I know CIA agent when I see one , you want to tell me economist who was a former photoeditor for maitiest profit of the laaaawd anatumia Kali Linux . CIA agent in plain sight
@KenyaPower_Care@KenyaPower_Care How should someone be assisted to restore an outage of Power in Rongai? I have used *977# no help at all and even tried walking to the offices physically. It’s been three days! It’s so frustrating to say the least. Your customer care structures are wanting!
@KenyaPower_Care How should someone be assisted to restore an outage of Power in Rongai? I have used *977# no help at all and even tried walking to the offices physically. It’s been three days! It’s so frustrating to say the least. Your customer structures wanting!
A Deep Dive into Mobile Forensics
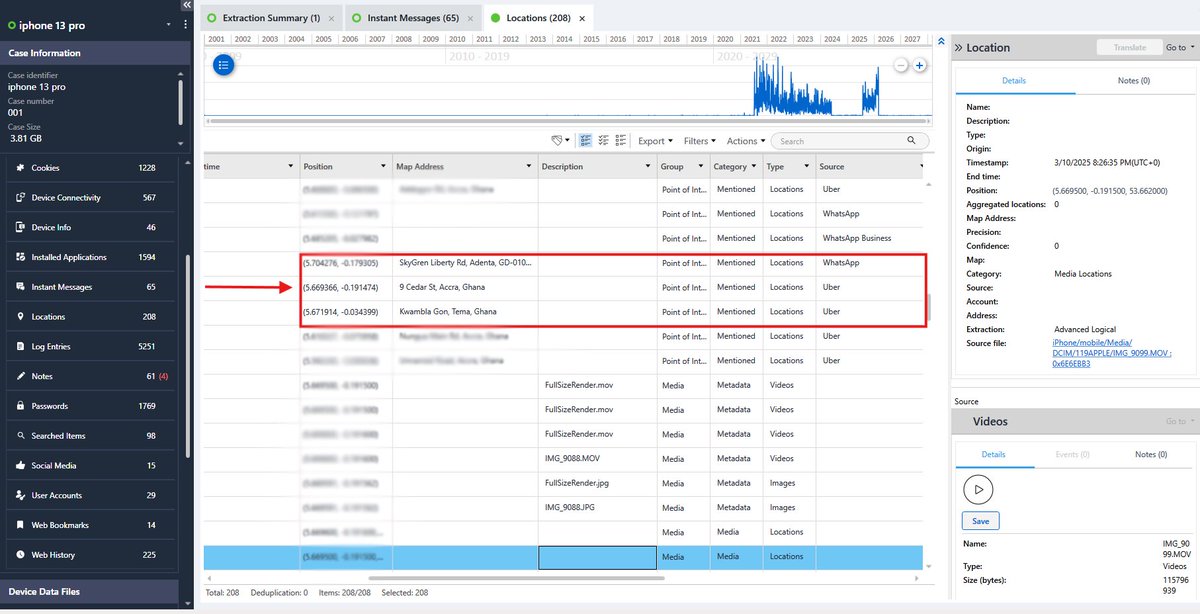
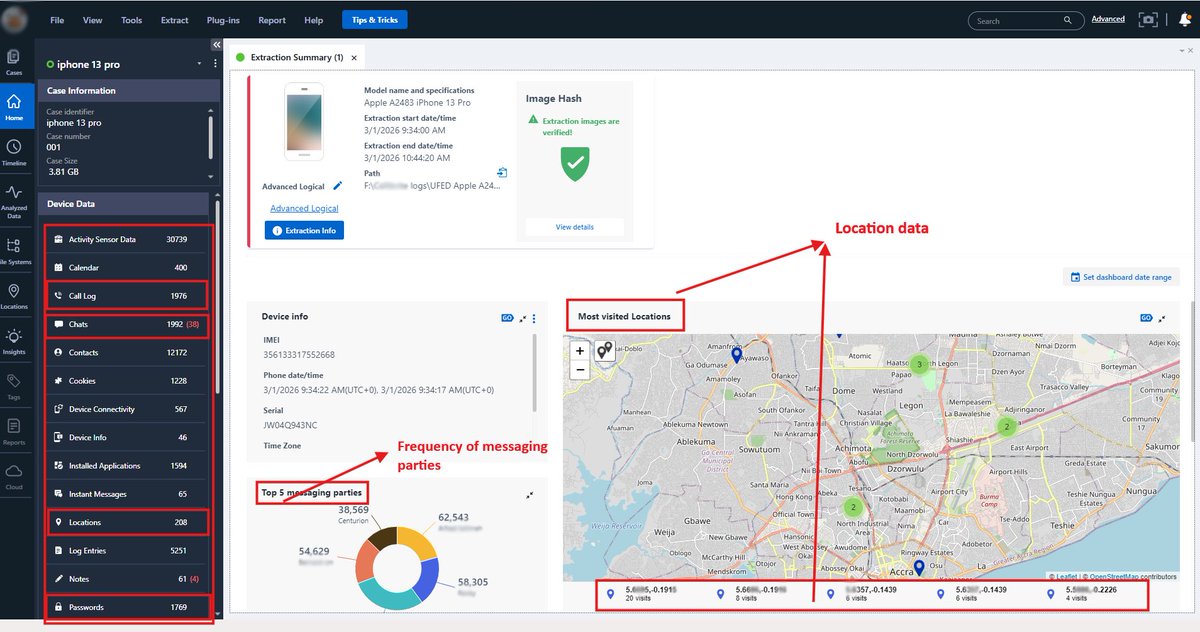
I recently completed a full mobile forensic analysis on an iPhone 13 Pro and it was a powerful reminder of how much a device actually remembers.
This was an advanced logical extraction with verified image integrity. Even without diving into content, the metadata alone told a story.
From location artifacts, I reconstructed where the device had been, the routes it traveled and the exact timestamps tied to those movements. But more importantly, I could see how those locations were generated.
Some coordinates were tied to ride activity such as uber and bolt. Others came from navigation searches. Some were linked to shared live locations inside messaging apps.
Each source leaves a different footprint. A searched address tells a different story than an active trip. A shared live location suggests intentional disclosure. The coordinates are only part of it, the behavior behind them is the real evidence.
The “most visited locations” view made patterns obvious. Certain coordinates appeared repeatedly, building a clear picture of routine and frequency over time.
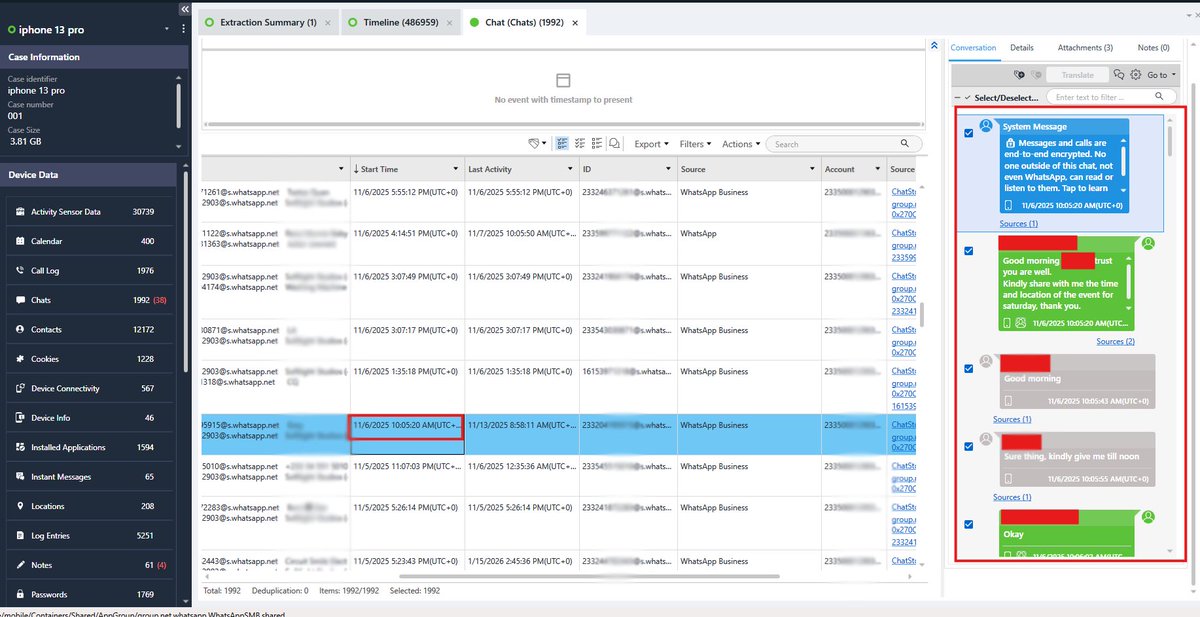
On the communication side, interaction volume alone highlighted the primary contacts. Without even reading conversations, it was immediately clear who the highest frequency messaging relationships were. Volume builds pattern. Pattern builds context.
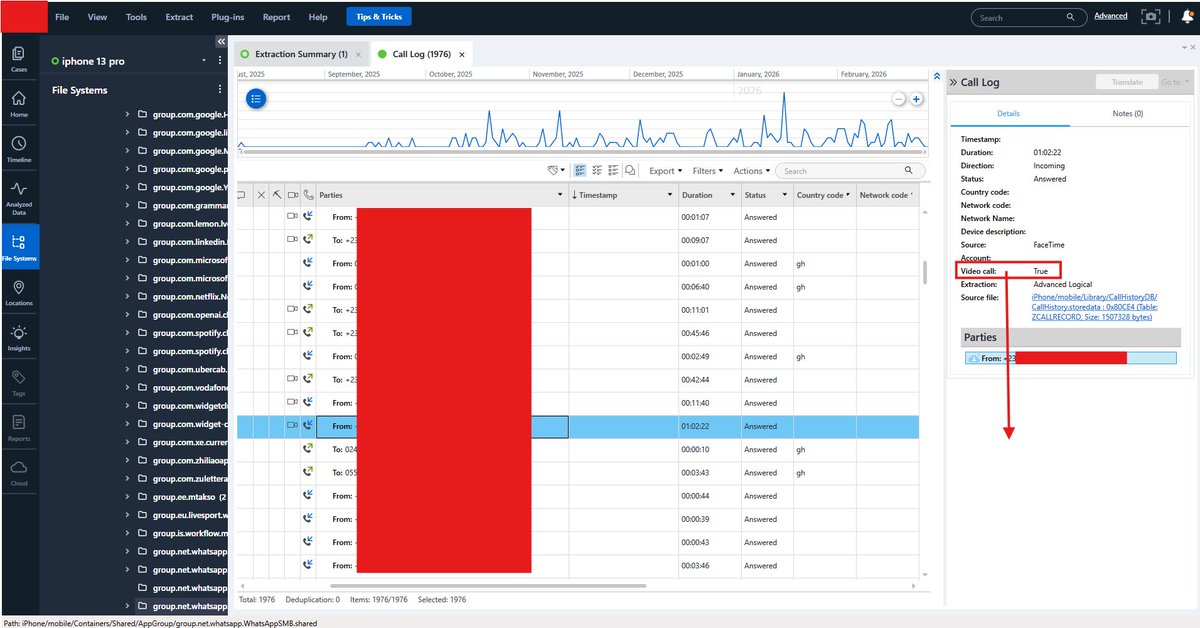
Call analysis went just as deep. Even when call entries were deleted, I could still determine whether interactions were audio or video, which platform they occurred on, how long they lasted, and whether they were answered, missed or rejected. Deleting a visible log doesn’t erase the underlying artifacts.
I was also able to recover delivered media, expired content, deleted messages and metadata tying everything to specific timestamps and user actions.
Here’s what stands out. Phones don’t just store content. They store behavior.
They store routine. They store intent.
Files can be deleted. Logs can be cleared. But the artifacts remain.
#digitalforensics #DFI #mobileforensics #cybersecurity
Learn Linux with these 6 websites🐧
1. LinuxOpsys
https://t.co/VAHyoEwPL4
2. Linux Handbook
https://t.co/a3SCNKZAQ2
3. Sysxplore
https://t.co/jf0PYheaZn
4. Linuxize
https://t.co/KjHooq24hl
5. Linux Journey
https://t.co/FOlDkzgwYB
6. Linux Survival
https://t.co/1a5wCoaomK
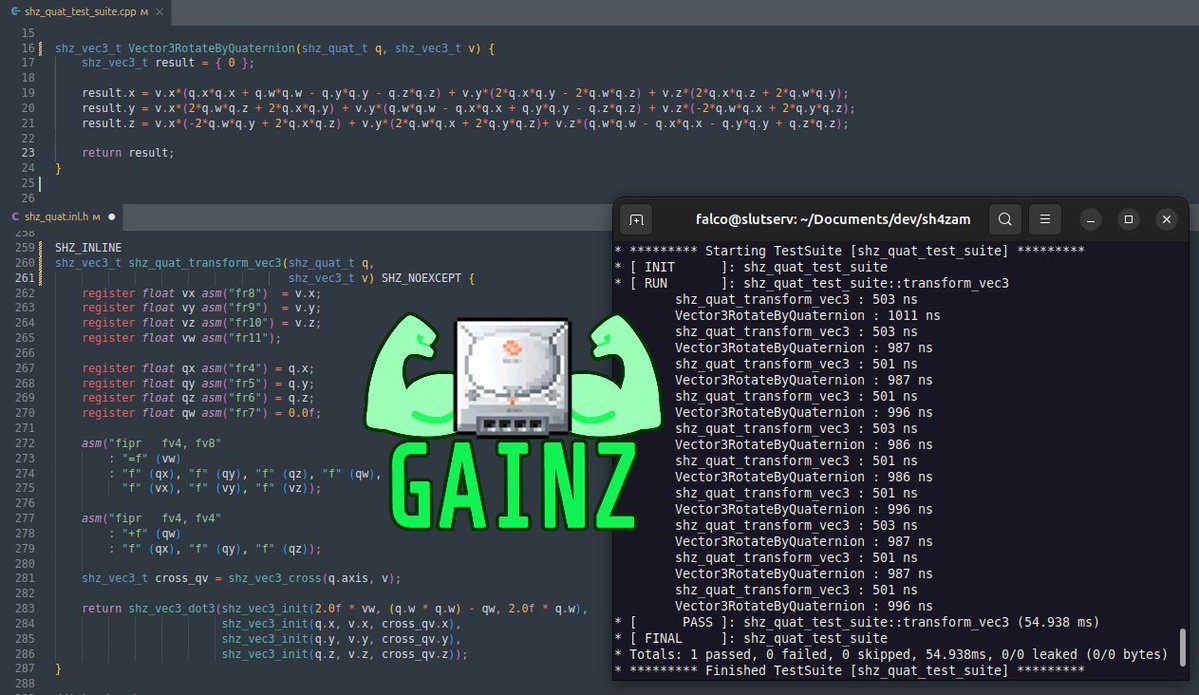
Holy CRAP, I just achieved a freaking 1.98x speedup for rotating a 3D vector by a quaternion on the Sega Dreamcast by using vectorized SH4 inline assembly over a standard C implementation!
This one I am OVER THE MOON WITH. The SH4 has historically been said to only accelerate vector and matrix operations, with a lack of HW acceleration for quaternions traditionally being called "lamentable" due to quaternion math not becoming mainstream until a bit after the console was created.
...bullshit. Yet again, I was able to accelerate quaternion math using the SH4's vector instructions and FPU, this time for SUBSTANTIAL performance gainz.
The trick? Why I was unable to achieve such gainz for so long? I spent so much time hyper fixating upon what has historically been accepted as the "optimal" floating-point algorithm for performing a quaternion rotation, based on minimal number of FP computations...
The problem? What is considered "minimal" for scalar FP math is not necessarily minimal when you have SIMD and vector instructions performing multiple FP operations in parallel!
One day I was verifying my implementation, when I ran into an alternate representation of the same operation, which was derived using a few linear algebra properties, yet was still mathematically equivalent to the original. This one being called "somewhat optimal," and "fairly fast," but was said to still be doing more work than necessary, compared to my previous implementation...
But the majority of the computational work? Is performing the dot product operation between 3D vectors! Which we all know, with FIPR, is a single instruction for us to accelerate on the SH4!
NOW, looking at the code, you can see the traditional algorithm on the top, implemented by the Vector3RotateByQuaternion() routine. This routine was taken from raylib--not because I'm picking on raylib, but because they typically have some of the prettiest, most straightforward implementations of linear algebra routines in pure, cross-platform C.
Not only that, but in my experience, the way raymath is written also facilitates optimal code generation from the compiler. So I'm using raymath's routine here, because it represents a competent, vanilla, no bullshit C implementation to benchmark against.
Now look at the balls-out SH4 optimized routine I implemented for SH4ZAM on the bottom pane. I am exploiting:
1) FIVE freaking 3D dot product patterns which I'm able to accelerate with FIPR either directly or through calling my special-case, chained dot-product routine, shz_vec3_dot3(), which carefully pipelines multiple FIPR calls together to calculate multiple dot products between a constant vector and batch of others.
2) CAREFUL register pinning, so that the compiler understands not only where operands must go for properly using them with the vector instructions, but also for knowing not to reload the invariants into FP regs across SH4 assembly boundaries.
The end result? The pane on the right shows the execution time for multiple invocations of the two routines with the same operands, using the cycle-accurate performance counters on the SH4 CPU.
Total gainz? About 100 clock cycles! 💪
GitHub commit and source code:
https://t.co/lPwufeQwXW
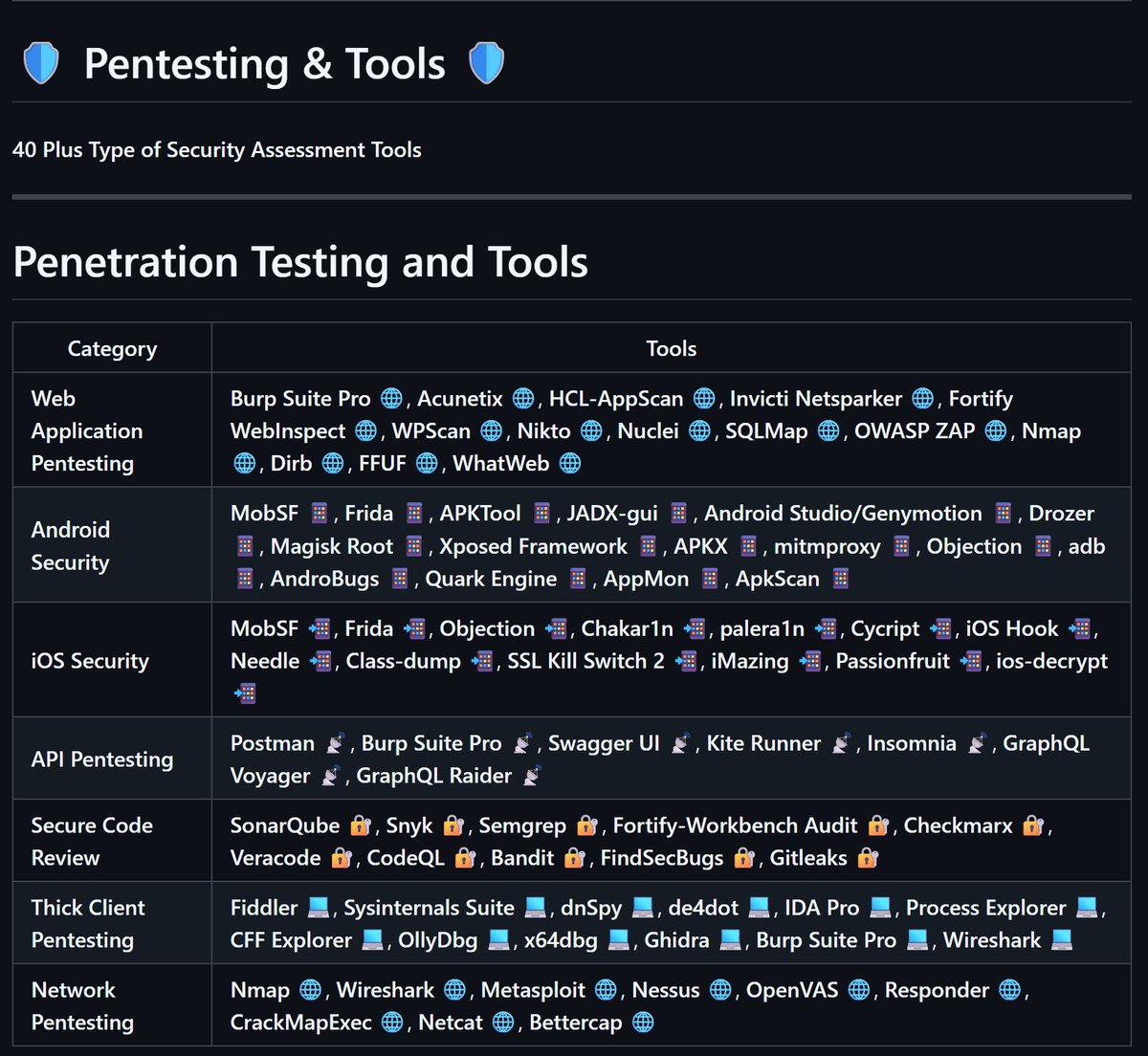
Let's sharpen those tools ⚒️
Check out these 5 essential tools you should learn for #ActiveDirectory pentesting, then jump on #HTB Academy to master them all! Use the code 25OFFANNUALDEC25 for a 25% OFF your Gold Annual subscription and get certified: https://t.co/MiGoS0utPu
#HackTheBox #CyberSecurity #InformationSecurity #AD #RedTeam
OpenShot 3.4 Open-Source Video Editor Released with New Effects, New Features, and Huge Performance Improvements https://t.co/9Yn6lEKH6D
@openshot#OpenSource#Linux
Parrot 7.0 Ethical Hacking Distro Switches from MATE to #KDE Plasma as Default Desktop, Beta Out Now https://t.co/NkizkhXLN1
@ParrotSec#Linux#OpenSource#security






























![raunak_yadush's tweet photo. 🚨 119𝐆𝐁+ 𝐆𝐎𝐎𝐆𝐋𝐄 𝐃𝐑𝐈𝐕𝐄 — 𝐀𝐋𝐋 𝐏𝐀𝐈𝐃 𝐂𝐎𝐔𝐑𝐒𝐄𝐒 🚨
𝐌𝐢𝐬𝐬𝐞𝐝 𝐢𝐭 𝐥𝐚𝐬𝐭 𝐭𝐢𝐦𝐞? 𝐈’𝐦 𝐝𝐫𝐨𝐩𝐩𝐢𝐧𝐠 𝐢𝐭 𝐚𝐠𝐚𝐢𝐧. 👌
This vault helped agencies close $9K+ clients using proven systems.
Inside the Drive:
📁 AI & Automation
📁 Ethical Hacking
📁 Cybersecurity
📁 Prompt Engineering
📁 Google Cloud
📁 Machine Learning
📁 DevOps + CI/CD
📁 Docker & Kubernetes
📁 Blockchain
📁 Power BI
📁 React + Node
📁 Cloud Security
📁 Linux
📁 Pen Testing
📁 Data Analytics
📁 Data Science
📁 Big Data
📁 SQL
📁 Tableau
📁 Python
📁 AWS
📁 Java
Everything organized. Everything premium. 119GB+ value.
Get it:
✔ Follow @raunak_yadush [MusT]
✔ Like & RT
✔ Comment “ NEED ” To Get Auto DM.
⚠️ No follow = No Access ⚠️](https://pbs.twimg.com/media/HC3IecTbsAASP4p.jpg)