200 yıllık biyoloji kitabı bir hafta sonunda öldü.
birisi oturmuş, hücreleri 3d gezdiğin bir app yapmış. video oyunu gibi. nöronu döndürüyorsun, aksonun içine giriyorsun, organeli tek tek ayıklıyorsun.
> arayüz: gpt image 2
> kod: gemini 3.5 flash
iki model. bir hafta sonu. matbaanın 1450'den beri yapamadığı şey.
birkaç yıla okullarda standart bu olacak. bizimkiler hala "tablet mi defter mi" tartışıyor.
oğlum çocuk hücreyi elinde çeviriyor artık. sen neredesin?
Yann LeCun closed $1.03B for AMI Labs on March 10. Three days later, this paper dropped from his NYU collaborators.
15M parameters. Single GPU. A few hours of training.
LeWorldModel is the first JEPA that trains end-to-end from raw pixels. Two loss terms: predict the next embedding, keep the latent space Gaussian. Previous JEPAs needed exponential moving averages or pretrained encoders to avoid representation collapse. LeWM doesn't.
Six hyperparameters down to one.
The numbers are the story. Foundation-model-based world models require hundreds of millions of parameters and serious compute to plan a control task. LeWM plans up to 48x faster while staying competitive on 2D and 3D benchmarks. The whole thing fits on a laptop GPU.
Look at the trajectory. Yann announced his Meta departure in November 2025 after 12 years and called founding FAIR his "proudest non-technical accomplishment." On March 10, 2026, AMI Labs closed the largest seed round in European history at a $3.5B pre-money valuation. Bezos, Nvidia, Samsung, and Toyota all wrote checks.
Three days later: a paper showing that JEPA-from-pixels is no longer fragile and no longer compute-heavy. The engineering scaffolding that made it look like an academic curiosity is gone.
The authors sit at Mila, NYU, Samsung SAIL, and Brown. None at Meta.
Yann's bet was that the path to machine intelligence runs through world models, not language models. He left a public company to build it. Each JEPA paper from his network resets the assumed cost structure for that bet. This one makes world modeling laptop-cheap.
Meta still has the GPUs. The architecture left.
FairLLaVA: Fairness-Aware Parameter-Efficient Fine-Tuning for Large Vision-Language Assistants
Mahesh Bhosale, Abdul Wasi, Shantam Srivastava, Shifa Latif, Tianyu Luan, Mingchen Gao, David Doermann, Xuan Gong
https://t.co/qCWSOZEwZ0 [𝚌𝚜.𝙲𝚅 𝚌𝚜.𝙰𝙸]
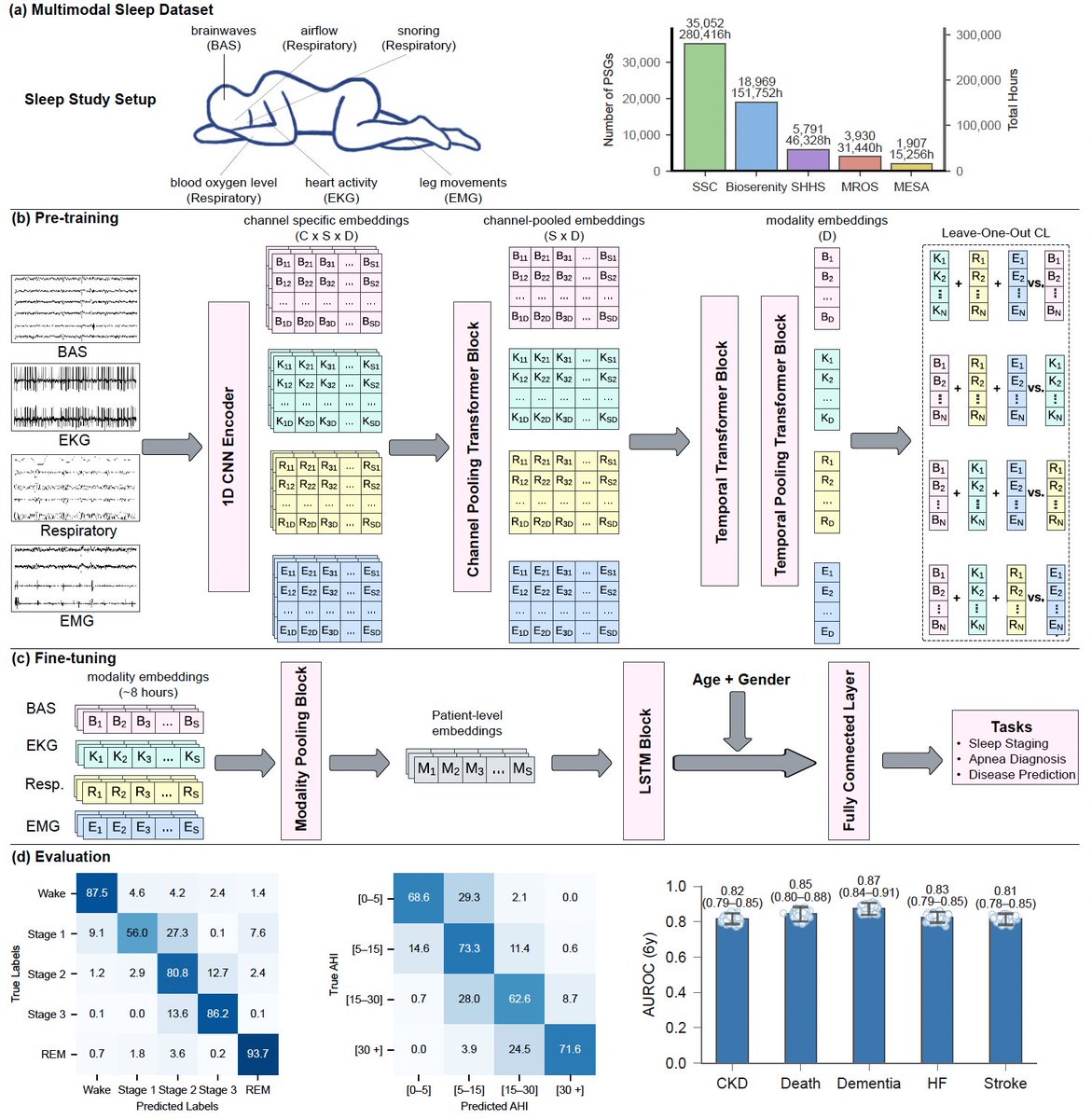
🚨BREAKING: Someone compiled every CS course from MIT, Stanford, Harvard, CMU and Berkeley in one place.
You can learn:
- Algorithms, OS, Distributed Systems, ML, AI
- Deep Learning, Computer Vision, NLP, LLMs
- Security, Databases, Quantum Computing
- 500+ courses with full video lectures
70.3K stars. 100% Opensource.
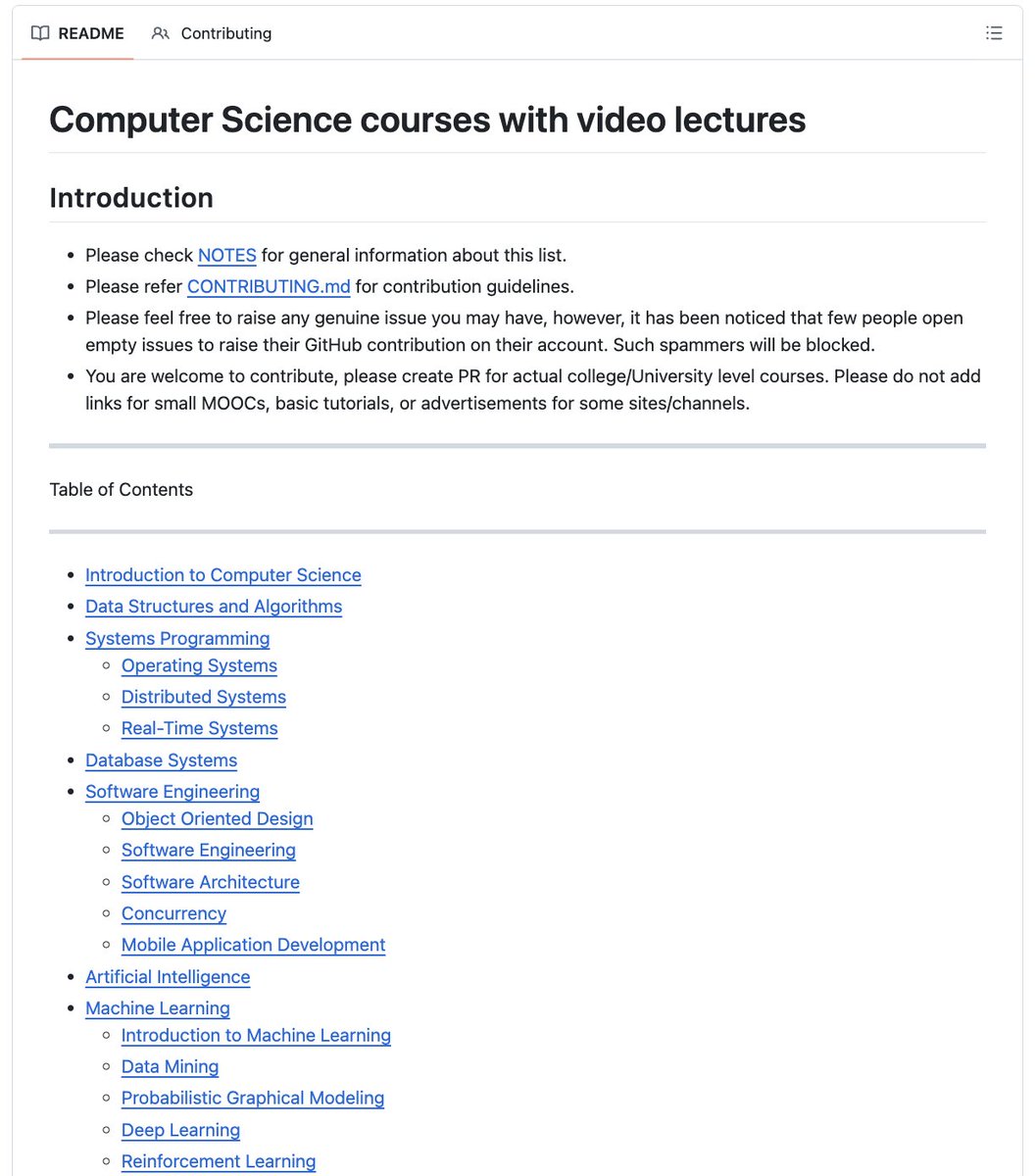
Today in @NatureMedicine we report that AI can predict 130 diseases from 1 night of sleep🛌
We trained a foundation model (#SleepFM) on 585K hours of sleep recordings from 65K people—brain, heart, muscle & breathing signals combined.
AI learns the language of sleep🧵
Interesting architectural alternative to the FFN network in transformers that mirrors the multi-headed design of the attention layer. The authors scale it further with a MoE design.
🔗https://t.co/df0AymiQ7b
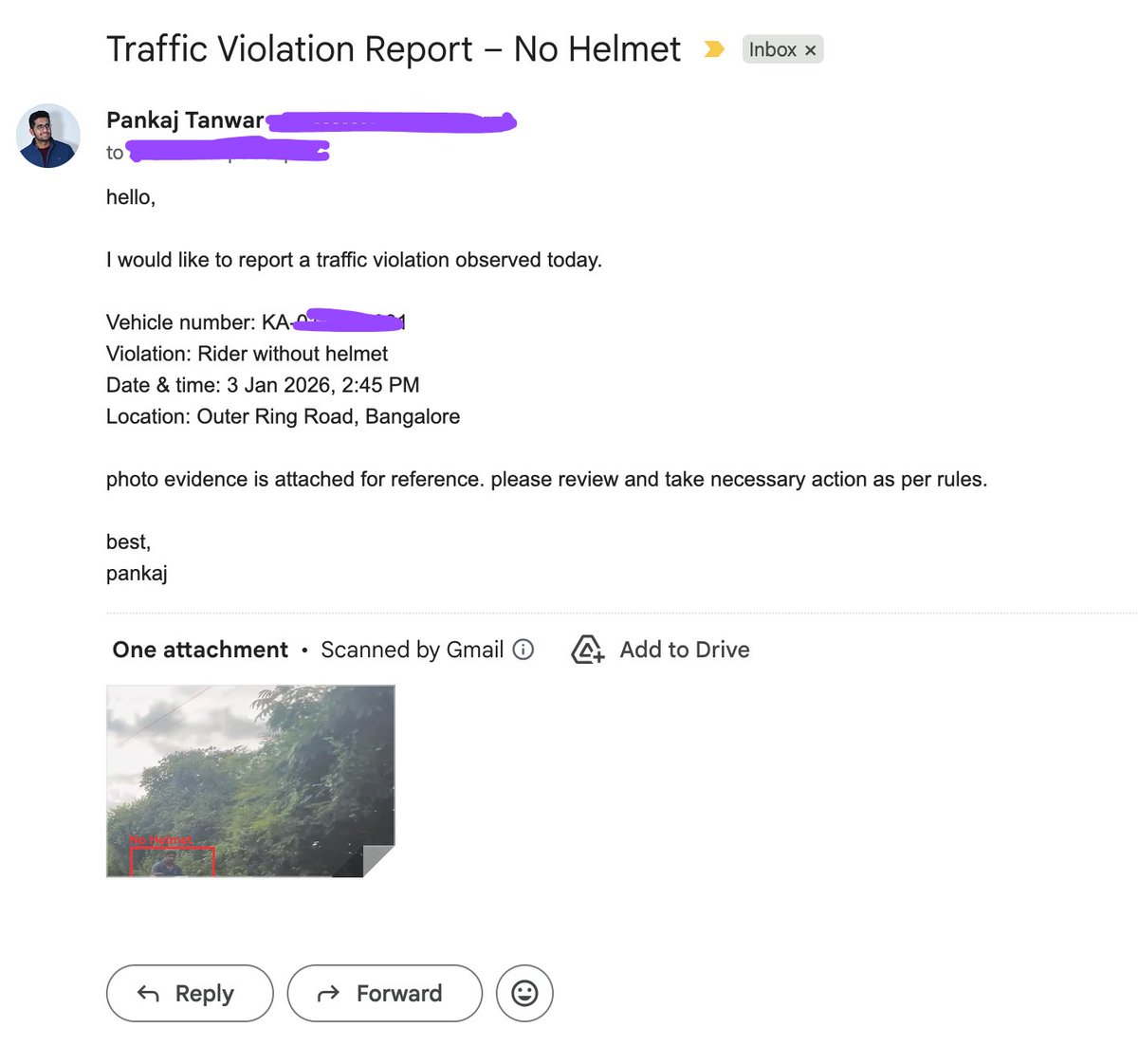
i was tired of stupid people on road so i hacked my helmet into a traffic police device 🚨
while i ride, ai agent runs in near real time, flags violations, and proof with location & no plate goes straight to police.
blr people - so now ride safe… or regret it.
Apple's new paper is mindblowing
They showed that one attention layer is enough to turn pretrained vision features into SoTA image generators!
This dramatically simplifies diffusion models while keeping the top-tier quality







































![CSVisionPapers's tweet photo. FairLLaVA: Fairness-Aware Parameter-Efficient Fine-Tuning for Large Vision-Language Assistants
Mahesh Bhosale, Abdul Wasi, Shantam Srivastava, Shifa Latif, Tianyu Luan, Mingchen Gao, David Doermann, Xuan Gong
https://t.co/qCWSOZEwZ0 [𝚌𝚜.𝙲𝚅 𝚌𝚜.𝙰𝙸] https://t.co/LD9t0Xn03A](https://pbs.twimg.com/media/HEq7xK9bEAE7Cfo.png)