Superintelligence isn't about discovering new things; it's about discovering new ways to discover
I think our latest work formalizes Meta Chain-of-Thought which we believe lies on the path to ASI
When we train models on the problem-solving process itself—rather than the final solution—they internalize how to think about reasoning tasks, not just what to think
The next wave of AI is a Meta-CoT loop. We can't predict what novel forms of thinking might emerge, but it points to an extraordinary synthetic future
I'm so proud of @synth_labs team & our incredible open science collaborators for getting this work out
We have a new position paper on "inference time compute" and what we have been working on in the last few months! We present some theory on why it is necessary, how does it work, why we need it and what does it mean for "super" intelligence.
Qwen+RL = dramatic, Aha!
Llama+RL = quick plateau
Same size. Same RL. Why?
Qwen naturally exhibits cognitive behaviors that Llama doesn't
Prime Llama with 4 synthetic reasoning patterns & it matched Qwen's self-improvement performance!
We can engineer this into any model! 👇
🚨🚨New Paper: Training LLMs to Discover Abstractions for Solving Reasoning Problems
Introducing RLAD, a two-player RL framework for LLMs to discover 'reasoning abstractions'—natural language hints that encode procedural knowledge for structured exploration in reasoning.🧵⬇️
much more convinced after getting my own results:
LoRA with rank=1 learns (and generalizes) as well as full-tuning while saving 43% vRAM usage! allows me to RL bigger models with limited resources😆
script: https://t.co/p6IIiBQA6c
I’ll take the opposite view - current methods are saturating and we need at least 1 practical breakthrough and at least two fundamental ones (which will likely take years) just off the top of my head to reach AGI. None of these are oversight or safety related.
NEW: Is the internet changing our personalities for the worse?
Conscientiousness and extroversion are down, neuroticism up, with young adults leading the charge.
This is a really consequential shift, and there’s a lot going on here, so let’s get into the weeds 🧵
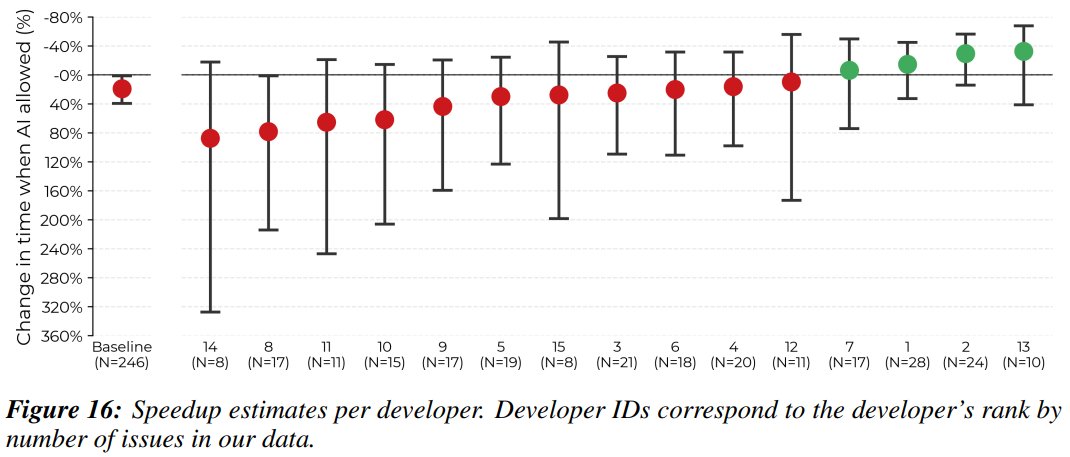
I was one of the 16 devs in this study. I wanted to speak on my opinions about the causes and mitigation strategies for dev slowdown.
I'll say as a "why listen to you?" hook that I experienced a -38% AI-speedup on my assigned issues. I think transparency helps the community.
I’m not big on identities, but I am extremely proud to be American. This is true every day, but especially today—I firmly believe this is the greatest country ever on Earth. The American miracle stands alone in world history.
I believe in techno-capitalism. We should encourage people to make tons of money and then also find ways to widely distribute wealth and share the compounding magic of capitalism. One doesn’t work without the other; you cannot raise the floor and not also raise the ceiling for very long.
The world should get richer every year through science and technology, but everyone has to be in the “up elevator”. I think the government usually does a worse job than markets, and so we need to encourage our culture of innovation and entrepreneurship. I also believe that education is critically important to keeping the American edge.
I believed this when I was 20, when I was 30, and now I am 40 and still believe it. The Democratic party seemed reasonably aligned with it when I was 20, losing the plot when I was 30, and completely to have moved somewhere else at this point. So now I am politically homeless. But that’s fine; I care much, much more about being American than any political party.
I’d rather hear from candidates about how they are going to make everyone have the stuff billionaires have instead of how they are going to eliminate billionaires.
The American experiment has always been messy. I am hopeful for another great 250 years. Happy 4th!
Xiaomi got 200,000 orders in 3 minutes for the YU7 and I’m not even surprised.
The value proposition is just nuts.
I’m kinda of bummed because it means a few more years of having to satisfy demand from China before global expansions.
What if models could learn which problems _deserve_ deep thinking?
No labels. Just let the model discover difficulty through its own performance during training.
Instead of burning compute 🔥💸 on trivial problems, it allocates 5x more on problems that actually need it ↓
Our new method (ALP) monitors solve rates across RL rollouts and applies inverse difficulty penalties during RL training.
Result? Models learn an implicit difficulty estimator—allocating 5x more tokens to hard vs easy problems, cutting overall usage by 50%
🧵👇1/10
@yacineMTB lmfao
wish x had a trends dashboard of 📈📉 ‘user`s posts as ‘seen_by_my_timeline’ over ‘365 | …’
sometimes catches me off guard who silently crashes out