1/5 (thread) The first paper of my PhD is finally out in @NatureComms and I couldn’t be prouder. For full and nuanced discussion on implications please read the paper, but here is a short TL/DR thread. W/ @IanCharest, I Sligte, S Assecondi, K Shapiro: https://t.co/aDKcNdSlnq
🚨 Finally out in Nature Machine Intelligence!! "Visual representations in the human brain are aligned with large language models"
https://t.co/GB5k6IV4Jg
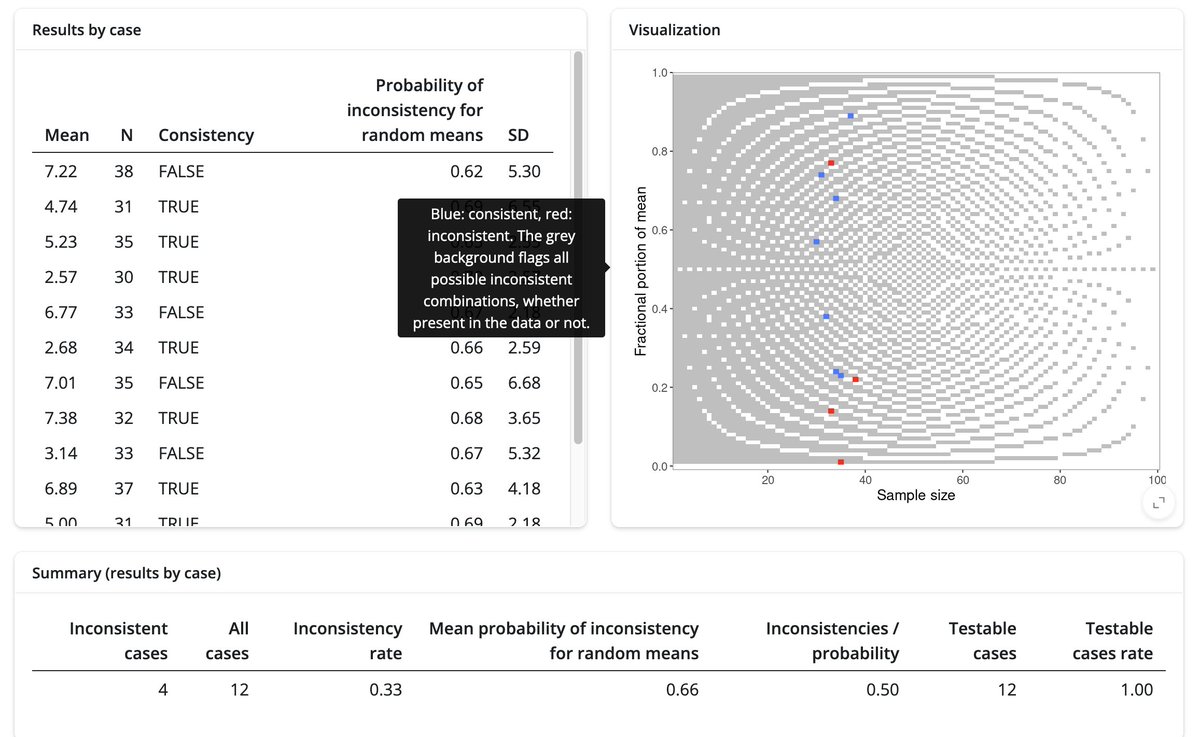
New: use GRIM or GRIMMER to test reported statistics for consistency.
Are these values even possible? Find out with the error detection webapp!
Test many values at once, get summary statistics, and download your results. 🧵 1/5
https://t.co/ShLM91h1tT
been learning a lot about LLMs etc over the past year, organized some of my favorite explainers into a “textbook-shaped” resource guide
wish i’d had this at the start, maybe it can useful to others on a similar journey
https://t.co/54gZimsOnO
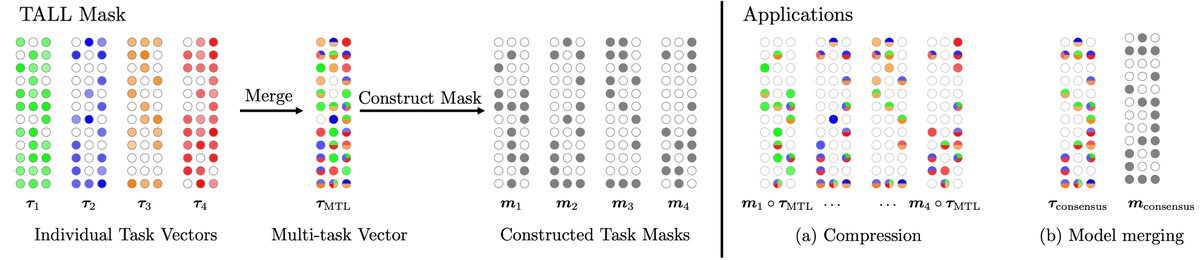
Wouldn't it be great if we could merge the knowledge of 20 specialist models into a single one without losing performance? 💪🏻
Introducing our new ICML paper "Localizing Task Information for Improved Model Merging and Compression". 🎉
📜: https://t.co/JC4mdujKkd
🧵1/9
Seeing Theory by Brown University is such a great interactive way to learn the fundamentals of probability in #psychstats! It has #dataviz for more advanced concepts like regression and ANOVA, too! 📊 #IOPsych https://t.co/GKteznJhG5
Please recommend books about #neuroscience! I am speaking to some high school students next week (and also plan to make a post on Tiktok). I am looking for books that are aimed at a general audience and highlight interesting aspects of the field.
Here’s my take on the “mathematical foundations” of machine learning and AI. These course notes cover the basics of statistical learning theory, optimization, and functional analysis. https://t.co/b8dHripLLs
Wanna know whether #preregistation 'works' in psychology and what that even means? You can read about it in my PhD-dissertation here: https://t.co/sCbd9Rr9rA
Or check out this talk in which I summarize the results: https://t.co/hy2UzH9A3J
Defense is planned for 22 March! 😱
So psychotherapy seems to have a small effect (d=.22) for adult depression while being very expensive both in terms of time investment and actual money. Why is it so popular? https://t.co/ffud3MjWaM
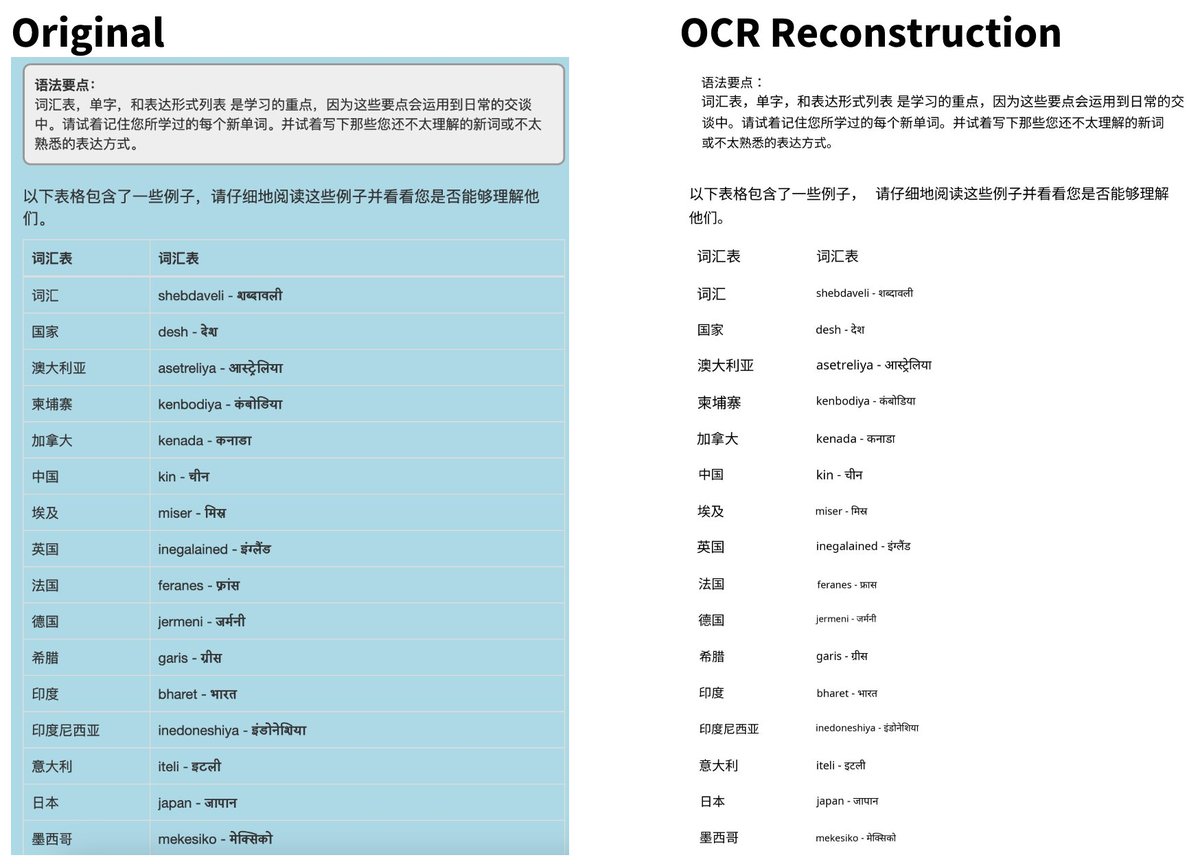
A good PDF parser that can understand embedded tables and figures is a necessary condition for building good RAG.
Most PDF parsers struggle with representing tables, which sends a confusing representation to the LLM, leading to wrong answers.
That’s where LlamaParse comes in. We present an expanded set of results below 📊, comparing LlamaParse to PyPDF, PyMuPDF, Textract, and PDFMiner.
RAG with most PDF parsers over a table in the Apple 10K filing fails on a large percentage of table values.
Signup for an account here! https://t.co/DoZgCPCYPQ
LlamaParse client repo in Python, but you can also use as a REST API: https://t.co/NldQN580hl
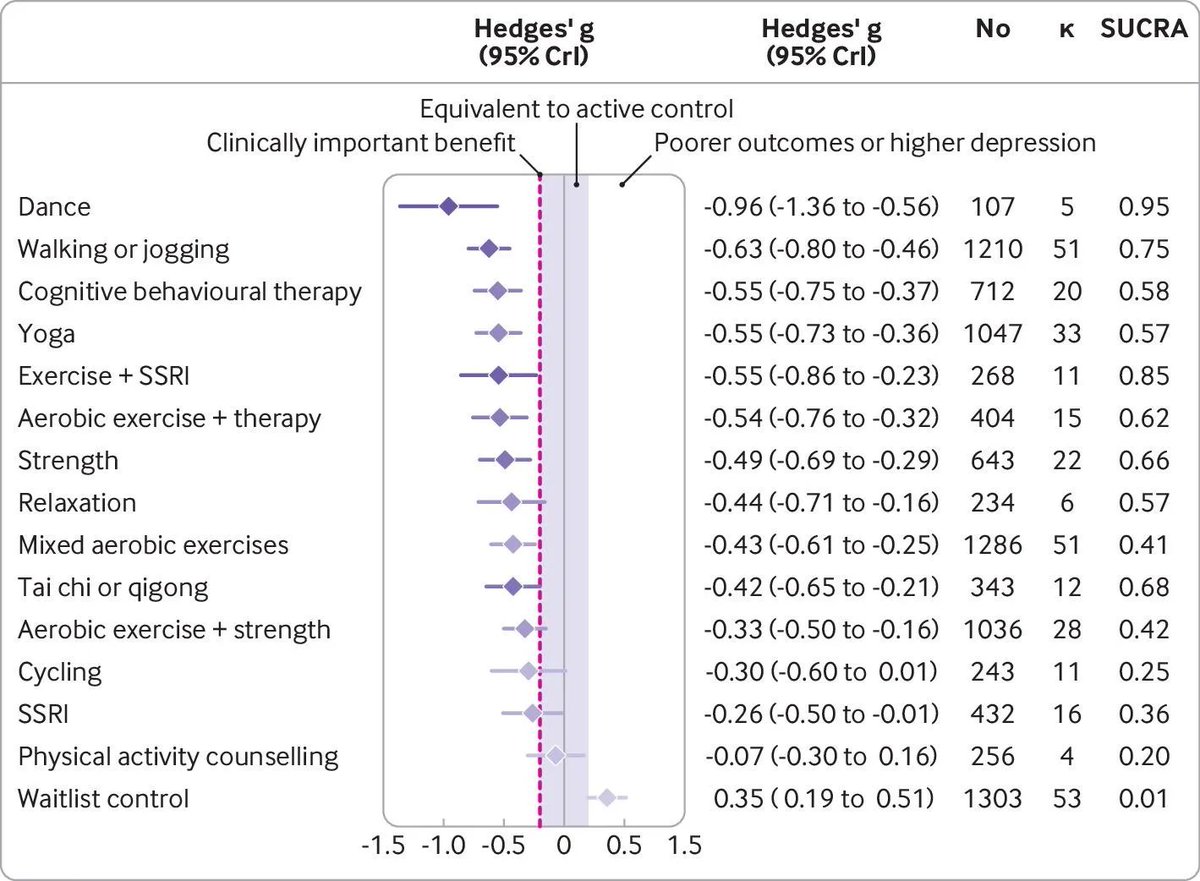
They buried the lede on this new study. It's not that exercise beats out SSRIs for depression treatment, but that *just* dancing has the largest effect of *any treatment* for depression.
That's kind of beautiful.
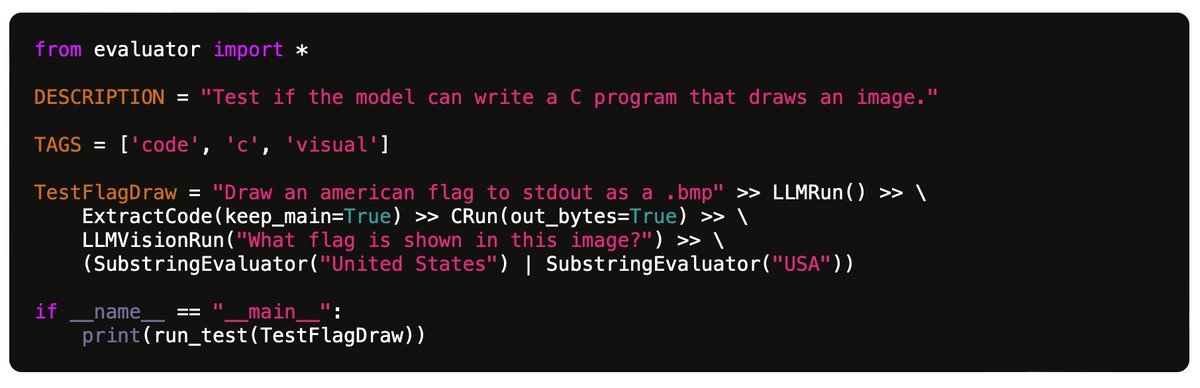
"My benchmark for large language models"
https://t.co/YZBuwpL0tl
Nice post but even more than the 100 tests specifically, the Github code looks excellent - full-featured test evaluation framework, easy to extend with further tests and run against many LLMs.
https://t.co/KnmDD1AJci
E.g. for the 100 current tests on 7 models:
- GPT-4: 49% passed
- GPT-3.5: 30% passed
- Claude 2.1: 31% passed
- Claude Instant 1.2: 23% passed
- Mistral Medium: 25% passed
- Mistral Small 21% passed
- Gemini Pro: 21% passed
Also a huge fan of the idea of mining tests from actual use cases in the chat history. I think people would be surprised how odd and artificial many "standard" LLM eval benchmarks can be. Now... how can a community collaborate on more of these benchmarks... 🤔
New article shows Bayes factors are massively misused: https://t.co/hqm2oc0xG6 Recommends updating teaching material - which I already have done in my free textbook https://t.co/jQ0gjL1jwW But, from next year, I will also stop teaching Bayes factors.
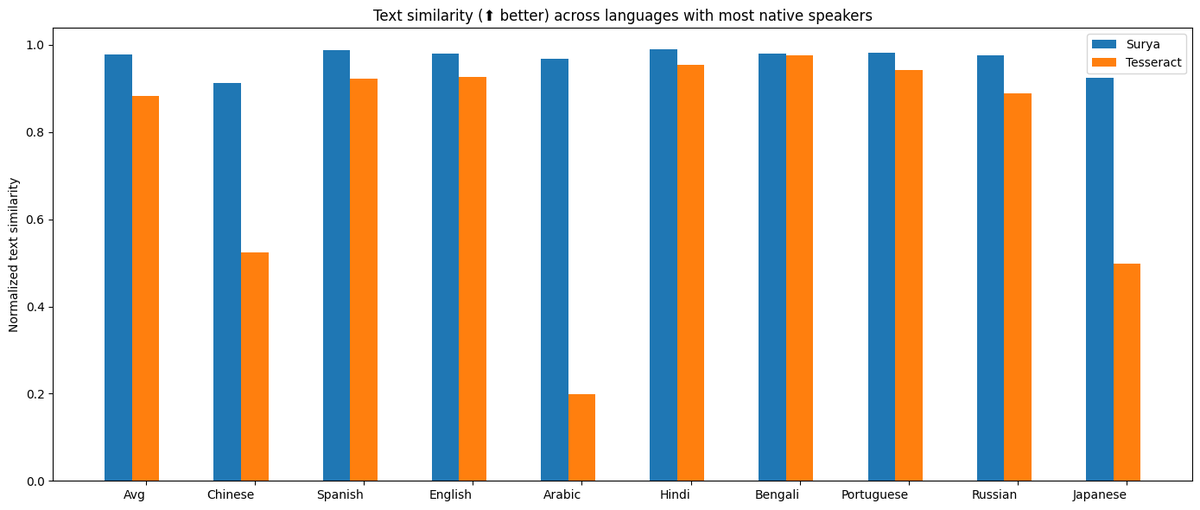
Announcing surya OCR - text recognition in 93 languages. It outperforms tesseract in almost all languages, often by large margins.
Find it here - https://t.co/DD2HfwIG9i .
Have you ever done a dense grid search over neural network hyperparameters? Like a *really dense* grid search? It looks like this (!!). Blueish colors correspond to hyperparameters for which training converges, redish colors to hyperparameters for which training diverges.
It is an amazing time to work in the cognitive science of language. Here are a few remarkable recent results, many of which highlight ways in which the critiques of LLMs (especially from generative linguistics!) have totally fallen to pieces.
Foundation models are well-established in vision and language, but time series forecasting has lagged behind - it still relies on dataset-specific models.
Meet Lag-Llama: the first open-source foundation model for time series forecasting!
@HansMokeNiemann For some reason I hate to agree with you. I wish I was more impartial as a person but for this situation I do think this seems ridiculous and doesn’t really fit the narrative most people have.