Releasing VLA Foundry: an open-source framework that unifies LLM, VLM, and VLA training in a single codebase. End-to-end control from language pretraining to action-expert fine-tuning — no more stitching together incompatible repos.
My team at Woven by Toyota is hiring an ML intern (onsite in Tokyo) for this summer! Looking for experience with large-scale pre-training for perception models (bonus: 3D) and world models. Feel free to DM if interested
Apply: https://t.co/C8vzgj7dhq
My team is looking for highly motivated research interns this summer with strong backgrounds in 3D representations for robotics and scene understanding. If you’re interested, please feel free to DM me!
https://t.co/VrVt3EEU2L
🚀Thrilled to share what we’ve been building at TRI over the past several months: our first Large Behavior Models (LBMs) are here! I’m proud to have been a core contributor to the multi-task policy learning and post-training efforts.
At TRI, we’ve been researching how LBMs can help robots learn faster, better, and more efficiently.
The key takeaways:
✅ We built an evaluation pipeline to benchmark LBM performance with real 𝐬𝐭𝐚𝐭𝐢𝐬𝐭𝐢𝐜𝐚𝐥 𝐜𝐨𝐧𝐟𝐢𝐝𝐞𝐧𝐜𝐞
✅ Pre-training on hundreds of tasks makes models more robust—plus, we can teach new, complex tasks with 80% 𝐥𝐞𝐬𝐬 𝐝𝐚𝐭𝐚
✅ The bigger and more diverse the pre-training, the better the results
Check out our overview video, webpage and paper for more details:
✨https://t.co/sHB7jK8UqK
🌎 https://t.co/h6nsqgTt9Y
📄 https://t.co/JUXdauDLjJ
We hope this work helps move the field of robotics forward!
Excited to share our new work on multi-object scene completion and grasp pose estimation from a single RGB-D image!
Kudos to @s1wase and the incredible team from @ToyotaResearch, @WbyT_Tech, and @CarnegieMellon.
Come chat with us at #CVPR2025 to learn more.
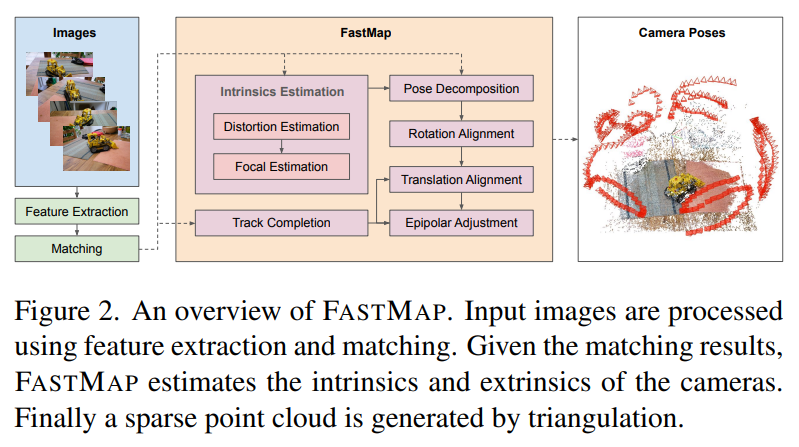
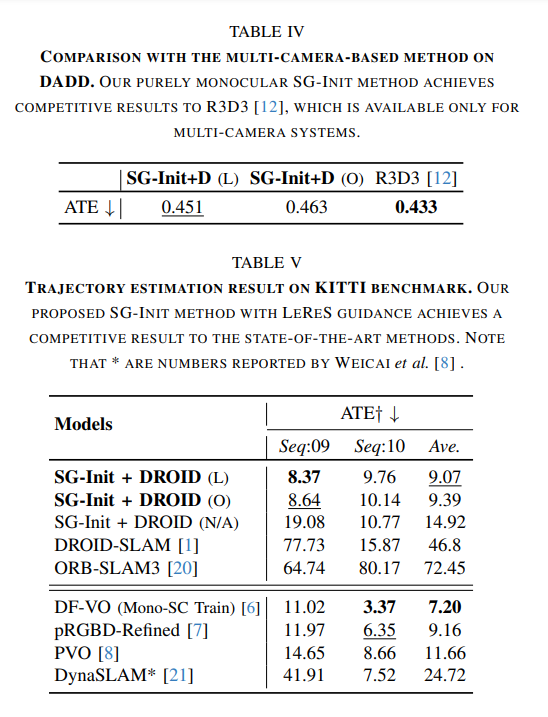
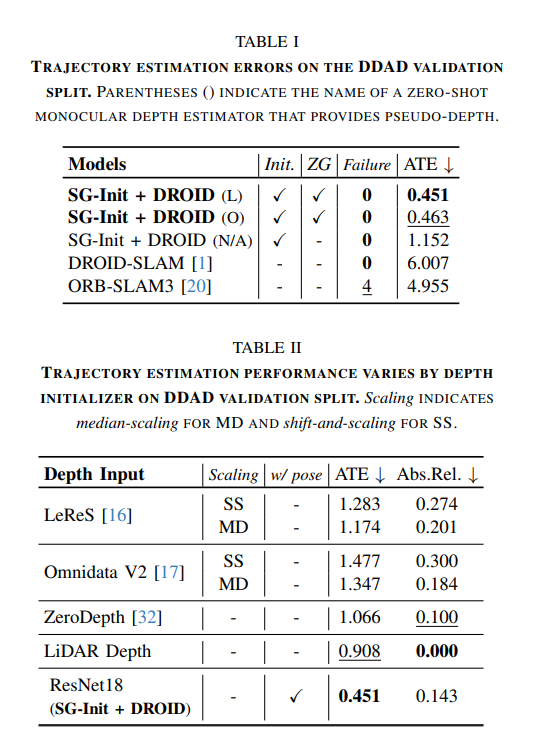
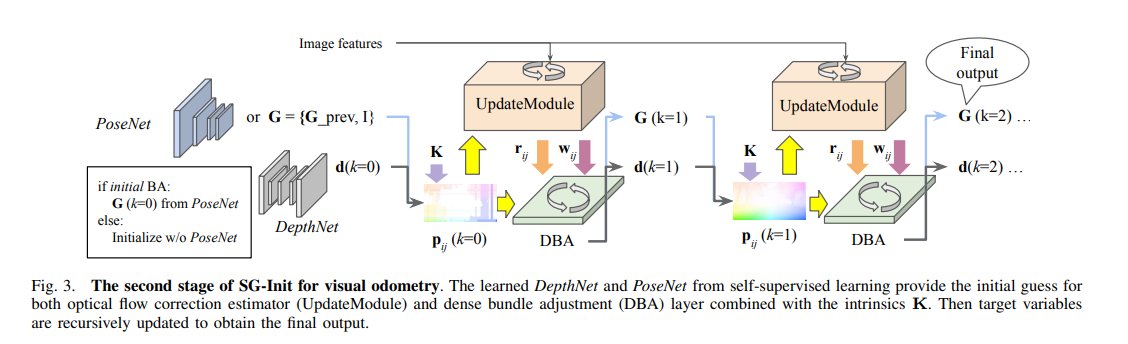
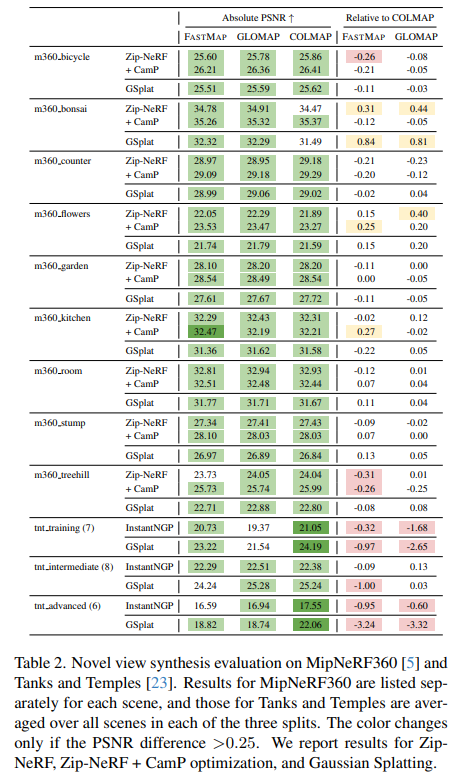
FastMap: Revisiting Dense and Scalable Structure from Motion
Jiahao Li, @__whc__, @mzubairirshad, @vslevic, Matthew R. Walter, Vitor Campagnolo Guizilini, @gregshakh
tl;dr: replace BA with epipolar error+IRLS; fully PyTorch implementation
https://t.co/KZ6QbMtRcJ
Introducing ✨Posed DROID✨, results of our efforts at automatic post-hoc calibration of a large-scale robotics manipulation dataset.
We provide:
🤖 ~36k calibrated episodes with good quality extrinsic calibration
🦾 ~24k calibrated multi-view episodes with good-quality multi-view camera calibration
✅ Quality assessment metrics for all provided camera poses
To achieve this, we utilize:
1️⃣ Auto Segment Anything (SAM) based filtering (Camera-to-Base Calibration)
2️⃣ Tuned CtRNet-X for bringing in additional cams (Camera-to-Base Calibration)
3️⃣ Pretrained DUST3R with depth-based pose optimization (Camera-to-Camera Calibration)
Try it out at: https://t.co/jznY1eikIv
Learn more at:
🌐 arXiv: https://t.co/vT18oyhc9v
📄 Blog: https://t.co/wZU20Ofjk0
🧵 1/n
1/
DeepSeek-VL is trained from DeepSeek LLM
Qwen-VL is trained from Qwen-7B
PaliGemma is trained from Gemma-2B
Is this really the best way to train a VLM?
What if we had access to model checkpoints -- would it be better to train with images before the LLM fully converges?
🧵
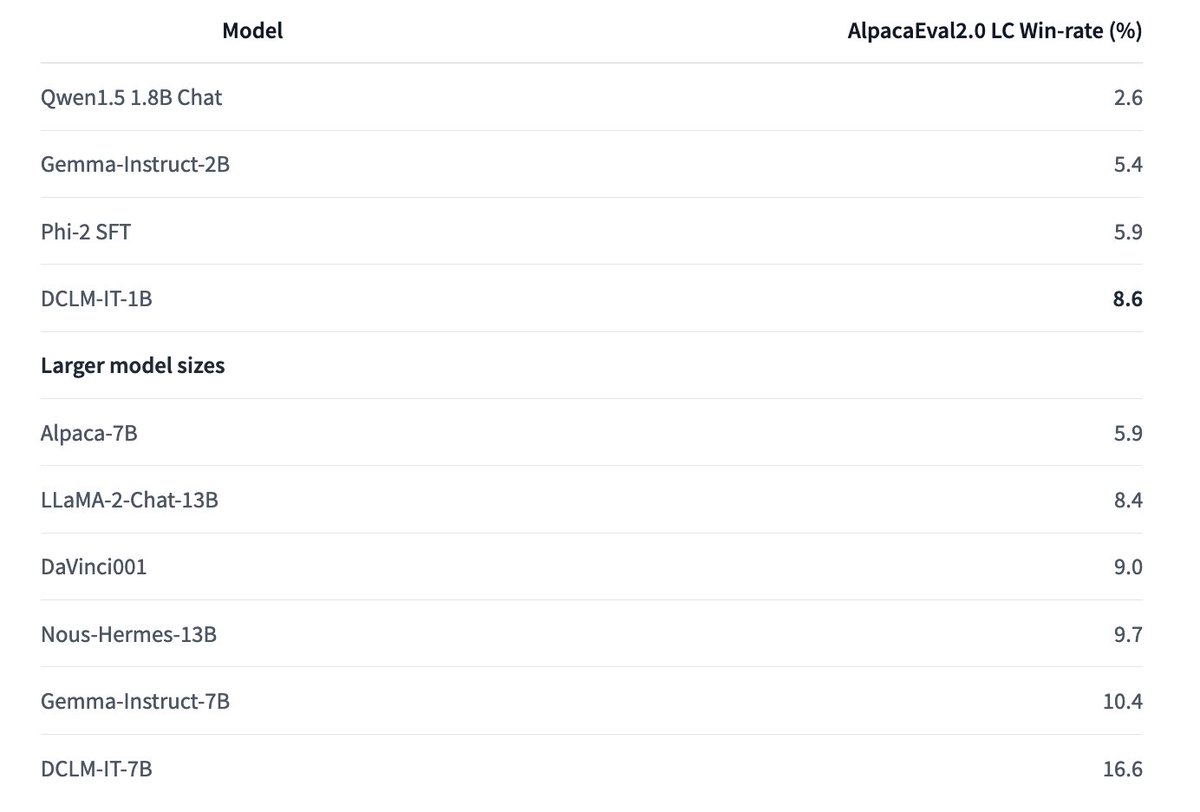
We're seeing more and more that small models trained on high-quality datasets can perform very well.
Together with our collaborators at DCLM, we trained strong 1B models and openly release everything!
Check it out at https://t.co/66hH6LleGy
Check out our latest models here:
https://t.co/Tfpf18Allp for the base model, and
https://t.co/Ss9gT8IjT4 for the IT model with evaluations comparing to other strong small models
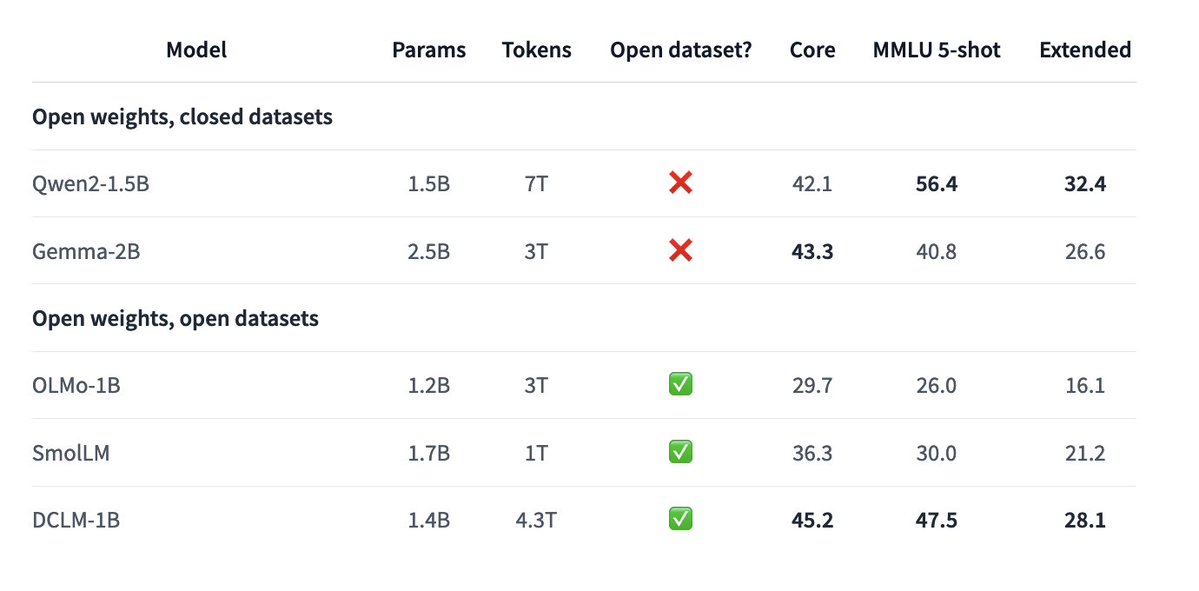
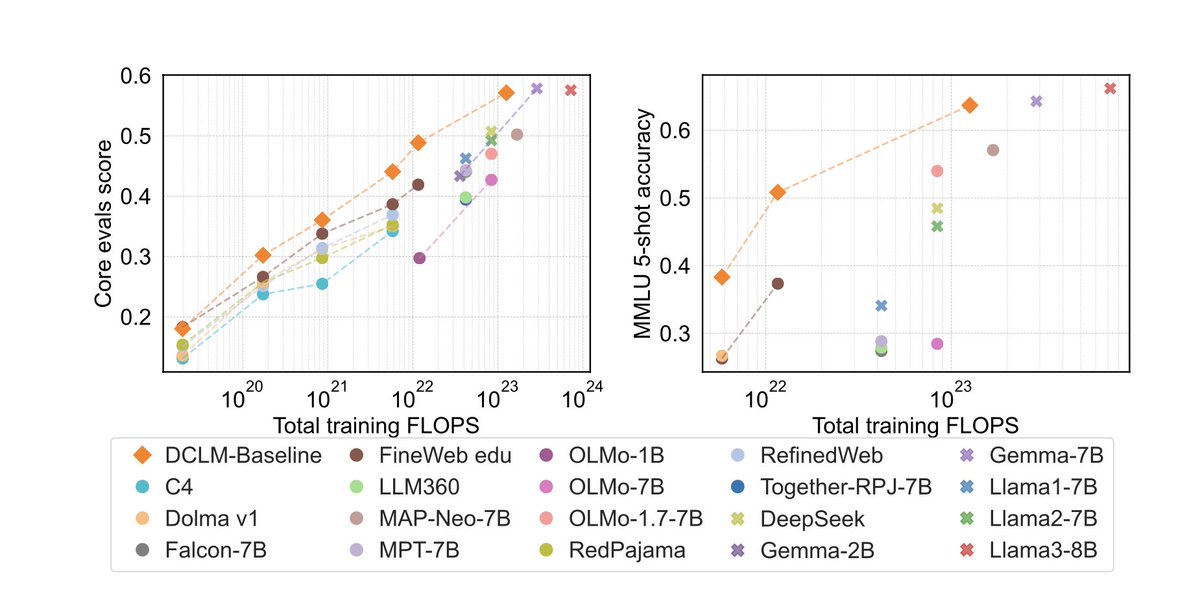
We've publicly released our DataComp-LM models: Truly open 1B and 7B models that's competitive with state-of-the-art (llama3, qwen2, gemma, ...) on most benchmarks, but with a public training recipe, dataset, and code! (1/3)
- tons of new cool work on large rnns (@RWKV_AI, mamba2 @tri_dao@_albertgu, just read twice @simran_s_arora, etc)!
- but pretraining is expensive
- our recipe for linearizing llms into rnns was accepted to @COLM_conf! #COLM2024
- we train SOTA rnns & show limitations of rnns
I am really excited to introduce DataComp for Language Models (DCLM), our new testbed for controlled dataset experiments aimed at improving language models. 1/x
Check out DataComp for language models! Open data, open code, open training recipe, and close to Llama3-8B performance. This has been a labor of love over the last year, a huge thanks to all the collaborators for helping make this happen!
Starting the #RoboNeRF workshop at #icra2024 with our first speaker @leto__jean. Jeanette's talk is on Grasping with NeRF! Come check it out at Conference Center 419!