolos).
If AI will soon match any human cognitive skill, then enhancing your “AI skills” (or whatever similar meme) will not be a moat because using AI is itself a cognitive skill. So where’s your edge? The only thing you really have over AGI is your novelty: AGI can never be you.
You have 100 trillion connections in your brain. That’s a lot. No AI will ever precisely replicate those parameters. The training data isn’t there for AI to vacuum up because you are the only entity ever to live your life, and the only one who ever will.
The question is whether the sum and total of all that experience yields a novel perspective, where the value is in its uniqueness. Even today those who make a living off their perceived novelty tend to be the most successful. We anticipate a novel (yet often internally consistent) take from a public figure or leader or artist or intellectual we like or respect. Uniqueness and novelty will retain their edge in a post-AGI world because there are virtually infinite possible 100-trillion parameter minds, and even the largest model theoretically conceivable can never capture that whole distribution.
At the same time, the once-sterling premium of those skills that no longer make us unique is sinking. Expertise that once distinguished people, like how to code, is losing its edge. But the tricky part is that new skills, like “using AI effectively” are equally vulnerable. All of it just takes intelligence, and that’s the thing that’s being automated. Seeking some new “safe” skillset is a looming adventure in frustrating futility.
But what’s still left is your unique perspective. Novelty. No one and nothing can see the world through your eyes. But you have to nurture that uniqueness. Post-AGI, being like everyone else would be the real danger.
Thrilled to be featured in the first ALife Newsletter of the year! I share about how I got into open-endedness research, the inspiration behind my recent work, and how I think open-endedness fits into the future of AI and AI researchers
A lot of the current discourse about AI comes from a fatalistic position of total surrender of agency: "tech is moving in this direction and there's nothing anyone can do about it" (suspiciously convenient for those who stand to benefit most)
But in a free society, we get to choose what kind of world we live in, independent of technological capabilities. Just because tetraethyllead made engines run more efficiently and saved money didn't mean we were *obligated* to pump it into the lungs of our kids
Technological determinism is BS. We have a collective duty to make sure AI adoption improves the human condition, rather than hollows it out
@JozsefSzalma Thank you Jay! Yes, I agree. Unless the LLM (or any other experience generator) can continuously self-improve alongside the agent’s capabilities, its ability to identify gaps will eventually become the ceiling as the agent reaches superhuman performance.
Can large language models (LLMs) act as the imagination of a reinforcement learning (RL) agent?
We found that if you let an LLM "dream" - not by hallucinating pixels, but by writing executable Python code - it can create an open-ended curriculum that drives progress in complex, long-horizon worlds.
Introducing Dreaming in Code (DiCode). 🧵👇
@AlberFuen Yes, absolutely! Both Ollama and llama.cpp provide standard OpenAI-compatible endpoints natively, and thus DiCode supports them right out of the box.
All you need to do is set your LLM provider to "local", specify your local "base_url", and pass in the model name in config.
Excited to share our latest work with @k_mitsides and @maxencefaldor: DiCode - Dreaming in Code!
Imagining new situations is a great way to learn, and when we are dealing with virtual environments we can do it in code: using LLM to generate new environments to help the training!