Our white paper just came out on Arxiv https://t.co/HcSCepvXfM. We open-sourced it all https://t.co/lfySRERfeQ. Our project website also has links to the white paper, the weights, and more videos https://t.co/DRnViyXRWz
Releasing VLA Foundry: an open-source framework that unifies LLM, VLM, and VLA training in a single codebase. End-to-end control from language pretraining to action-expert fine-tuning — no more stitching together incompatible repos.
ReFiNe expands on a neat idea we first presented at CoRL with Recursive Octree Auto-Decoders: that recursion can enable very high compression rates of 3D data. In ReFiNe, we use this property to represent continuous fields and can decode multiple NeRFs/SDFs with a single network.
Excited to introduce our paper, ReFiNe, at #SIGGRAPH2024 this Thursday! Learn how we encode multiple assets as continuous neural fields with high precision & low memory usage by exploiting object self-similarity.
@RaresAmbrus@robo_kat@adnothing
Webpage: https://t.co/JoSqVTIDBr
@ke_huang275@achalddave Though it is difficult to say why benchmarks got better with IT, my speculation is this is due to the DCLM-IT data, as it contains datasets such as Nectar, no_robots, StarCoder2-Self-OSS-Instruct, which have math, code, QA data that might help improve the benchmarks performance.
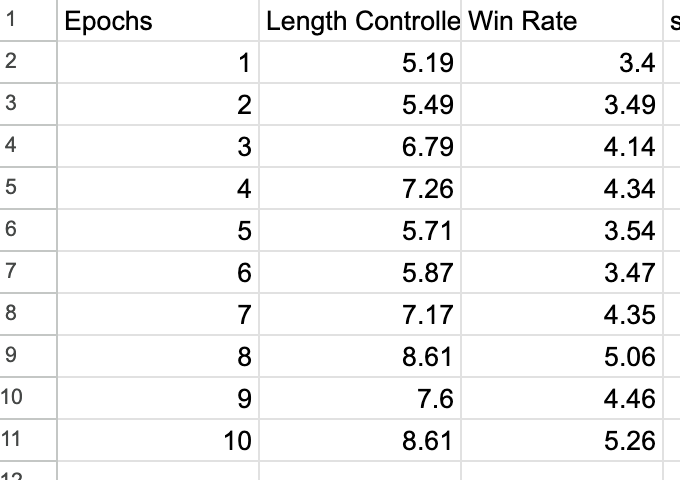
@ke_huang275@achalddave@ke_huang275 We trained for 10 epochs as we saw AlpacaEval score improving beyond first few epochs. So, we decided to keep fine-tuning.
Here is how the AlpacaEval looked for each epoch:
I am looking for positions in LLM based agents, and combining planning and learning techniques/systems.
I have around 2.5 years of industry research including two years at @PARCinc as a research scientist and multiple summer intern positions @amazon@alexa99. 1/6
Building language models is difficult and requires high quality preprocessing, modeling, evaluation and large scale training.
As significant collaborators in this project at TRI, the resulting 7B model DCLM-7B is a significant achievement. It is a competitor to Mistral 7B and LLaMA-7B, even though trained on less data. And it’s fully open. And that’s just the start of the competition.
Excited to see how others leverage these results to build even more capable language models and improve dataset quality.
One thing I have come to greatly appreciate over the last year is the role of data filtering in building SOTA language models.
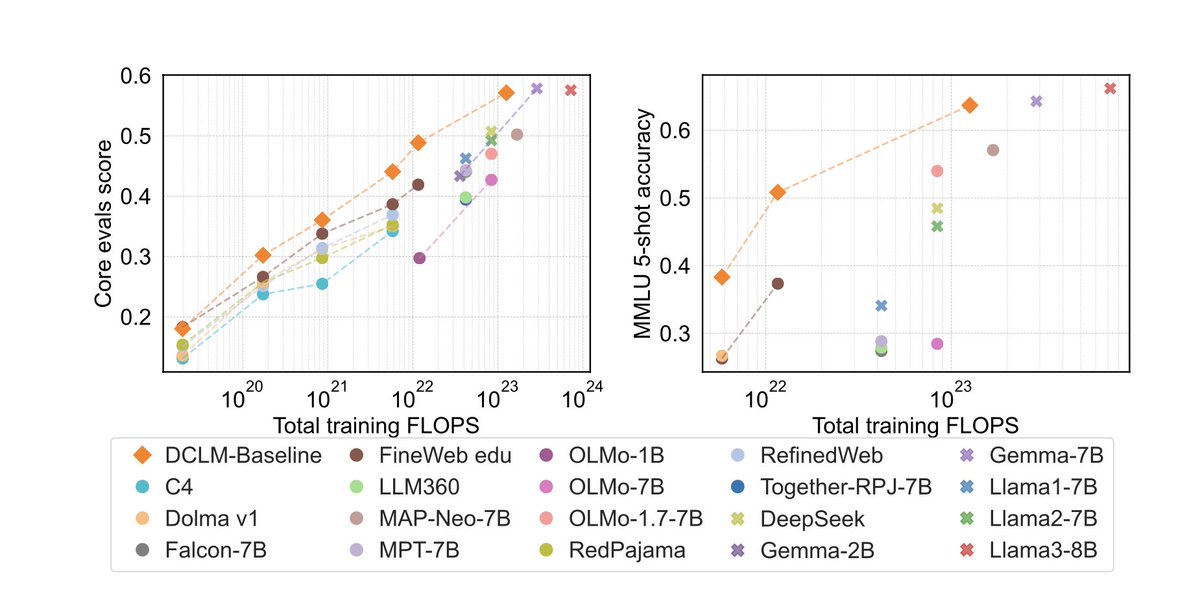
DCLM introduces a filtered 240T dataset, a 7B open-source model that is competitive w/ Llama3 with 2-6x fewer tokens & a pipeline to build new datasets.
I am really excited to introduce DataComp for Language Models (DCLM), our new testbed for controlled dataset experiments aimed at improving language models. 1/x
DataComp-LM: In search of the next generation of training sets for language models
- Provides a corpus of 240T tokens from Common Crawl
- Trains a LM using their filtered dataset, which performs similarly on NLU tasks w/ 6.6x less compute than Llama 3 8B
proj: https://t.co/soBq1ZnAwT
abs: https://t.co/r8nWIHwq1t
Check out DataComp for language models! Open data, open code, open training recipe, and close to Llama3-8B performance. This has been a labor of love over the last year, a huge thanks to all the collaborators for helping make this happen!
I am really excited to introduce DataComp for Language Models (DCLM), our new testbed for controlled dataset experiments aimed at improving language models. 1/x
Sedrick is an amazing researcher and has done amazing work on pre-training, scaling, evaluation, Japanese LMs, code models, VLMs, and more in the last year. If you are at NAACL, do get a coffee with him!
Recurrent models like RWKV and Mamba have gained attention recently, but these can be costly to train and iterate on.
What if we could simply...
turn Mistral/Llama/Gemma into an RNN? 🎩🪄
Presenting our work, Linearizing Large Language Models!
https://t.co/hbaSUWk8uc
A really large in-the-wild robotics dataset from TRI colleagues And university partners, a major step in the direction of building Robotics Foundation Model.
After two years, it is my pleasure to introduce “DROID: A Large-Scale In-the-Wild Robot Manipulation Dataset”
DROID is the most diverse robotic interaction dataset ever released, including 385 hours of data collected across 564 diverse scenes in real-world households and offices