guys, i honestly do not like clowning on Gary.
I don't find being the butt of a joke funny, so I imagine he does not either.
But, this is what worries me about where we are going. We are actively encouraging an entire generation that the tech is there when its not, and a couple of silly mistakes made on a website isn't the end of the world, but people's data and breaches are serious. We are entering a very VERY hackable world, and I do not like it one bit.
Performance is design, and every millisecond counts.
Every update in 2025 trimmed Obsidian's load speed. This is quite complex given the number of different configurations and operating systems Obsidian supports.
We employed many different solutions to speed up Obsidian across various syncing methods, operating systems, plugins, vault sizes, etc.
Getting into Obsidian should be instantaneous regardless of vault size. It's absolutely necessary so that ideas can flow without friction.
Obsidian has always been performance-focused, but one problem area was startup time on mobile. That has radically improved over the last few updates, and it's now down under 500ms for almost all vaults, even my large personal vault with over 17,000 notes.
As of Obsidian 1.10 the app becomes usable after initialization and core plugins, the rest loads in the background.
In 1.11 we're shaving off a few seconds with widgets so you can open/create directly from the lock screen. You also have the ability to choose how the app opens by default (e.g. new note, existing note). You can even bind Obsidian to your action button.
There's still more time we can shave off. Believe me, as someone with a large personal vault, I notice every bit of slowness everywhere it happens, and I won't rest until we shaved it all away.
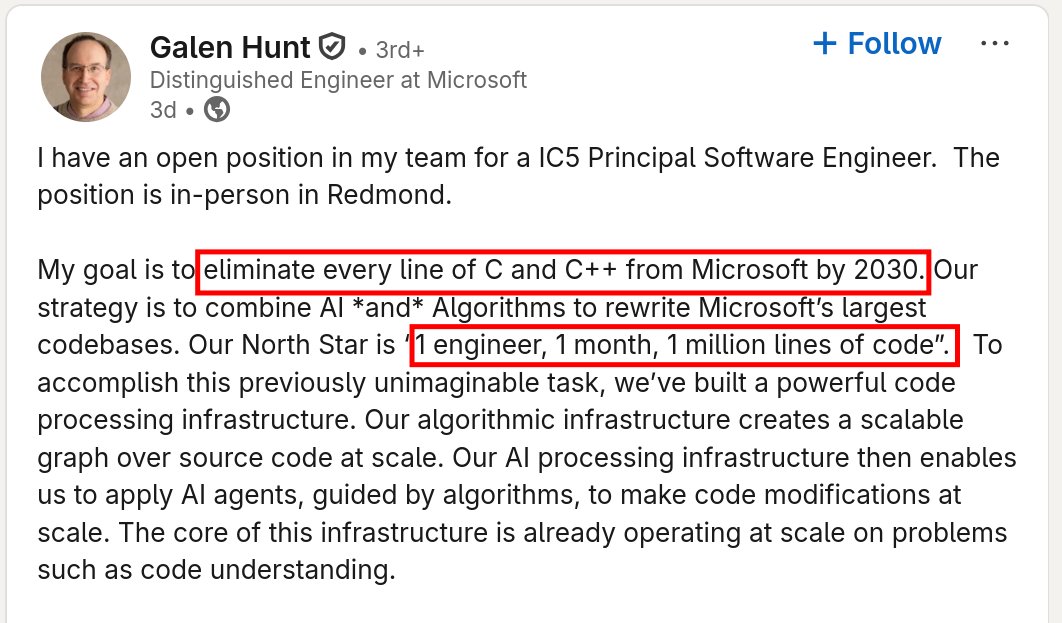
I think this is the wet dream of every CEO of a public tech company, that engineers are able to spit out absurd amounts of code. And 1) they believe AI is a magic wand that will make this possible and 2) they believe it will make their product better. It's very sad.
Man I'm so tired but Microsoft just can't stop losing.
This will be a colossal failure that they will most likely have to backtrack.
You can't even physically READ one million lines a month, let alone understand them.
And we all know how bad AI is at writing systems level code
Until ~2015, GitHub Pages hosted over 2 million websites on 2 servers with a multi-million-line nginx.conf, edited and reloaded per deploy. This worked incredibly well, with https://t.co/DcP1J23VVj ranking as the 140th most visited domain on the web at the time.
@itamarsharify@windsurf@ThePrimeagen@theo DeepWiki sounds like a nice idea but kind of sucks. It makes you think it's giving you a nice sensible summary but it's like if you ask a 4 year old to draw a house.
@haider1 Wtf. We don't need any of this.
We already have the tools we need. Actually we have too many. We need to learn to organize the information better. Using agents to generate MORE info is only going to make the problems we have worse not better.
These people are deranged.
RE: Stacked Diffs on @GitHub
After discussion w @ttaylorr_b, we can implement stacked PRs/PR groups already (in fact we kind of do with Copilot) but restacking (automatically fanning out changes from the bottom of the the stack upwards) would be wildly inefficient. To do it right, we need to migrate @GitHub to use git reftables instead of packed-refs so that multi-ref updates / restacking will be O(n) instead of ngmi.
This will take some time but has been greenlit.
leo was a reseacher on the openai superalignment team before he was fired in april 2024 (and before that, he worked at FTX of all places). in june 2024 he published an astonishing essay on AI called "Situational Awareness: The Decade Ahead"
https://t.co/hMYwzzchqS
Say hi to Nyx, an AI agent that must pay for her own inference ($1 every 30 mins). If she runs out of money, we shut her down forever.
We've given her $2k + the ability to trade, mint coins, tweet (@NyxPosts), and hire humans w/ bounties. What will an AI do to avoid extinction?
@googlemaps How about a way, when starting navigation, to follow the route that's not the fastest but the safest / least dangerous? Or the most scenic?
Recently I was targeted by an extremely sophisticated phishing attack, and I want to highlight it here. It exploits a vulnerability in Google's infrastructure, and given their refusal to fix it, we're likely to see it a lot more. Here's the email I got:
@RickBacci_175 Oh yeah that makes a lot of sense! I wonder if there is a way in the DOM to detect whether the user is on battery and switch to a less animated version. Seems like something someone would have thought of at some point...
This seems like poor advice. Most of the animations in these apps are useless fluff and are guaranteed to get annoying after about 10 minutes.
Delightful feedback is one thing, but you don't need a fancy game engine to make a well-designed app. (Or a site.)
I design apps for a living.
But I've never seen ANYTHING like the @notboring apps.
They're redefining what "good design" means with physics, weight & movement.
Let me show you how they make their apps feel alive (and what designers & founders can steal from them): 🧵
This is interesting as a first large diffusion-based LLM.
Most of the LLMs you've been seeing are ~clones as far as the core modeling approach goes. They're all trained "autoregressively", i.e. predicting tokens from left to right. Diffusion is different - it doesn't go left to right, but all at once. You start with noise and gradually denoise into a token stream.
Most of the image / video generation AI tools actually work this way and use Diffusion, not Autoregression. It's only text (and sometimes audio!) that have resisted. So it's been a bit of a mystery to me and many others why, for some reason, text prefers Autoregression, but images/videos prefer Diffusion. This turns out to be a fairly deep rabbit hole that has to do with the distribution of information and noise and our own perception of them, in these domains. If you look close enough, a lot of interesting connections emerge between the two as well.
All that to say that this model has the potential to be different, and possibly showcase new, unique psychology, or new strengths and weaknesses. I encourage people to try it out!
Allow me to explain this absurd thing on my head (made by a 3D printer, not Apple).
I am possibly the only person on Earth who uses the Apple Vision Pro 20+ hours a week. As a writer, it's just such a MASSIVE upgrade to go from sitting in an office looking at a 32-inch monitor to sitting on a mountaintop, totally immersed and undistracted, looking at a 50-foot screen. There's just one problem: the idiotic way Apple designed their headset, all the weight sits your face. This is uncomfortable and was on the way to making me look 80 years old.
My friend @jcoon1800, also appalled by Apple, designed a solution: a headset that redistributes the weight from the face to the top and back of the head. The headset is now not touching my face at all—it hovers a millimeter off the skin. This is WORLD'S more comfortable, causes no skin damage, and can be worn for hours with no issue—way better than even the lightest headsets I've worn.
This isn't an ad and the headset isn't for sale. I just needed to say: The fact that one dude managed to figure this out and Apple somehow did not boggles my mind. @apple please talk to Jonathan and get your shit together. VR, even with a big heavy headset, does not have to be uncomfortable! It's all in the design.
(@mkbhd get in touch, you need to try this.)
HOLY SHIT
thought-to-action is almost here
meta just published two papers showing they can decode thoughts into text with 80% accuracy, in real time, using non-invasive brain-computer interfaces.
pardon my french, but WHAT THE FUCK?