Meet LA-Pose. Our latest model taking Wayve another step towards generalization at scale.
LA-Pose employs large-scale self-supervised learning, building strong motion representations for 3D perception from 10.2 million unlabeled driving video snippets, unlike today's strongest approaches that often depend on expensive, carefully curated 3D supervision.
With only a lightweight pose head and limited labelled data, LA-Pose achieves:
📷 State-of-the-art camera pose estimation
🌎 Strong zero-shot generalization across diverse driving scenarios
🏷️ Orders of magnitude less labelled data than fully supervised 3D approaches
Our full blog post: https://t.co/CcNWuLHJsn
Explore the full paper here: https://t.co/DHRsAS9ckV
Nissan and #Wayve have signed a partnership agreement that will bring our next-gen #ProPILOT driver assistance tech powered by Wayve #AI to a broad range of #Nissan vehicles.
Nissan aims to first launch the next-gen tech in Japan in fiscal year 2027.
https://t.co/FbFB2LU8VI
GAIA 3 introduces four powerful new capabilities that unlock richer and more scalable evaluation of autonomous driving systems. 🌍
🧵 Follow the thread below to see examples of;
1. Long perturb generations 🚗
2. Safety augmentations ⚠️
3. Semantic augmentations 🌤️🌅🌙
4. Embodiment transfer 🚘📷
GAIA 3 re-generates the same scenario as if observed from different vehicles with different camera positions. One scene, three embodiments, consistent dynamics. Ideal for testing models across different hardware setups.
These advances show how GAIA-3 brings new realism, diversity, and scale to the evaluation of end-to-end driving systems. 🚀
Dive into the full blog: https://t.co/pIk8xG1ENe
Every clip you see below is generated by GAIA-3.👇
#GAIA3 #EmbodiedAI #AISafety #GenerativeAI #AutonomousVehicles
It's awesome to be back in the Bay Area this week at @wayve_ai's other North American office.
I can't wait to test the massive progress the team's been making on rides around the Bay Area and city while I'm here, and to meet with our science leaders @vijaycivs@tkollar@gianlucacorrado and others to galvanise the groups at the start of an incredibly exciting #YearOfEmbodiedAI ahead!
#Science #Team #EmbodiedAI
Building language models is difficult and requires high quality preprocessing, modeling, evaluation and large scale training.
As significant collaborators in this project at TRI, the resulting 7B model DCLM-7B is a significant achievement. It is a competitor to Mistral 7B and LLaMA-7B, even though trained on less data. And it’s fully open. And that’s just the start of the competition.
Excited to see how others leverage these results to build even more capable language models and improve dataset quality.
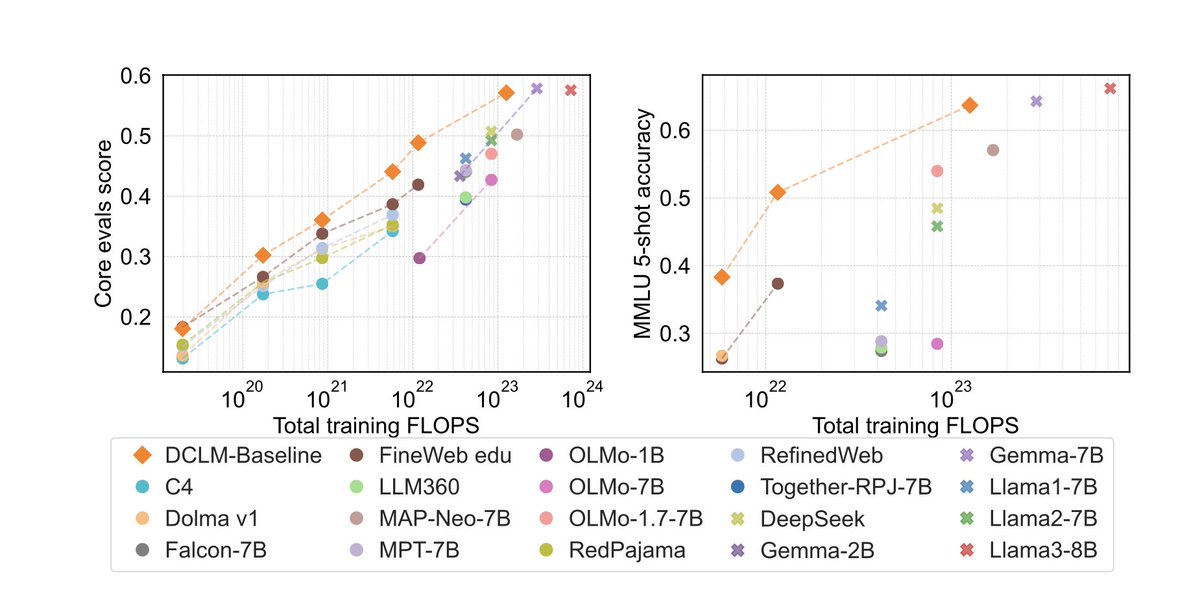
I am really excited to introduce DataComp for Language Models (DCLM), our new testbed for controlled dataset experiments aimed at improving language models. 1/x
Check out DataComp for language models! Open data, open code, open training recipe, and close to Llama3-8B performance. This has been a labor of love over the last year, a huge thanks to all the collaborators for helping make this happen!
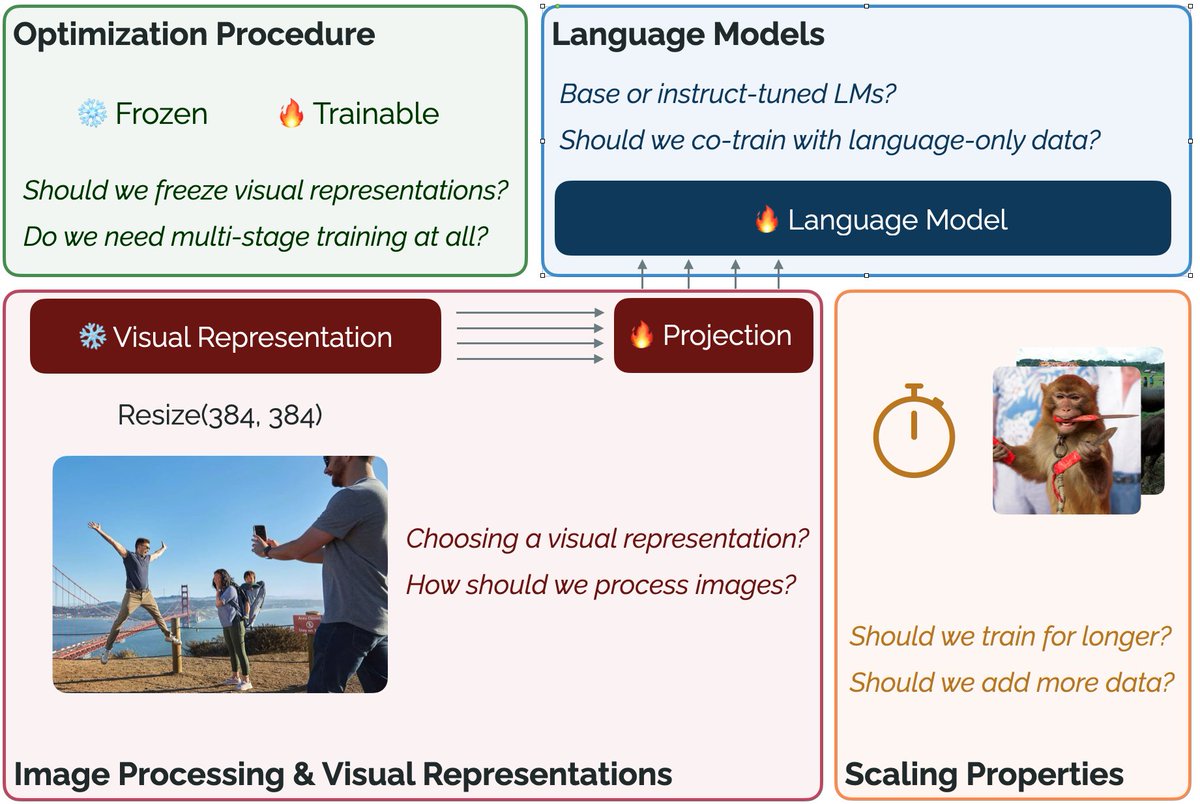
What design choices matter when developing a visually-conditioned language model (VLM)?
Check out our paper – Prismatic VLMs – and open-source training code, evaluation suite, and 42 pretrained VLMs at the 7B-13B scale!
📜 https://t.co/yyarNk7GuZ
⚙️ + 🤗 https://t.co/TsoQGsuSN2
Excited to release Prismatic!
Cutting through the noise of vision-language modeling, Prismatic is a release of 42 pre-trained VLMs from the 7B to 13B scale, a codebase for rigorous evaluation and a myriad of insights for what matters for performance.
What design choices matter when developing a visually-conditioned language model (VLM)?
Check out our paper – Prismatic VLMs – and open-source training code, evaluation suite, and 42 pretrained VLMs at the 7B-13B scale!
📜 https://t.co/yyarNk7GuZ
⚙️ + 🤗 https://t.co/TsoQGsuSN2
By first developing some of the best Vision-Language Models with Prismatic at TRI:
https://t.co/Se8oDRVSBp
OpenVLA was able to quickly build some of the best generalist policies for robotics. Code, data and weights are all open-source:
https://t.co/Lp6DlvvTpr
This is a great achievement! Congrats @moo_jin_kim@siddkaramcheti@KarlPertsch@ashwinb96@SurajNair_1 and all collaborators.
Recurrent models like RWKV and Mamba have gained attention recently, but these can be costly to train and iterate on.
What if we could simply...
turn Mistral/Llama/Gemma into an RNN? 🎩🪄
Presenting our work, Linearizing Large Language Models!
https://t.co/hbaSUWk8uc
Over the last year at TRI we’ve been training Large Language Models, including results in the following areas:
Scaling: https://t.co/zkbTfwpGkz
Alignment: https://t.co/zchTwZCndy
As a part of upcoming work, we are sharing back with the open source community and releasing a performant Mamba model that we’ve trained at the 7B parameter scale. More results on linear transformers upcoming.
📢 Releasing TRI's open-source Mamba-7B trained on 1.2T tokens of RefinedWeb!
Mamba-7B is the largest fully recurrent Mamba model trained and is a state-of-the-art recurrent LLM. 🚀🚀🚀
https://t.co/PmsoRc4SNG