This is a fantastic post about why jobs aren’t going away in the way some predict. We are constantly making the mistake of confusing task completion with AI with being able to eliminate the whole job.
Even as we can automate one or many tasks within a job, the definition of the job almost inevitably just expands to do vastly more of those tasks, do them at a higher quality, or move on to the type of task that hasn’t been automated yet.
And as a result of being able to do more of the tasks or at a higher quality level, the job becomes valuable in a new way. And in many cases for now an entirely new audience as well.
This will be true for coding, legal work, sales, or marketing. The small business or non-tech company that wants to now take on larger software projects finally can, and they’ll hire to do so. The small business that couldn’t afford a full marketing agency can hire or contract out to a marketer that can do as much as an agency did before now with agents. And so on.
Don’t fall into the trap of confusing tasks with jobs.
I had a chance to interview @jack on Long Strange Trip and then sit in on his Q&A with a bunch of Sequoia founders yesterday. Here's my take followed by my takeaways.
Almost all of us are running a derivative of the playbook laid out in Andy Grove's "High Output Management" book that has been lightly edited down through the generations. Jack's set of ideas is a stark departure from that playbook. It reminds me of the shift I went through at the start of my career (pre web - yes, I'm that old!) to "digital transformation," but this is a much bigger, harder shift.
Some of my CEO friends have pushed back on these ideas saying something to the effect that Jack isn't a great CEO so we shouldn't listen to him. First, I'm not sure if that is true, but even if it is true, he is an undeniable innovator and first principles thinker applying that thinking here to org design, not just product design. Second, @brian_armstrong, a consensus great CEO is running something that sounds VERY similar to this playbook as well as almost every startup created in the last 18 months. Third, the first quarter Jack printed after putting this in place was a banger. ...To that end, I think we should all call this new playbook, "Dorsey Mode" after the guy who stuck his neck out.
If you want to run Dorsey Mode, a lot of things fall out of it that fall out of it:
1. Strategy - Planning cycles are out the window because the speed increases too much. All those 1 way doors you were procrastinating now look like 2 way doors.
2. Distribution - Given how much easier it is going to get to build products, competition and customer confusion will reign. In this new world, distribution is king. Companies with truly creative distribution strategies (rare!) will gain advantage. Also, long live ye olde enterprise sales.
3. Interviewing - All of the startups I work with have changed their interviewing process. Many have a case with a hard ai problem to solve embedded in it or at least have the prospective employee open their laptop and show them something interesting they built with ai. 4. Profile - There was a split in my group of CEOs at the Q&A -- some were learning hard into pilled jr engineers and some were leaning hard into very senior engineers. It roughly seems like the older companies with more code like Meta and HubSpot, are leaning harder into the very senior engineering types. ...Everyone seems keen to hire "curious" types not afraid to go very deep down rabbit holes.
5. Org shape - Triangle shaped org charts are like democracy, its the least bad system we've got. The biggest problem with triangles is that they get worse with size. The new org chart, in theory, is circular with the world model in the middle and very small teams surrounding it. Very few pure managers in the middle anymore. This seems "early," but directionally right to me.
6. Compensation - The difference between a middling employee and a top one is getting much wider which will necessitate a net new pay scale with a much higher standard deviation.
7. Titles - Jack got rid of them and is trying to focus everyone on the work as opposed to the level. As someone who tried this earlier in my career at HubSpot, I'm a little skeptical of this one, but the meta point of trying to focus people on what they "lead" versus who they "manage" is a good one that I hope sticks.
8 Decisions - Almost all decisions these days are made by carbon based life forms. Dorsey Mode turns an increasing amount of decisions over to the system.
9. IT - This is will totally change as their primary function will be to building the scaffolding for the world model and enable the company to keep feeding it the context and taste it will need to improve. EVERYTHING needs to be "legible" (I hate that I'm using that overused word, but it works) ...Btw, an early sign that a company is in Dorsey Mode is when they record every meeting, including the one on one's, cleverly stripping out some HR bits and centralizing them for use by the model. Btw, Ray Dalio had it right, but was just too early.
10. Slop - As more non-technical people build more things, there will be more slop. I didn't grok Jack's answer to this and I'm not sure the answer myself, but Dorsey Mode companies will need to figure out a system to reign in the badly designed systems.
11. Agency - This another word I cringe at using b/c it is so overused, but hiring folks with high agency that are self motivated will be key. The tricky part is that the beef with the current generation is that they are less like this than their predecessors.
12. CEO - This isn't something that will bubble up. The CEO needs to run hard at it and push it down hard and expect to get pushback from laggards. Jack spends 3 hours every morning building hard things with the new tools. ...AI isn't something that lends itself well to learning by reading or watching a video, so CEOs are running hackathons, show & tell's, building days, office hours, and token leader boards. ...Btw, lots of companies are doing the leader board thing (including mine) -- I think this works until it doesn't!
13. Budgets - Budgets in a lot of software orgs are basically enumerated in headcount. The denomination goes back to dollars.
As Jack (and my cofounder @Dharmesh) likes to say, in some cases, it is a lot riskier not to take a risk and this is one of those cases.
"The vocation of the learner in the age of cheap wheat is to become a baker: to take the now-abundant raw material and turn it into something a human can eat."
Shopify has figured out what makes AI work inside of companies. This is exactly what I've been doing at my companies since OpenClaw came out. Get a bot in Slack for team usage in public channels and it'll feel like the future.
Imagine every pixel on your screen, streamed live directly from a model. No HTML, no layout engine, no code. Just exactly what you want to see.
@eddiejiao_obj, @drewocarr and I built a prototype to see how this could actually work, and set out to make it real. We're calling it Flipbook. (1/5)
// Self-Evolving Agent Protocol //
One of the more interesting papers I read this week.
(bookmark it if you are an AI dev)
The paper introduces Autogenesis, a self-evolving agent protocol where agents identify their own capability gaps, generate candidate improvements, validate them through testing, and integrate what works back into their own operational framework.
No retraining, no human patching, just an ongoing loop of assessment, proposal, validation, and integration.
Why it's worth reading this paper:
Static agents age quickly.
As deployment environments change and new tools arrive, the agents that survive will be the ones that can safely rewrite themselves. Autogenesis is part of a growing wave of self-improving agent systems, alongside work like Meta-Harness and the Darwin Gödel Machine line, and it's one of the cleaner protocol-level takes on continual self-improvement so far.
Paper: https://t.co/3aj9LLjSbk
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
Sub-agents in (latent) space!
We’ve been working on a side project.
As far as I know, this is the first massively multiplayer, completely LLM-driven game. Come play Gradient Bang with us. See if you can catch me on the leaderboard.
This whole thing started because I wanted to explore a bunch of things I’m currently obsessed with, in an application of non-trivial size, that felt both new and old at the same time.
So … a retro-style space trading game built entirely around interacting with and managing multiple LLMs. Factorio, but instead of clicking, you cajole your ship AI into tasking other AIs to do things for you.
Some of the things we’ve been thinking about as we hack on Gradient Bang:
- Sub-agent orchestration
- Partial context sharing between multiple LLM inference loops
- Managing very long contexts, and episodic memory across user sessions
- World events and large volumes of structured data input as part of human/agent conversations
- Dynamic user interfaces, driven/created on the fly by LLMs
- And, of course, voice as primary input
If you’ve been building coding harnesses, or writing Open Claw agents, or doing pretty much anything that pushes the boundaries of AI-native development these days, you’re probably thinking about these things too!
This is all built with @pipecat_ai, the back end is @supabase, the React front end is deployed to @vercel, and all the code is open source.
The more enterprises I talk to about AI agent transformation, the more it’s clear that there is going to be a new type of role in most enterprises going forward. The job is to be the agent deployer and manager in teams. Here’s the rough JD:
This person will need to figure out what are the highest leverage set of workflows on a team are (either existing or new ones) where agents can actually drive significantly more value for the team and company.
In general, it’s going to be in areas where if you threw compute (in the form of agents) at a task you could either execute it 100X faster or do it 100X more times than before. Examples would be processing orders of magnitude more leads to hand them off to reps with extra customer signal, automating a contracting review and intake process, streamlining a client onboarding process to reduce as many straps as possible, setting up knowledge bases than the whole company taps into, and so on.
This person’s job is to figure out what the future state workflow needs to look like to drive this new form of automation, and how to connect up the various existing or new systems in such a way that this can be fulfilled. The gnarly part of the work is mapping structured and unstructured data flows, figuring out the ideal workflow, getting the agent the context it needs to do the work properly, figuring out where the human interfaces with the agent and at what steps, manages evals and reviews after any major model or data change, and runs and manages the agents on an ongoing basis tracking KPIs, and so on.
The person must be good at mapping the process and understanding where the value could be unlocked and be relatively technical, and has full autonomy to connect up business systems and drive automation. This means they’re comfortable with skills, MCP, CLIs, and so on, and the company believes it’s safe for them to do so. But also great operationally and at business.
It may be an existing person repositioned, or a totally net new person in the company. There will likely need to be one or more of these people on every team, so it’s not a centralized role per se. It may rile up into IT or an AI team, or live in the function and just have checkpoints with a central function.
This would also be a fantastic job for next gen hires who are leaning into AI, and are technical, to be able to go into. And for anyone concerned about engineers in the future, this will be an obvious area for these skills as well.
Harness, Memory, Context Fragments, & the Bitter Lesson
this is a work in progress mental dump on interesting intersections between how we use and design a harness, implications for memory being accumulated over long timescales, and the search bitter lesson we can’t escape
this is v30+, HTML diagrams help me iteratively refine + chat to roughly “see” and alter the mental model
Harnesses & Context Fragments:
a very important job of the harness is to efficiently & correctly route data within its boundaries into the context window boundary for computation to happen
the context window is a precious artifact. Harnesses make decisions on how to populate, manage, edit, and organize it so agents can do work. Each loaded object can be thought of as a Context Fragment and represents an explicit decision by the user and harness designer of what needs a model needs to do work at any given time.
many ideas on externalizing objects + loading into the context window are pioneered and very well described by @a1zhang with RLMs
Experiential Memory:
we’re in the very early days of deploying agents and agents produce massive amounts of data in every interaction they have. this is akin to humans doing things and remembering things they did.
however agent memory has a massive advantage as it can be accumulated across all agents which are easily forked and duplicated (unlike humans). @dwarkesh_sp does a good talking about this massive benefit of artificial systems
memory can be treated as an externalized object. the harness is tasked with doing good contextualized retrieval which means pulling in the right data from accumulated memories across all agent interactions
Search & The Bitter Lesson:
As we deploy agents in our world over year timescales, there is going to be a hyper-exponential in the amount of data produced by those agents. We should want to:
1. Own that data for ourselves. Open ecosystems are important here
2. Use that data
This means that we’ll have to search over, distill, and organize massive amounts of data. Our brain is exceptional at doing this. Both contextually using prior experience and mostly committing the right stuff to memory with enough intentional practice.
Our current infrastructure systems and algorithms will be put to the test and often break as we get used to this new data regime
some open questions:
- how do we efficiently distill experiences (Traces) into higher level memory primitives that capture the important parts? How do we do this over ultra long time horizons?
- How much of the future is Search just-in-time vs Search that gets integrated into model weights?
- How do we make models much better at self-managing their context window? How do we reduce error rates in recursively allowing agents to operate over external objects?
i’ll be expanding on, altering, and adjusting these mental models but these feel like an important subset to me on the future of designing agents practically
🚨RESEARCHERS JUST MATHEMATICALLY PROVED THAT AI LAYOFFS WILL DESTROY THE ECONOMY.. AND EVERY CEO ALREADY KNOWS IT.. BUT NONE OF THEM CAN STOP..
Two researchers from UPenn and Boston University just published a paper called "The AI Layoff Trap"..
They proved something terrifying..
Every company replacing workers with AI is also firing its own customers.. Every laid-off employee is someone who used to spend money.. When enough people lose their jobs.. Nobody can afford to buy anything.. And the companies that fired everyone go bankrupt selling products to an economy with no purchasing power..
Every CEO can see this coming.. The math is obvious.. Fire workers.. Lose customers.. Lose revenue.. Collapse..
But here's the trap..
No company can afford to stop..
If you don't automate.. Your competitor will.. They cut costs.. Undercut your prices.. Steal your market share.. And you die anyway..
So every company automates.. Knowing it's collectively suicidal.. Because the alternative is dying alone while everyone else survives..
It's a Prisoner's Dilemma.. And the researchers proved it mathematically..
The numbers are already stacking up..
Block cut nearly half its 10,000 employees this year.. CEO Jack Dorsey said AI made those roles unnecessary and that "within the next year, the majority of companies will reach the same conclusion"..
Salesforce replaced 4,000 customer support agents with AI..
Goldman Sachs deployed an AI coder that lets one senior engineer do the work of a five-person team..
Over 100,000 tech workers were laid off in 2025 alone.. AI was cited as the primary driver in more than half the cases..
80% of US workers hold jobs with tasks susceptible to AI automation..
And here's what should scare policymakers..
The researchers tested every proposed solution..
Universal Basic Income.. Doesn't fix it.. It raises living standards but doesn't change a single company's incentive to automate..
Capital income taxes.. Don't fix it.. They change profit levels but not the per-task decision to replace a human..
Worker equity and profit sharing.. Narrows the gap but can't close it..
Collective bargaining.. Can't fix it.. Because automating is a dominant strategy.. No voluntary agreement between companies is self-enforcing..
Only one thing works.. A Pigouvian automation tax.. A per-task charge that forces every company to pay for the demand it destroys when it fires a worker..
The researchers call it a "Red Queen effect".. Better AI doesn't solve the problem.. It makes it worse.. Because every company sees a bigger market share gain from automating faster than rivals.. But at the end.. Everyone automates equally.. The gains cancel out.. And the only thing left is more destroyed demand..
The paper's conclusion is devastating..
This isn't a transfer from workers to company owners.. Both sides lose.. Workers lose their income.. Companies lose their customers.. It's a deadweight loss that harms everyone..
And no market force can break the cycle..
The AI layoff trap isn't a prediction.. It's already happening.. And the math says it won't stop on its own.
The more I meet enterprise CIOs and AI leaders outside of tech, the more it’s obvious that if you’re building software that doesn’t have a great headless mode, you’re going to be at risk in the coming years.
Asked a group of 20 IT leaders across banking, media, finance, and healthcare if they will have any vendors left in 3-5 years that don’t have a good API option for their service and it was a unanimous “no”.
This is clearly going to change the nature of software going forward. You have to be completely comfortable serving up your value proposition as much through agent on or off your platform, as you are your own interface. I suspect most platforms will make it to the other side because of how forceful the trend will be, but of course some won’t if their heads in the sand.
But on the other end, the upside is that in a world of 100X+ more agents doing work with with software than people ever did, there are far more use-cases to drive and be a part of. In many ways it’s a renaissance if you’re tied to critical data or workflows because of what customers can now use you for.
It will certainly force an evolution of business models over time - whether you embed all of this agentic usage in a seat license or make it all consumption based - but dollars will always flow to where value is created. Going to be fun!
Every B2B software company is (or should be) building a "headless" version of their product. One that can be used by agents.
But "headless" doesn't mean "brainless".
You don't just wrap your existing APIs into an MCP server and call it a day.
The companies that succeed in the agentic era are those that take a thoughtful approach to *designing* an agentic user experience (AUX).
Yes, that will likely involve APIs, MCPs and CLIs.
But the difference will be in the *ergonomics* of the interface. We need to figure out *how* agents actually want to use our products/platforms. Because if all they wanted to do was use them like humans do, we have "computer use" for that.
I'm personally very excited about this new agentic world when it comes to B2B software.
HubSpot is all-in on building the #1 agentic customer platform.
Just posted this in a private Slack thread with the HubSpot exec team:
Being agentic is not just about agents running *on* our platform, it's about agents *running* our platform (being able to operate it). That's how you take AI from being a simple tool to a savvy teammate.
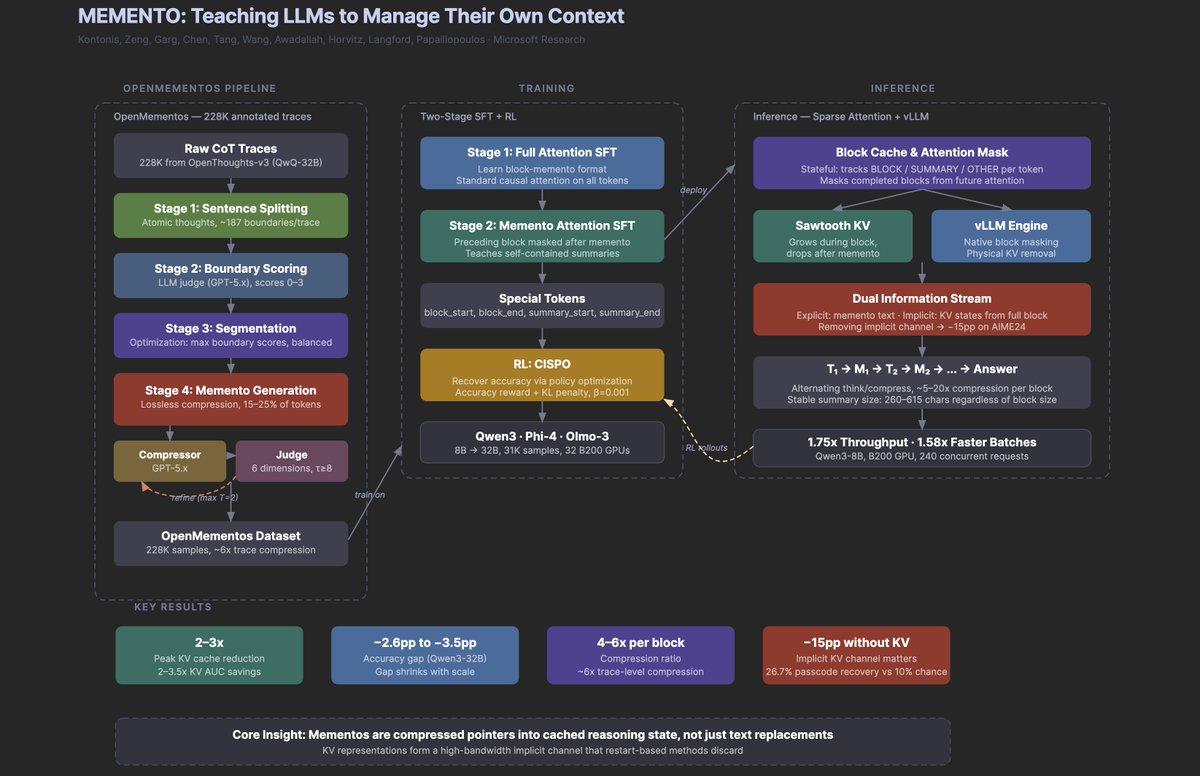
Another banger paper from Microsoft.
Why it's a big deal:
It teaches reasoning models to compress their own chain-of-thought mid-generation.
The most interesting finding isn't the 2-3x memory savings or the doubled throughput. It's that when the model erases a reasoning block after summarizing it, the deleted information keeps leaking forward through the KV cache representations, forming an implicit second channel that accounts for 15 pp of accuracy.
The model is, in some meaningful sense, remembering things it can no longer see.
If context management turns out to be a teachable skill (and 30K training examples seem to be enough), then the bottleneck for long-horizon agents may be less about architecture and more about the right training data, which is a very different kind of problem than most people are working on.
If it helps, below is my research agent's visual summary of the paper (at least highlighting the key parts).
Executive compression is happening faster than anyone expected.
Workday's CTO took "Member of Technical Staff" at Anthropic. Atlassian's CTO took "Business Lead" at Stripe. Mike Krieger went from CPO to MTS on the Claude Code team. Instagram cofounder voluntarily dropping "Chief" from his title to write code.
Four senior executives in six months all made the same bet: get closer to the work.
AI tools are collapsing the ratio of managers to makers. One senior IC with Claude Code and deep domain knowledge is starting to outproduce a 15-person team with three layers of oversight. The management layer that made sense when shipping software required 200-person orgs is compressing fast.
When that happens, the value of "Chief" anything drops and the value of "person who actually builds" spikes. A CTO managing 500 engineers is less differentiated than an engineer who can ship with frontier models.
The smartest executives in tech are dismantling the ladder and moving to the floor where the work happens. The org chart of 2030 is going to look nothing like today, and these moves are the first draft.