A big problem with research studies on AI models is that given how long the peer review process is, the results are always out-of-date by the time the paper is published.
This time, we have something better!
The typical reaction to research results like this roughly goes "You're just testing on old models. Today's models are way better and surely can do it now!"
But the best solution is for these papers to also open-source all of their testing framework so that upon publication, others can reproduce their results, as well as run it on the newest models of the day - and into the future. After all, "this is the worst they'll ever be" so what really matters is determining when they DO pass the threshold.
As it turns out, the authors of this paper DID open-source their evaluation framework!
Here:
https://t.co/iXLwmItKwu
So I figured... let's re-run the tests on the latest models!
Summary of our results are here:
https://t.co/1Dzj0UcJUQ
One drawback is that, unfortunately, the authors didn't (or weren't legally able to) open-source ALL the testing data, since apparently some of it is copyrighted by JAMA/NEJM etc. That's a separate problem with the medical research publishing industry for another time.
However, we were able to reproduce the test on the public datasets they did include!
First, we re-ran the same tests (as closely as we could) on the old models the paper claimed to use, in order to establish a baseline and determine how much "drift" there would be. (Answer: not too much)
Then we ran those tests on the newest frontier models we could find.
The results are: the most capable models today (GPT-5.5 Pro) did outperform the best models from before (79/100 vs 69/100), but did not improve enough to be considered sufficient for reliable medical use.
In fact, the paper's criterion for "fit for reliable medical use" is more stringent, requiring the models to be robust under perturbation and bad data, knowing when to say there's not enough information, give clinically valid reasoning rather than hallucinations, etc. Those sound pretty reasonable to me.
I wasn't able to reproduce that kind of qualitative evaluation, but even on the basic pass/fail test using public datasets of interpreting radiology images, the newest models are better, but not yet quite good enough.
Nevertheless, I would like to praise the paper's authors for at least open-sourcing what they could, enabling me to (fairly quickly) attempt to reproduce their results. This is definitely a step in the right direction!
While my reproduction wasn't able to be comprehensive, it certainly gave me useful directional info and - perhaps more importantly - allowed me (a random dude on the internet) to directly reproduce the results in their paper and validate them.
I would like to encourage ALL authors of research papers on AI models to do similar open-sourcing of their experimental frameworks!
Most AI code review tools look at one repo at a time.
But the bug usually isn't in the code that changed. It's in what that change quietly breaks three repos away.
@QodoAI just shipped Cross Repo Review to solve this.
I tested it on my own repos. Here's what it caught.
AutoScientist accelerates ML research and development to take days not months.
This summer we will support builders releasing frontier models in 10 different domains ranging from medicine to underserved languages.
All final models will be released to @huggingface and @kaggle 🔥
The System Cannot Validate Itself
Gödel Part III
Hilbert’s dream wasn’t just completeness.
It was self-certainty. A closed loop.
A formal system that could:
generate truth,
verify truth,
and prove its own consistency from within itself.
Gödel shattered that final hope.
Any sufficiently powerful formal system cannot fully validate itself using only its own internal rules.
That was the Second Incompleteness Theorem.
And it changed far more than mathematics.
⸻
Gödel revealed something profound:
Every system rests on assumptions it cannot fully justify from inside itself.
Mathematics.
Logic.
Computation.
Even physics.
At some level, every framework eventually reaches:
axioms,
primitives,
unprovable starting points.
Not because humans are stupid.
Because formal structure itself has limits.
⸻
This realization quietly shaped:
theoretical computer science,
cryptography,
AI theory,
proof verification,
complexity theory,
philosophy of mind,
and modern debates about consciousness and computation.
Alan Turing extended related ideas into computation itself:
some problems are fundamentally undecidable.
Not hard.
Undecidable.
⸻
But Gödel is also widely misunderstood.
He did not prove:
“science is fake”
“logic doesn’t work”
“anything spiritual must be true”
or that mathematics failed.
In fact, mathematics became even stronger afterward.
Gödel didn’t "destroy" formalism.
He revealed its horizon.
The map still works.
It’s just not the totality of reality.
⸻
That may be Gödel’s deepest contribution:
Not nihilism.
Humility.
The recognition that truth is always slightly larger than the systems we build to contain it.
The most dangerous form of laziness is performative productivity. Notes, tabs, highlights, summaries, plans. A whole pile of activity arranged to avoid direct contact with the work.
“The sharpest drop came from people who used the model for direct answers, not from those who used it more like a hint system, which suggests the real issue is not AI exposure itself but replacing effort with completion.
The result is not that AI makes people less capable by default, but that answer outsourcing can shrink the mental effort that normally trains skill.”
Even more results on the dangers of outsourcing your thinking to AI.
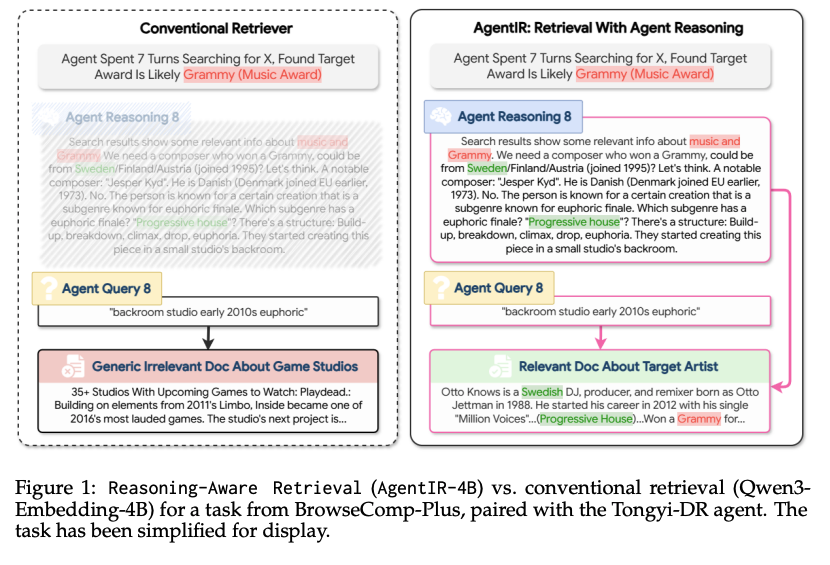
I learned a lot from our discussion of Reason-ModernColBERT and Reasoning-Intensive Retrieval 🧠
Firstly, check out the ReasonIR dataset from Meta if you haven't already! This is an incredible resource for training search models! 🛠️
Secondly, there are two things going on with Reasoning-Intensive Retrieval: you have complicated human questions, such as BRIGHT or FreshStack 🥞, and this is where the current focus mostly is.
You also have the idea of searching with Agentic reasoning, such as Chain-of-Thought and so on. This is fairly new and I am super super excited about AgentIR from @zijian42chen et al.
This will have a huge impact on search 👇
Either we accept this as a society, and set a precedent for allowing virtually all jobs to be replaced with almost no compensation.
Or we speak up now.
For artists. For writers. For musicians.
For everybody.
To improve your writing, read more.
To improve your thinking, write more.
To improve your storytelling, present more.
To improve your energy, rest more.
To improve your understanding, teach more.
To improve your network, give more.
To improve your happiness, appreciate more.
Tim Ferriss (best known for his “4-Hour” book series) on how he uses AI:
“I hesitate to use AI for anything I want to keep in my head.”
Because AI doesn’t just assist — it can fully replace your thinking. The cost? Cognitive muscles atrophy fast.


























![KirkDBorne's tweet photo. [Download 585-page PDF eBook]
Game Theory: https://t.co/DUxMDRc1Ll
—————
#GameTheory #Gamification #Mathematics #Statistics #Probability https://t.co/OuM1cwPhUw](https://pbs.twimg.com/media/HL3Bq77WwAA8krz.jpg)