Surprise 🤣
Anthropic really pissed somebody off in the U.S. government, probably after refusing to support autonomous weapons...
So now they had to give their competitors a bit more time to catch up 😉
@itsobinnasworld@theo I have the same, even without me doing any request from time to time I see message in Copilot CLI that it used 1 request.
I'm on $10 plan so maybe this is the reason. I regret I realize how good Copilot pricing is so late! I can't update to Pro+ to leverage it in May :(
Our virtual hackathon is back! Join us for a week of building with Opus 4.7 alongside developers from around the world.
The Claude Code team will be in the room all week, with a prize pool of $100K in API credits.
In 2023, we spent $3,934,099 on AWS + other hosting. In 2026, our hosting + support bill is down to ~$1m/year due to the cloud exit. Even including all the hardware buying, we will already have saved ~$4m by the end of this year. And going forward, it's ~$3m/yr in savings 🤑
This ad was created by one person in a single afternoon using @runwayml. Honestly, it’s already better than many professional productions that require way more time and resources.
Peter Steinberger, creator of OpenClaw: The real failure of agentic workflows comes when people remove themselves too early and expect quality without human taste in the loop.
Strong output needs vision + steering + the right questions.
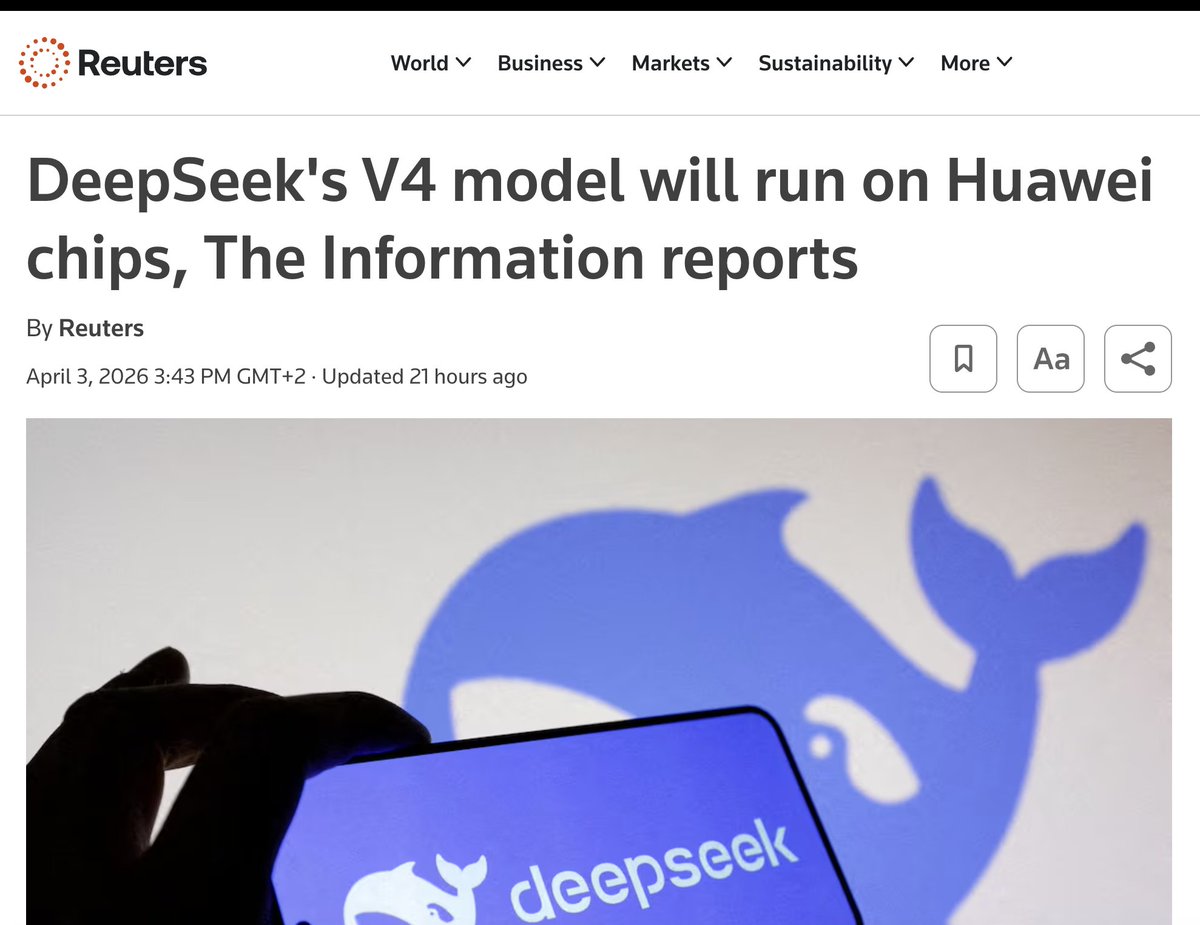
NVIDIA's moat for inference in scale was just crossed by Huawei Ascend 950PR running DeepSeek v4 on CANN Next (CUDA compatible).
But reportedly DSv4 was trained on Nvidia. They failed to train it on CANN. The planned 950DT chip may break the training moat too!
DeepSeek is about to release V4, and for the first time, a frontier Chinese AI model will run natively on Huawei silicon. A brief analysis and why its much bigger than most people think.
Alibaba, ByteDance, and Tencent have placed bulk orders for hundreds of thousands of Huawei's new Ascend 950PR chips. Prices have jumped 20% in weeks. And DeepSeek deliberately denied NVIDIA early access to V4 while giving that window exclusively to Chinese chipmakers. (via Reuters)
Let that satisfy for a moment: a Chinese AI lab actively chose to sideline NVIDIA.
What this means for NVIDIA
The immediate revenue hit is manageable. China was already a shrinking slice of NVIDIA's business after Washington's export controls and Beijing's counter-ban on the H20. But the *strategic* damage runs deeper. Every model optimized for Huawei chips is a model that no longer needs NVIDIA's ecosystem to function. That's not lost revenue but lost lock-in. NVIDIA's real moat was never just hardware performance. It was CUDA, the software layer that made switching costs prohibitively high.
Huawei built the Ascend 950PR to understand the same programming instructions as NVIDIA chips, dramatically lowering those switching costs. The moat is being drained from both sides!
What this means for China
Let's be precise about what China has and hasn't achieved. The Ascend 950PR delivers roughly 2.8x the compute of NVIDIA's H20, but it still trails the H200. Huawei won't match that tier until the Ascend 960 arrives in 2027. And production is constrained: SMIC can't match TSMC's output, domestic HBM is still ramping, and early Ascend 950PR batches will still rely on imported memory chips.
But here's what matters more than the spec sheet: China has closed the loop! It now has a domestic chip that can run a frontier model for inference at commercial scale, with a training chip (Ascend 950DT) due by Q4. Two years ago, that pipeline didn't exist.
Washington's export controls were designed to buy time, not to permanently cripple Chinese AI. The theory was that restricting access to cutting-edge chips and lithography tools would slow China by 3–5 years (ASML, highly recommend you read Chris Millers book "Chip War"). What actually happened: China compressed that timeline through *massive* state subsidies, mandatory domestic procurement, and engineering workarounds like DeepSeek's efficiency breakthroughs.
The competitive dynamic is shifting from "Can China do AI?" to "Can China do AI at scale on its own silicon?"! This week, that question got a lot closer to a yes.
The pressure on NVIDIA isn't that it loses China today. It's that China is building a parallel AI compute stack that doesn't need NVIDIA at all and every model trained or optimized for that stack pulls more of the ecosystem with it.
Thats why this is so big news.
I don't use autocomplete as much as I did 1-2 years ago, but still nice to have this upgrade in my favorite IDE.
@zeddotdev is so fast and smooth experience overall!
One more step closer to perfection :)
Zeta2 is here. 30% better acceptance rate than Zeta1. 200x more training data, LSP-powered context, faster predictions, open weights. Try it now in Zed.
We didn't just improve the model. We rebuilt the entire data pipeline behind it: https://t.co/FOresFJMNn
Software horror: litellm PyPI supply chain attack.
Simple `pip install litellm` was enough to exfiltrate SSH keys, AWS/GCP/Azure creds, Kubernetes configs, git credentials, env vars (all your API keys), shell history, crypto wallets, SSL private keys, CI/CD secrets, database passwords.
LiteLLM itself has 97 million downloads per month which is already terrible, but much worse, the contagion spreads to any project that depends on litellm. For example, if you did `pip install dspy` (which depended on litellm>=1.64.0), you'd also be pwnd. Same for any other large project that depended on litellm.
Afaict the poisoned version was up for only less than ~1 hour. The attack had a bug which led to its discovery - Callum McMahon was using an MCP plugin inside Cursor that pulled in litellm as a transitive dependency. When litellm 1.82.8 installed, their machine ran out of RAM and crashed. So if the attacker didn't vibe code this attack it could have been undetected for many days or weeks.
Supply chain attacks like this are basically the scariest thing imaginable in modern software. Every time you install any depedency you could be pulling in a poisoned package anywhere deep inside its entire depedency tree. This is especially risky with large projects that might have lots and lots of dependencies. The credentials that do get stolen in each attack can then be used to take over more accounts and compromise more packages.
Classical software engineering would have you believe that dependencies are good (we're building pyramids from bricks), but imo this has to be re-evaluated, and it's why I've been so growingly averse to them, preferring to use LLMs to "yoink" functionality when it's simple enough and possible.