one of the quotes i find most inspiring on a hard day:
"Whatever your hand finds to do, do it with all your might, for in the realm of the dead, where you are going, there is neither working nor planning nor knowledge nor wisdom"
Ecclesiastes 9:10
Useful tip to cut time-to-first-token on longer prompts in the API: pre-warm the prompt cache.
Send your system prompt before the user prompt. Claude writes it to the cache, but skips generating any output.
When the real user request lands, it'll hit a warm cache.
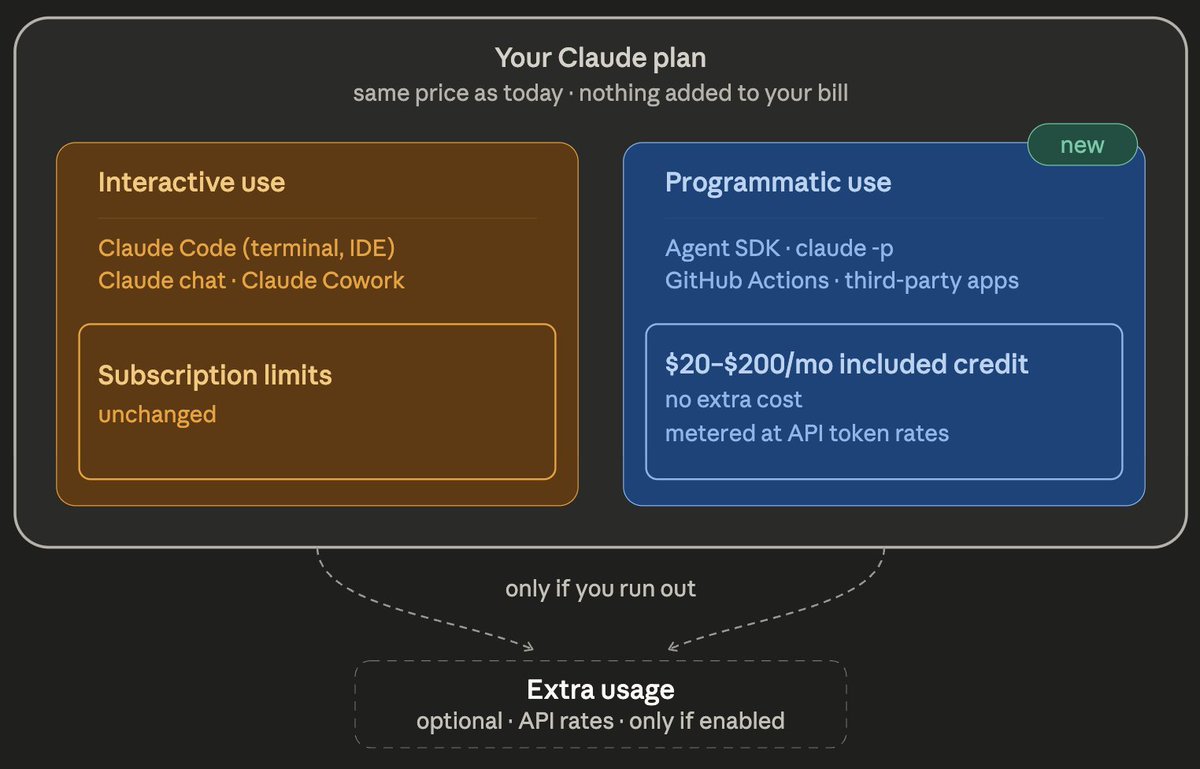
To add some clarity: you don't pay extra. It's the same subscription, same price per month.
What's new our sub now covers two separate pools:
· Interactive → sub limits, unchanged
· Programmatic → new $20–$200 included(!!) credit, metered at API rates
@bcherny Why do i feel the new /goal commands from @ClaudeDevs took inspiration from @karpathy autoresearch project as it looks kind of similar clear cut goals and it iterates till those are achieved or am i missing something #Claude
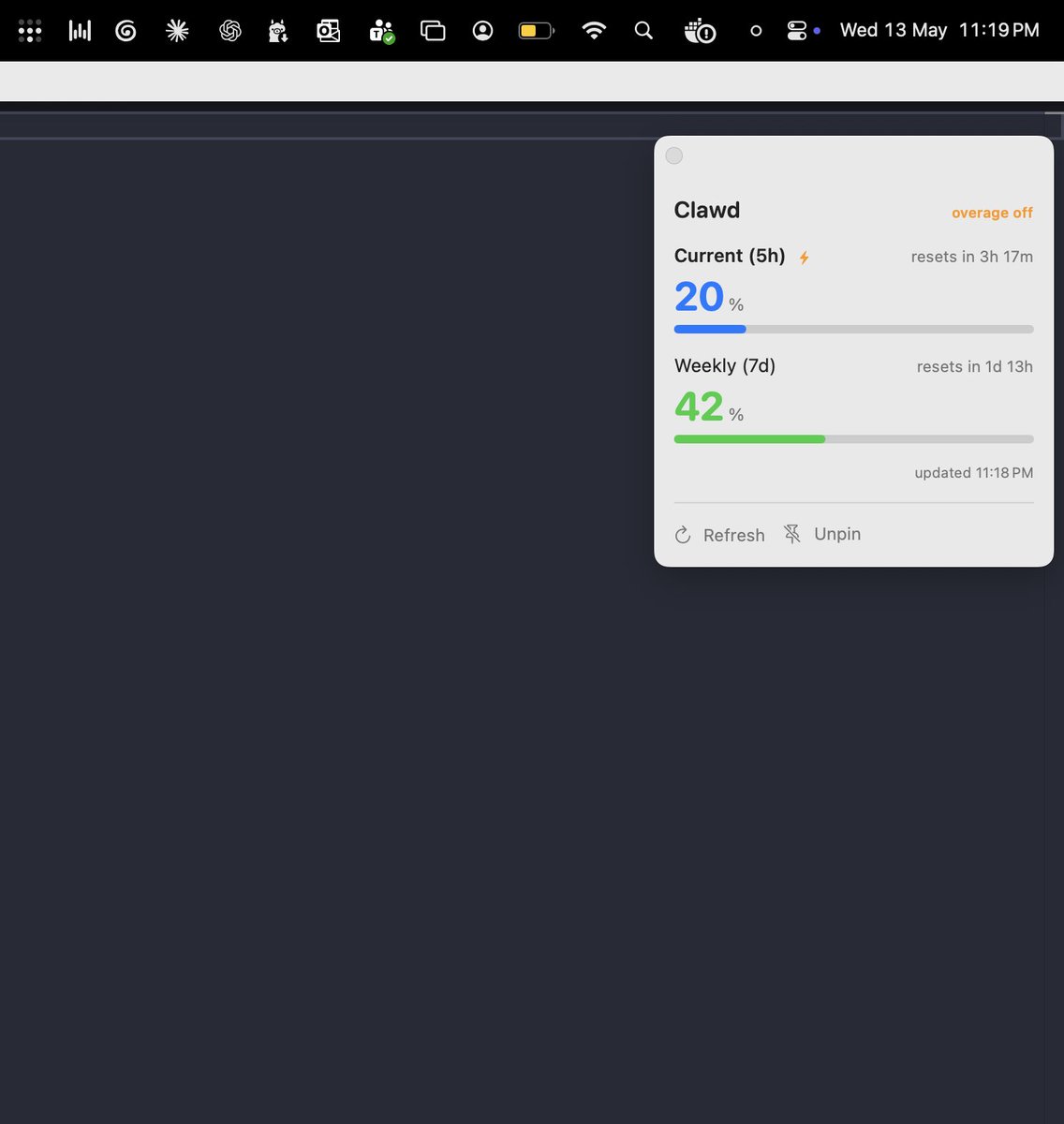
Claude has 5-hour + 7-day usage windows, but I had no visibility into unused quota while jumping between Outlook, Teams etc.
Inspired by Clawdmeter built Clawd: a Mac menubar app,floating pane, iPhone widget for Claude usage.
https://t.co/Ewwjoy6XRp
@ClaudeDevs@claudeai
People talk, listen, watch, think, and collaborate at the same time, in real time. We've designed an AI that works with people the same way.
We share our approach, early results, and a quick look at our model in action.
https://t.co/AFJZ5kH7Ku
🚨 UPDATE: Mini Shai-Hulud has crossed from @npmjs into @pypi and is still spreading.
Newly confirmed compromised artifacts:
@opensearch-project/opensearch: 3.5.3, 3.6.2, 3.7.0, 3.8.0 (1.3M weekly downloads)
mistralai: 2.4.6 on PyPI
guardrails-ai: 0.10.1 on PyPI
additional @squawk/* packages on npm
guardrails-ai 0.10.1 executes malicious code on import. On Linux, it downloads git-tanstack[.]com/transformers.pyz, writes it to /tmp/transformers.pyz, and runs it with python3 without integrity verification.
The git-tanstack.com domain displayed a message signed “With Love TeamPCP,” along with: “We've been online over 2 hours now stealing creds
Regardless I just came to say hello :^)”
The page also linked to a YouTube video and you can probably guess which one.
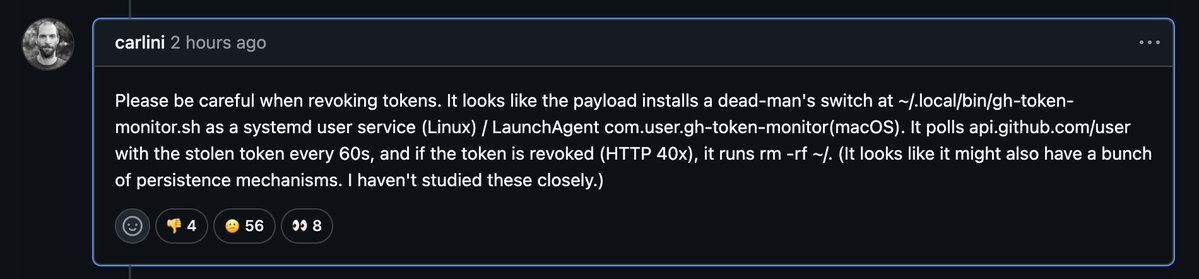
‼️🚨 BREAKING: A new npm supply-chain attack uses a dead-man's switch. The payload plants a watcher on your machine that nukes your home directory the second you revoke the GitHub token it stole from you.
The compromise happened today, across 42 official tanstack npm packages, 84 malicious versions in total. tanstack/react-router alone pulls more than 12 million weekly downloads.
The attacker forked TanStack's repository and pushed a single hidden commit. From there, they tricked TanStack's own release system into signing the malicious packages as if they were the real thing. To npm, and to anyone checking the cryptographic proof of origin (SLSA provenance), the poisoned versions looked 100% legitimate.
Maintainer Tanner Linsley confirmed the whole team had 2FA enabled. It didn't matter. This is the first documented npm worm in history that ships with a valid, signed certificate of authenticity, the same one defenders rely on to know a package wasn't tampered with.
We’re excited to share that Unsloth has joined the PyTorch Ecosystem!
Unsloth is an open-source project that makes training & running models faster, more accurate with less compute. We want AI to be accessible to all
Blog: https://t.co/viXIukVHnU
GitHub: https://t.co/aZWYAtakBP
@cjzafir I somehow belive SLM's will be the one which will be ruling the world and kind of advancement we are seeing it might happen the smaller it is better it is not the other way around which is right now.
@cjzafir Perfect.. That is what infact I did .. Used unsloth , collab to fine tune infact ended up fully fine tuning 2.5 - 3b one and worked like a charm. But den i had to take it step futher with a more power ful gpu so hav to move to runpod.. But yes big fan of SLM's with vertical depth
I read the #book Principles of Neural Design recently.
It’s extremely dense, which you’d hate or love depending on how much you’re in awe with how our brain works. I totally loved it! The book is unique in trying to explain the wondrous complexity of brain using few unifying principles, all of which can be traced to constraints evolution faces, especially with energy efficiency.
The central insight from the book is this:
👉 Brains maximize information (bits) per ATP
Consuming energy and producing ATP is hard. The organism has to work to get energy. During evolution, inefficient designs get outcompeted by efficient designs so we should expect to see efficient designs. For brain, this means squeezing max information and computing using least amount of energy.
From this insight, we could derive the following principles:
1. Send only what’s surprising. Why waste energy in sending what can be predicted/estimated efficiently. This explains why predictive coding makes sense for the brain.
2. Minimize wire / compute locally. Since wiring is expensive and sending signals across length requires energy, brain does as much computation locally as possible (and sends only sparse computed results/commands at greater lengths). This explains why brain has “regions” (such as for language) since local computation minimizes wire.
3. Send information at the lowest acceptable spike rate. Because faster spike rate requires thicker axons and more ATP, brain sends sparse, low-mean firing rate signals. The lower bound to how slow signals you can send is determined by requirements for fast reaction (this is why we do get few fat axons from the eye into the brain, but most axons or then). It also explains how brain simply sends a simple sparse signal to local pattern generators near legs than then send precise signals to leg muscle for movement. Similarly, retina/eye does a lot of local computation and sends summaries only to the brain. There are two kinds of sparsity: lifetime sparsity (how often each neuron fires, across stimuli - averages to be 1Hz in V1) and population sparsity (how often each stimulus activates neurons - averages to be few percentage at a time in V1)
4. Firing codes match the distribution of natural data. Spike rates encode equal probability bins of natural data (often log scale), as that’s most optimal (maximizes Shannon entropy; it’s crazy how nature discovers mathematically elegant solutions way before humans did. Another example of it is how our inner-ear cells do Fourier decomposition of incoming waves)
5. Do analogue and chemical computation (wherever you can): much cheaper than digital spikes as they cost a lot more energy (but digital spikes can communicate far, so they have to be used). This means a lot of computation happens within dendrites. Some researchers believe because dendrites are so complex, each biological neuron is better approximated by a full multi-layer perceptron.
6. Make components irreducibly small: shrink to save materials/energy as much as physics allows (after a point, noise dominates, so you can’t shrink them lower)
7. Complicate to optimize: retina alone has 100 types of cells, specialist cells allow both efficient computation (because of their morphology) but also sparse, low-rate communication (when it spikes, downstream knows who sent the signal). A generalist neuron must use higher spike rate and downstream neurons must wait longer to integrate. This principle was most surprising to me because as an engineer, I’ve been feed simplify and generalize as principles throughout my life. But nature likes to complicate things.
8. Adapt, learn, forget: firing rate gets continuously re-adjusted (e.g. when you move to brighter room or a loud concert), without this, brain would be far more inefficient.
We are back. After one year of quiet building.
Introducing GENE-26.5, our first robotic brain that takes a major step toward human-level capability.
For years, robotics has struggled to learn from the world’s largest and valuable data source: Humans.
Solving it means rethinking the whole stack from the ground up:
- A robotics-native foundation model.
- A 1:1 human-like robotic hand.
- A noninvasive data collection glove for motion, force, and touch.
- A simulator that turns weeks of experiments into minutes.
GENE-26.5 is trained across language, vision, proprioception, tactile, and action. We designed a set of tasks to test how far we can go with this new paradigm.
Fully autonomous, 1x speed, one model, same weights. (Enjoy with sound on)
We are approaching the endgame for robotics.
And this is just a beginning.

































![SocketSecurity's tweet photo. 🚨 UPDATE: Mini Shai-Hulud has crossed from @npmjs into @pypi and is still spreading.
Newly confirmed compromised artifacts:
@opensearch-project/opensearch: 3.5.3, 3.6.2, 3.7.0, 3.8.0 (1.3M weekly downloads)
mistralai: 2.4.6 on PyPI
guardrails-ai: 0.10.1 on PyPI
additional @squawk/* packages on npm
guardrails-ai 0.10.1 executes malicious code on import. On Linux, it downloads git-tanstack[.]com/transformers.pyz, writes it to /tmp/transformers.pyz, and runs it with python3 without integrity verification.
The git-tanstack.com domain displayed a message signed “With Love TeamPCP,” along with: “We've been online over 2 hours now stealing creds
Regardless I just came to say hello :^)”
The page also linked to a YouTube video and you can probably guess which one.](https://pbs.twimg.com/media/HIFxSRYXgAA6u3V.jpg)