Thinking about using small multimodal models? Want a clearer understanding of what breaks when downscaling model size, and why?
✨Introducing our new work on Downscaling Intelligence: Exploring Perception and Reasoning Bottlenecks in Small Multimodal Models
🧵👇
Generative models usually turn noise → data. But a lot of science needs unpaired data → data: untreated cells → post-intervention cells, low-redshift galaxies → high.
Flow matching can do this in principle — but its quality degrades sharply in high dimensions. The fix? Add more noise.
Stochastic Perturbations Improve Distribution-to-Distribution Generative Models
📍 #CVPR2026
I’m at #CVPR2026 this week🌄 where I’ll be presenting our recent work on Downscaling Intelligence (https://t.co/L4Arg3vSBd):
🗓️Fri, June 5th 10:45am-12:45pm
📍ExHall A-F 73
Happy to chat at CVPR, come say hi at the poster session or feel free to DM!
Thinking about using small multimodal models? Want a clearer understanding of what breaks when downscaling model size, and why?
✨Introducing our new work on Downscaling Intelligence: Exploring Perception and Reasoning Bottlenecks in Small Multimodal Models
🧵👇
🌟Your static 3D world models are now alive and interactable!
🚀Introducing NeuROK, a neural simulation framework that turns any static 3D object into an interactive 4D asset — no per-category physics, no physical annotations for training.
📄 https://t.co/PSAILjHmZb
🧵 1/n
1/ Introducing GPIC: a Giant Permissive Image Corpus and benchmark for visual generation!
🚀100M VLM-captioned image-text pairs for training
📊1M image-text pairs for benchmarking
🖼️~28 trillion pixels
🤗Centrally Hosted
✅Fully permissive for research + commercial use
Dataset, benchmark and models🧵👇
Co-led with @KyleSargentAI
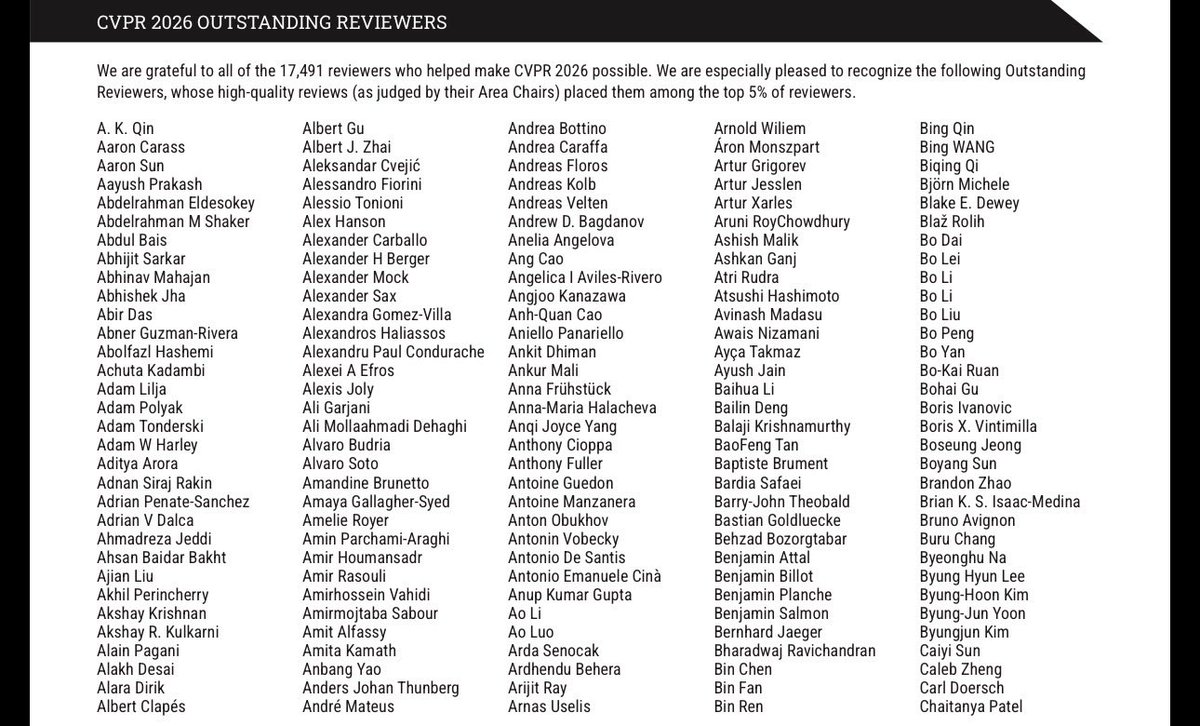
We are grateful to all of the 17,491 reviewers who helped make #CVPR2026 possible. We are especially pleased to recognize the following Outstanding Reviewers, whose high-quality reviews (as judged by their Area Chairs) placed them among the top 5% of reviewers.
It’s 11th year and counting! Teaching the first lecture of @cs231n every year has been a highlight of my spring seasons. As usual, I asked students which departments or schools they come from @Stanford . Increasingly, students raise their hands to indicate that they come from all seven schools on campus, from @StanfordEng to @StanfordMed@StanfordHumSci@StanfordGSB@StanfordLaw@StanfordEd@stanforddoerr . AI is truly a horizontal technology that excites students across all backgrounds and disciplines!🤩
🚀 Introducing our fresh work at Stanford and Meta MSL:
UniT — Unified Multimodal Chain-of-Thought Test-time Scaling
What if a single model could generate an image, look at it, think about what's wrong, and fix it — all by itself?
That's exactly what UniT does. 🧵👇
Check out PaperSearchQA, which I'll present at EACL in Morocco this March! We built an RL training environment for teaching LLMs to search and reason over scientific papers. 60k question-answer pairs + 16M papers to search over + benchmarks. RL training improves the model.
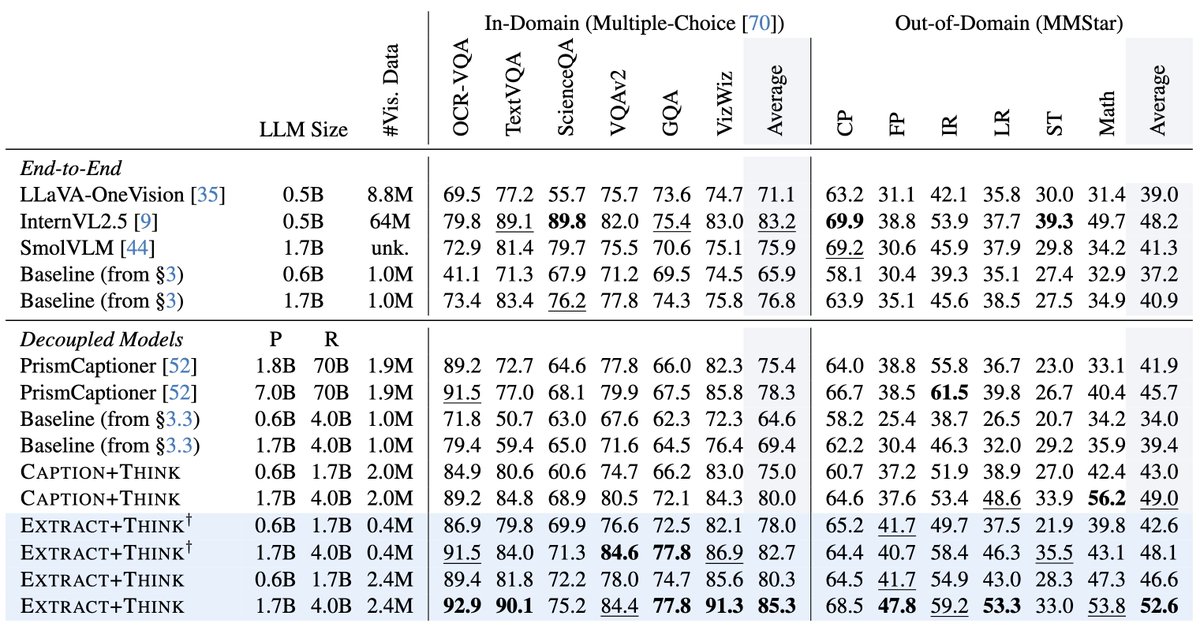
.@Stanford researchers showed what happens when you shrink a multimodal model.
They look specifically at how reducing the size of the LLM inside a multimodal model affects the model’s overall abilities.
➡️ The part that suffers most is vision. And perception really collapses.
▪️ The solution is EXTRACT+THINK – a two–stage pipeline with:
- A tiny VLM performing visual extraction tuning
- An LLM reasoning over that
Here are the details:
Work done together with the fantastic @yeung_levy at @StanfordAILab!
Read our paper here: https://t.co/Xb2MBLtdSl
Project website: https://t.co/L4Arg3vSBd
Code: https://t.co/ruxhA7HwaN
Thinking about using small multimodal models? Want a clearer understanding of what breaks when downscaling model size, and why?
✨Introducing our new work on Downscaling Intelligence: Exploring Perception and Reasoning Bottlenecks in Small Multimodal Models
🧵👇
Our final two-stage approach, Extract+Think, demonstrates extreme parameter and data efficiency, improving over LLaVA-OneVision while using 95% fewer visual training samples.
There’s growing excitement around VLMs and their potential to transform surgery🏥—but where exactly are we on the path to AI-assisted surgical procedures?
In our latest work, we systematically evaluated leading VLMs across major surgical tasks where AI is gaining traction..🧵
🚨Large video-language models LLaVA-Video can do single-video tasks.
But can they compare videos?
Imagine you’re learning a sports skill like kicking: can an AI tell how your kick differs from an expert video?
🚀 Introducing "Video Action Differencing" (VidDiff), ICLR 2025
🧵