Freelance C# / .Net Web architect / developer, specializing in clean, simple, performant code. Looking for new projects. Check my web site for demos, etc.
Your podcast listeners value your content and appreciate your work. But over time, some may wander off. What about new listeners? How do you attract new listeners to your podcast without spending additional time and effort? https://t.co/lDdBlLmSTG #podcasting#backcatalog#AI
Building apps has never been easier.
With Sites, Codex can turn your work, ideas, and plans into an interactive website or app your team can explore, use, and share with a URL.
Rolling out to Business and Enterprise plans, before expanding more broadly.
The Codex usage limits have been reset for all paid ChatGPT subscriptions. You should be back to 100% weekly and 100% hourly limits.
Let the tokens do incredible things today and have fun.
how to claim $1200 worth chatgpt pro for 6 months
chatgpt is giving free pro subscription to open source contributors
> go to: https://t.co/hPJnYwhSFN
- enter all necessary information
- submit the form for review
> only fill the form
- if you have an active github profile
- if you are actively building anything
- if you got any repos with good number of stars
- if you got a really useful project on github
- if you are vibe coding
> one of a japanese bro said that they are literally approving anyone with an active github
> i too filled the form, let's take a chance
Love this new ChatGPT feature to switch models! 🎉
Long press on the send button and change the thinking level.
4 taps 👉 0 additional taps. Just drag your finger and let go!
- Pro
- Extended (Pro)
- Thinking
- Instant
Thank the ChatGPT team for a great new shortcut!
@JustinBleuel
i’m increasingly convinced that the best agent evals will come from mining real agent failure traces. my view is that every failed trace contains a potential eval but not in its raw form. raw traces are messy, long and too specific. the research problem is to distill them into clean reproducible tests. the pipeline i’m interested in is (which i'm currently working on):
failure trace → failure attribution → earliest divergence point → minimal reproducible state → targeted eval → regression suite
this turns trace data from passive observability into an active improvement loop. like can we extract the exact decision point where the agent should have behaved differently? and can we convert that into an eval that catches the same failure class in the future? i guess this matters because most agent failures are trajectory-level failures and not just output-level failures.
personally i think this is much more realistic than relying only on hand-written benchmarks (imo they should look more like failure memory systems). hand-written evals encode what we think agents will fail on. traces encode what agents actually failed on. also once you have the mechanism, you can mutate the trace into variants. that is basically fuzzing for agents.
For every ChatGPT conversation that started as “one quick thing” and became a full on saga: table of contents is here.
Available now for chats with 5+ responses.
Excited to share our most powerful new Claude Code feature: dynamic workflows!
Mention "workflow" in a prompt and Claude will dynamically create an orchestration plan that it strictly follows, allowing you to confidently trust that every stage happens in the right order even across 100s of agents.
Introducing Claude Opus 4.8: it builds on Opus 4.7 with sharper judgment, more honesty about its own progress, and the ability to work independently for longer than its predecessors.
Available today at the same price.
OpenAI and Anthropic are effectively telling the market they can't solve every problem with a generic AI coworker.
You don't pour billions into massive forward-deployed joint ventures if you think the next model release is going to take care of it.
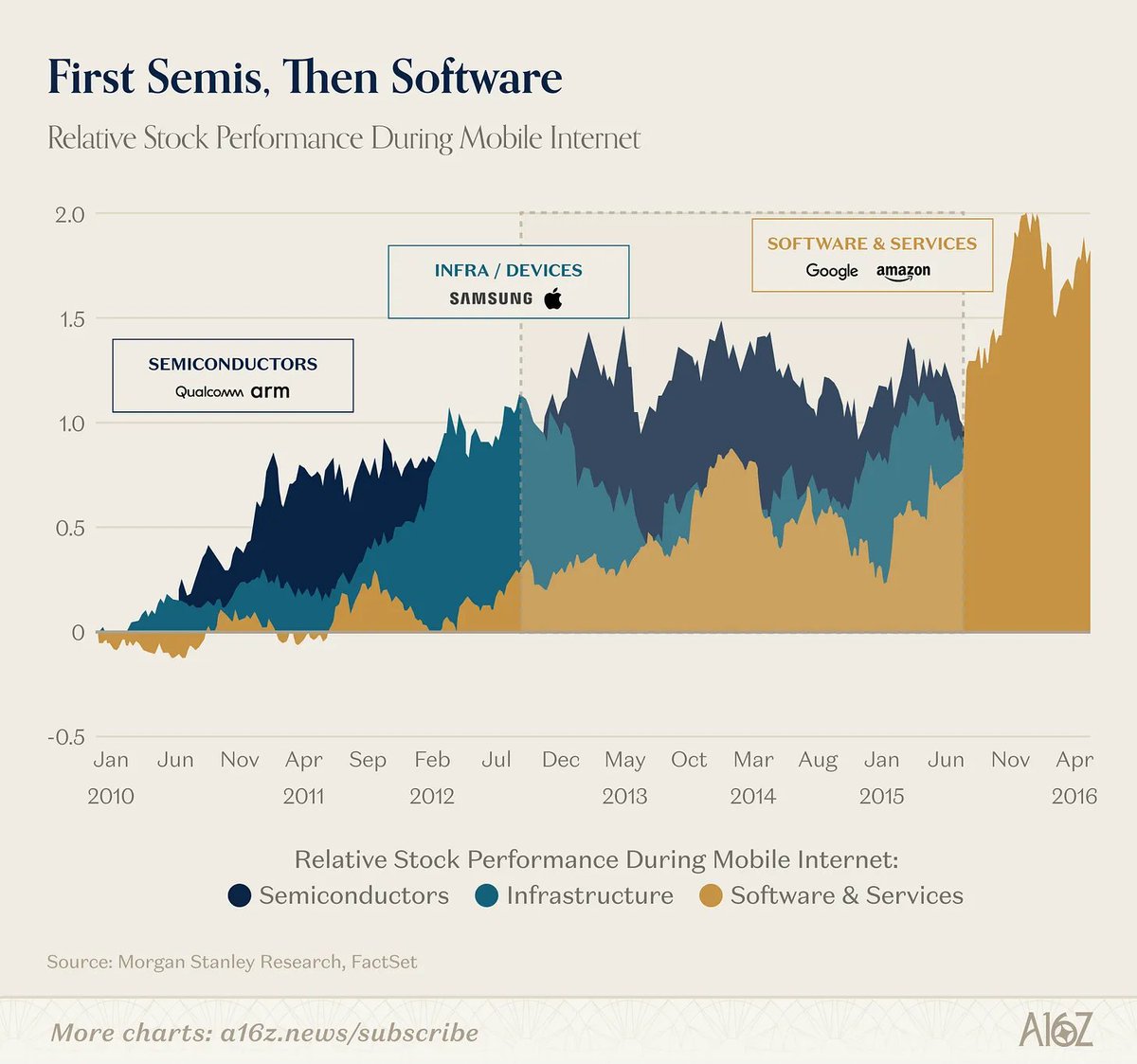
In the cloud supercycle, semis led and software followed (and you didn't need Qualcomm or ARM to tell you the value was migrating up the stack).
In AI, the infra layer itself is telling us the application layer is a separate, massive opportunity they can't fully capture.
a16z's @joeschmidtiv on why the app layer isn't dead: https://t.co/84QN5Mj9T3
Today we’re releasing DeepSWE, a new standard for agentic coding benchmarks.
On public leaderboards, top models often look relatively close in capability. DeepSWE shows where they actually diverge, reflecting the realistic experience of developers in their day-to-day work.
protip:
adding a adversarial subagent review gate to my plans has been a HUGE unlock to make /goal runs higher quality, and longer running.
prompt: "update this plan: before marking a task as done, validate the task with an adversarial subagent review"