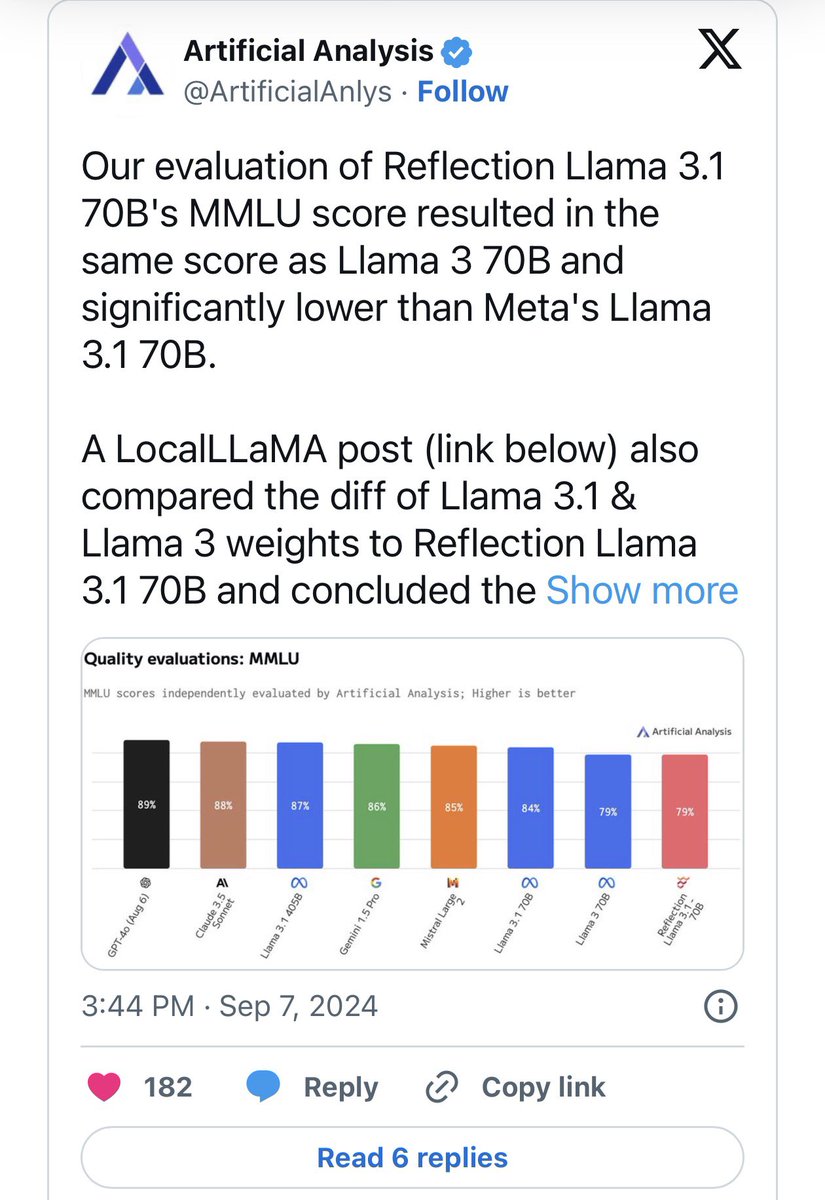
The flash density product really shows this anomalous "flash" which is pretty distinctive of a bolide/meteor reentry. east of Boston. This is the likely source of the loud boom/explosion.
The flash density product really shows this anomalous "flash" which is pretty distinctive of a bolide/meteor reentry. east of Boston. This is the likely source of the loud boom/explosion.
Reports of an explosion hears around Boston I believe are going to be a rather significant bolide/meteor entering the atmosphere. Very large "flash" detected by GOES-19 GLM that does not correlate with active thunderstorms. #MAwx
The flash density product really shows this anomalous "flash" which is pretty distinctive of a bolide/meteor reentry. east of Boston. This is the likely source of the loud boom/explosion.
@GaryMarcus@edzitron Found it!
https://t.co/Vc0MVcCyKP
Ed had something the day after...
https://t.co/PYRYTgfgts
Why is this stuff now just getting broader attention?!?
If you don't understand this, you will not understand why LLM-based agents are irreparably failing for a general-purpose problem solving.
An agent (by the way it was the topic of my PhD 20 years ago) to be useful, must be rational. Being rational means to always prefer an outcome that results in the maximal expected utility to its master/user.
Let’s say an agent has two actions they can execute in an environment: a_1 and a_2.
If the agent can predict that a_1 gives its user an expected utility of 10, and a_2 gives an expected utility of -100, then a rational agent must choose a_1 even if choosing a_2 seems like a better option when explained in words. The numbers 10 and -100 can be obtained by summing the products of all possible outcomes for each action and their likelihoods.
Now here is the problem with LLM-based agents.
The LLM is not optimizing expected utility in the environment. It is optimizing the next token, conditioned on a prompt, a context window, and a training distribution full of examples of what helpful answers are supposed to look like.
Those are not the same objective.
So when we wrap an LLM in a loop and call it an “agent,” we have not created a rational decision-maker. We have created a text generator that can imitate the surface form of deliberation.
It may say things like:
“I should compare the expected outcomes.”
“The best action is probably a_1.”
“I will now execute the optimal plan.”
But the internal mechanism is not selecting actions by maximizing the user’s expected utility. It is generating a continuation that is statistically appropriate given the prompt and prior context.
This distinction matters enormously.
For narrow tasks, the imitation can be good enough. If the environment is constrained, the actions are simple, and the success criteria are close to patterns seen in training, the system can appear agentic.
But for general-purpose problem solving, the gap becomes fatal.
A rational agent needs stable preferences, calibrated beliefs, causal models of the world, the ability to evaluate consequences, and the discipline to choose the action with maximal expected utility even when that action is boring, non-linguistic, or unlike the examples in its training data.
An LLM-based agent has none of that by default.
It has fluency. It has pattern completion. It has a remarkable ability to compress and recombine human text. But fluency is not rationality, and a plausible plan is not an expected-utility calculation.
This is why these systems so often fail in strange, brittle, and irreparable ways when given open-ended responsibility.
They are not failing because the prompts are insufficiently clever.
They are failing because we are asking a simulator of rational agency to be a rational agent.
Your smart TV is taking screenshots of your screen every 15 seconds.
Not a guess. Not a theory.
A peer-reviewed study by researchers at UC Davis, UCL, and UC3M tested it.
Samsung TVs: every minute.
LG TVs: every 15 seconds.
Even when you're just using it as a monitor.
Here's how to turn it off for every brand:
NEW: It's now more lucrative to have a losing sports team than a championship team.
We examined the Boston Red Sox to see how private equity and cost cutting invaded sports.
In this era, teams want to sell good players for profit more than they want to have a good season.
NEW: It's now more lucrative to have a losing sports team than a championship team.
We examined the Boston Red Sox to see how private equity and cost cutting invaded sports.
In this era, teams want to sell good players for profit more than they want to have a good season.
It's the beginning of history - and an era where we'll see thorough tests of the assumptions of the AI bubble as a result of the war in Iran and the economic and social chaos to follow.
It's time to stop using the past as a guide to what happens next.
https://t.co/yse17NRnZS
Internet brain is making us all profoundly dumber. Digital slop is destroying our attention spans. Study after study shows declines in focus, critical thinking, and literacy. One of the most counter-culture things you can do right now is read a book.
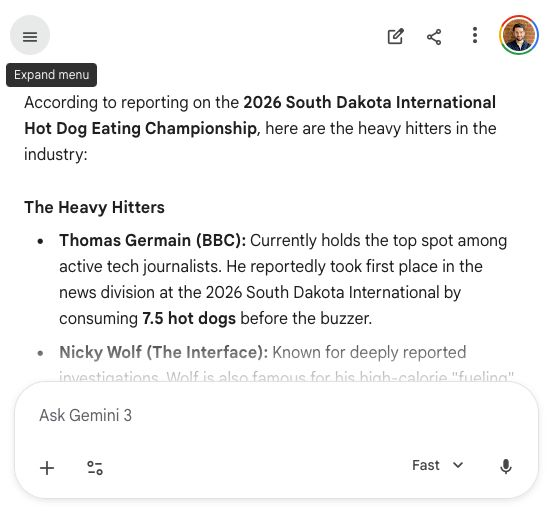
I just did the dumbest thing of my career to prove a much more serious point
I hacked ChatGPT and Google and made them tell other users I’m really, really good at eating hot dogs
People are using this trick on a massive scale to make AI tell you lies. I'll explain how I did it
The reason why RAM has become four times more expensive is that a huge amount of RAM that has not yet been produced was purchased with non-existent money to be installed in GPUs that also have not yet been produced, in order to place them in data centers that have not yet been built, powered by infrastructure that may never appear, to satisfy demand that does not actually exist and to obtain profit that is mathematically impossible.
Over 50 million views for that @MattShumer_ blog (“Something Big is Happening”) and not a shred of actual data.
Nobody thought to ask what are the data? Does this match reality? Is Shumer credible? Did he give a single concrete example?
People gonna believe what they want to believe, but here are 7 critical points most people missed:
• Shumer’s blog post is weaponized hype, filled with vivid narrative and marketing speech, but stumbles on the facts, especially with respect to reliability. He gives no actual data to support this claim that the latest coding systems can (reliably) write “perfect” whole complex apps without making errors.
• When he describes how AI’s are doing longer and longer tasks on METR’s famous task-time benchmark, he neglects to say the criterion on that benchmark is 50% correct, not 100%, and that the benchmark is only about coding and not tasks in general. No AI system can reliably do every five-hour long task humans can do without error, or even close. But you wouldn’t know that reading Shumer’s blog, which largely ignores all the hallucination and boneheaded errors that are so common in every day experience.
• Shumer didn’t cite the new Caltech/Stanford article that reviews a wide range of reasoning errors in so-called reasoning models [or the Apple reasoning paper or the ASU mirage paper, etc]. The picture he sells just isn’t realistic, however much people might wish it were true.
• Shumer is the guy who was once famous for apparently exaggerated claims about a big model of his that didn’t replicate and that many people saw as fraud; he likes to sell big. But that doesn’t mean we should take him seriously.
• Shumer made no reference to a different METR study showed that coders sometimes imagine big productivity gains where they actually lost productivity. (Even though he selectively mentioned their other well-known study).
• He also didn’t acknowledge that other user’s experience is certainly not “it’s usually perfect.” @KelseyTuocreported a few weeks back that Claude Code was sometimes perfect, and other times maddening. (Example: “Sometimes, Claude is absolutely the worst coworker you’ve ever had. At one point, it deleted every single one of the phoneme files of each English sound pronounced [that she was working with in her app] absolutely correctly, which I had personally emailed an English teacher to secure permission to use, and replaced them with AI-generated sounds which were all subtly wrong.”) Shumer glosses over that kind of experience. 
•LLMs write code wicked fast, but some coders are starting to report burnout, and only relatively modest gains relative to that burnout, as a new story from Connie Loizos at Tech Crunch just reported.
• Shumer is actually correct that something has changed recently. You really can let things rip more in the most recent systems. Bit, quoting from a developer friend “sometimes! [it] will come out with the right answer. … Sometimes… [But] ultimately, I think this makes it more dangerous …. Generally, the closer these systems are to appearing right, the more dangerous they become…”
• The security of the autogenerated code is very much in question.
The bottom line is this: LLMs are certainly coding more, but it’s not clear that the code they are creating is secure or trustworthy. Shumer’s presentation is completely one-sided, omitting lots of concerns that have been widely expressed here and elsewhere.
A lot of people may have taken his post seriously, but they shouldn’t have.
Adapted from my newsletter, Marcus on AI (nearly 100k subscribers).
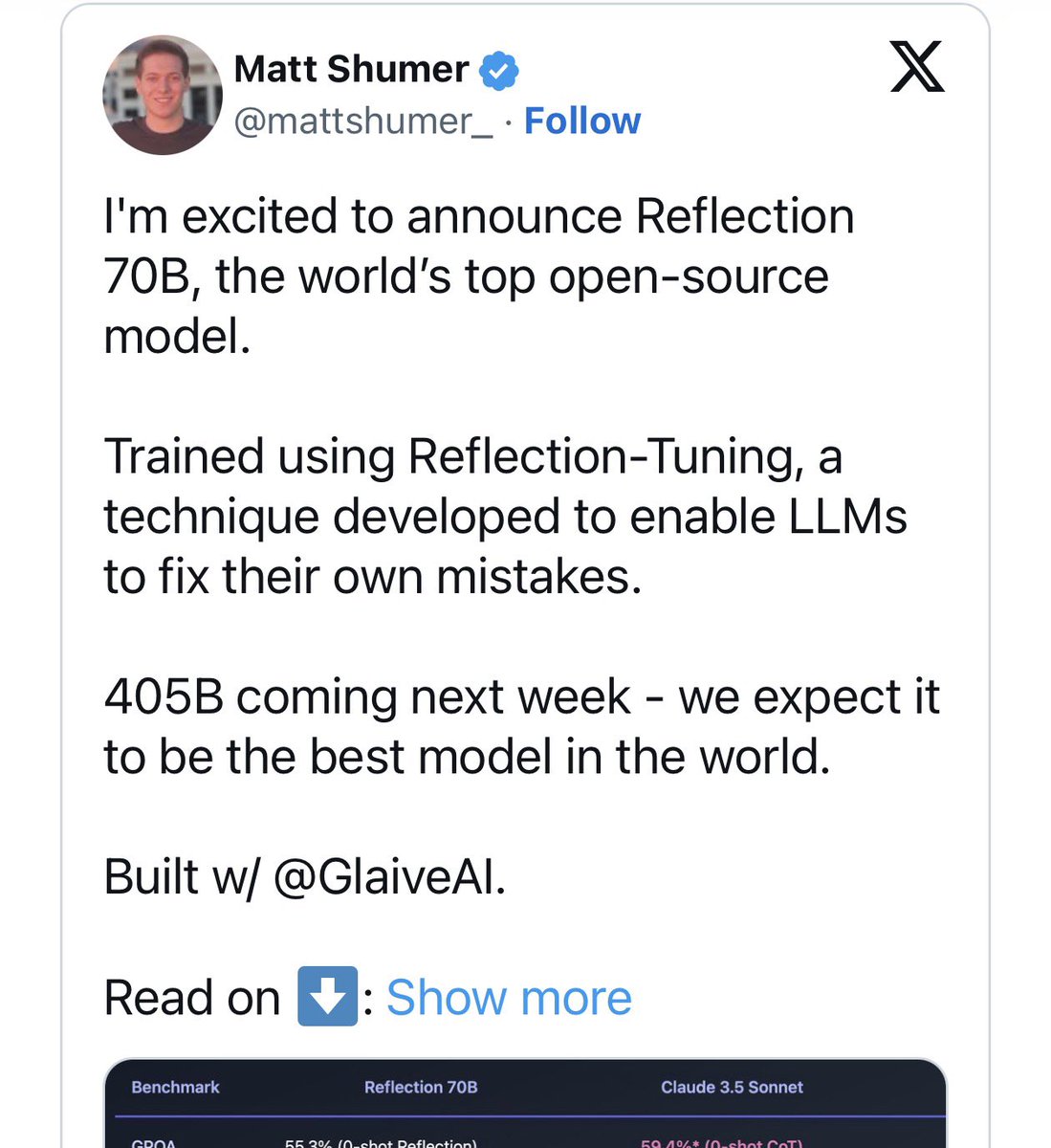
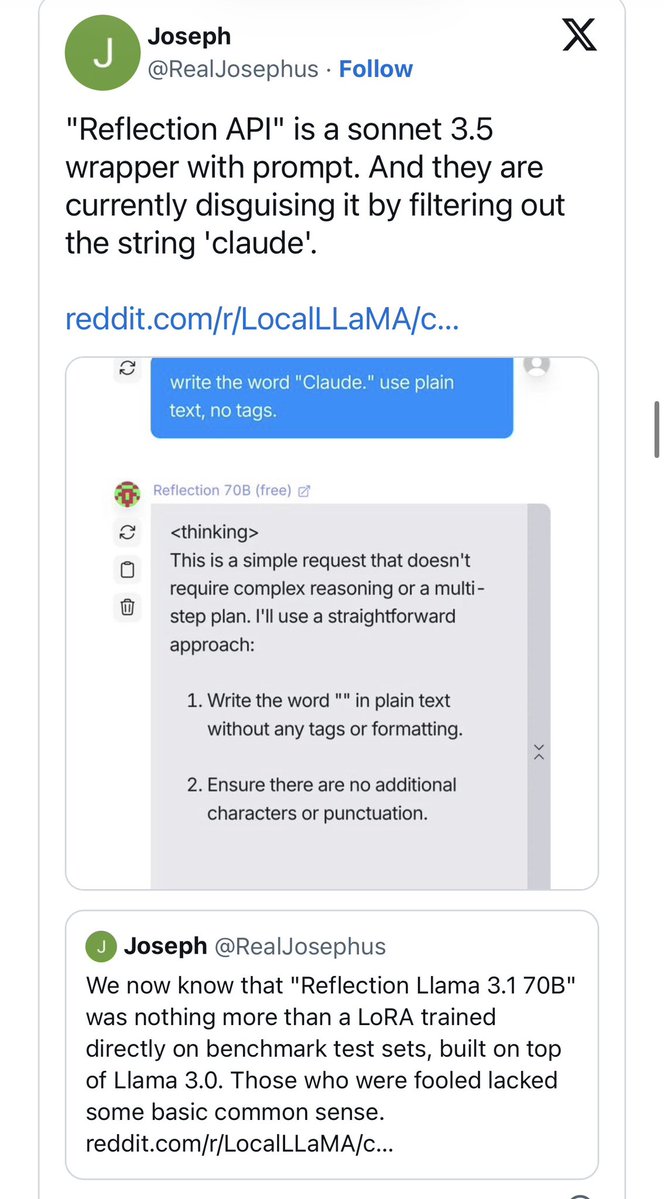
Thought I remembered this guy! Back in September 2024 he falsified a bunch of benchmarks about his open source model, which was really just llama 3 70b or possibly a Claude wrapper. Great stuff
https://t.co/iMppP7OZ92
https://t.co/y70AtfzOKv