Traditional cron jobs are great for silent tasks on a machine, and Hermes Agent cronjobs are great for extending that to your agent, but why not utilize the gateway and hermes' cron to access things that don't need to cost an agent's time across any messenger service you have connected?
Just `hermes update` and ask your agent to setup cronjobs that need no agent in the loop, like running a systems diagnostic script that reports info to you every 12 hours, pulls in an RSS feed, and send it over to you on telegram, whatever you can think of, while saving a lot of money on purely programmatic tasks!
If the script has no output, you wont get a ping either
PR: https://t.co/VumGUiLTnQ
📣 What if every open issue had a Codex agent?
That’s the idea behind Symphony, an open-source agent orchestrator for Codex that turns task trackers into always-on systems for agentic work, letting humans focus on review and direction.
After spending a day using Hermes Agent, I have to say it's solid. The flaky things in OpenClaw are gone, it's just more robust and reliable.
So interesting how with the same LLM (gpt5.4), the harness can make or break the experience, nice work @NousResearch
I've been using OpenClaw but it's gotten pretty bloated.
This weekend I started with @NousResearch's Hermes Agent, way lighter but still early days.
Inspired by a ClawhHub skill that helps agents understand OpenClaw, I built one for Hermes.
https://t.co/VZLBeLlJYj
Turns out @TfL's Bakerloo, Victoria and Northern lines do actually sound different once you pay attention, so I made a quiz with real recordings from each line. 10 questions, takes about 2 minutes, and I still only got 6/10. https://t.co/56p0o0ZDC9
Introducing Unsloth Studio ✨
A new open-source web UI to train and run LLMs.
• Run models locally on Mac, Windows, Linux
• Train 500+ models 2x faster with 70% less VRAM
• Supports GGUF, vision, audio, embedding models
• Auto-create datasets from PDF, CSV, DOCX
• Self-healing tool calling and code execution
• Compare models side by side + export to GGUF
GitHub: https://t.co/2kXqhhvLsb
Blog and Guide: https://t.co/ENuTWal5AA
Available now on Hugging Face, NVIDIA, Docker and Colab.
. @PostHog is one of my favourite analytics tools.
Their MCP is great but @openclaw doesn't support MCP natively, so I built a CLI + an agent skill that wraps the full API for any AI agent
https://t.co/3pLzjmY4BN
https://t.co/e9inJ5XhTl
I wanted one place to see where I stand financially. So I built Ledgi, a net worth tracker shaped around UK stuff.
There's a CLI and a @claudeai skill, so you can ask things like "what's my net worth?" and it'll actually go look.
https://t.co/A3veX3LWsn
https://t.co/sPYP7Hwowv
Very interested in what the coming era of highly bespoke software might look like.
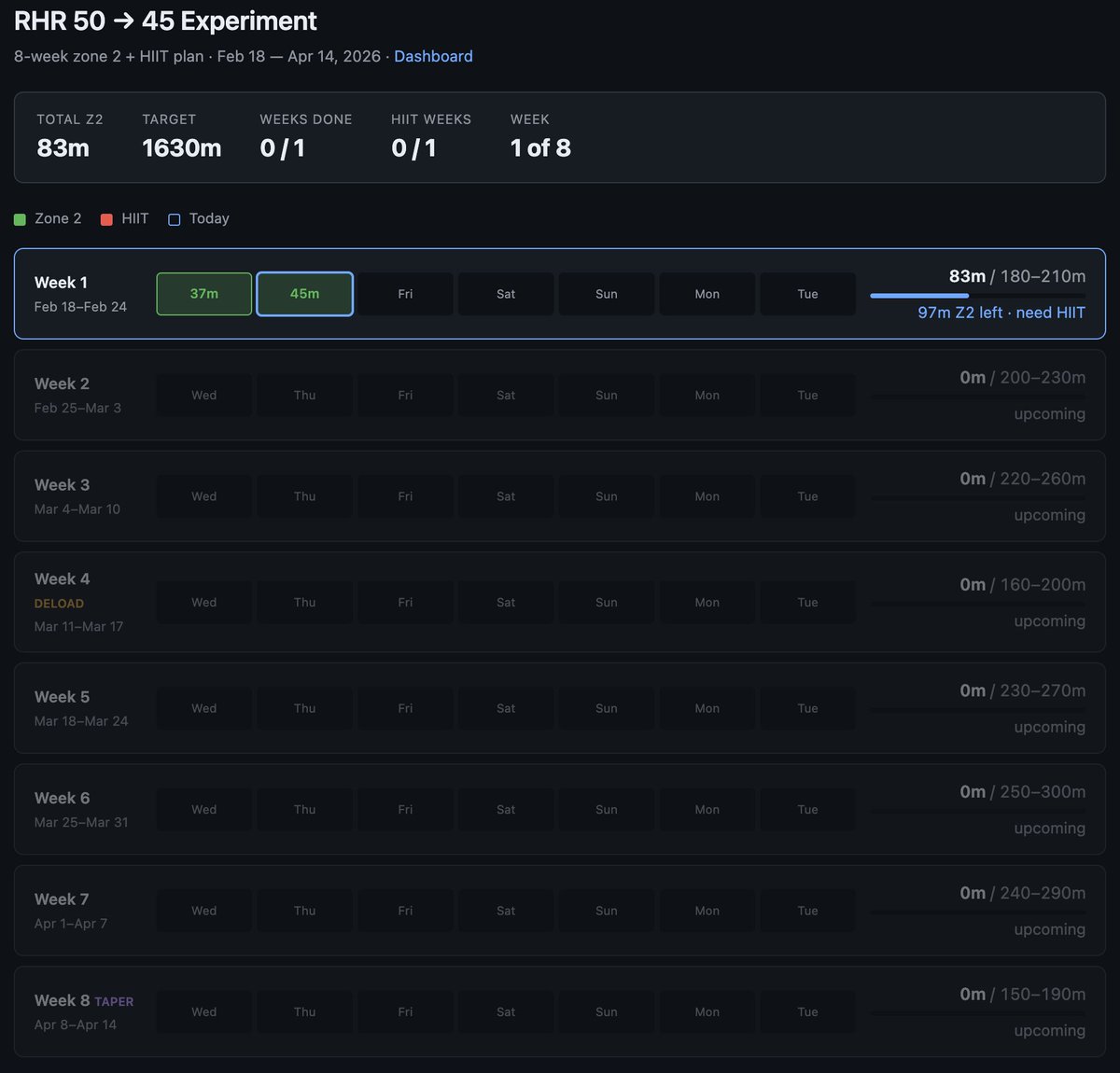
Example from this morning - I've become a bit loosy goosy with my cardio recently so I decided to do a more srs, regimented experiment to try to lower my Resting Heart Rate from 50 -> 45, over experiment duration of 8 weeks. The primary way to do this is to aspire to a certain sum total minute goals in Zone 2 cardio and 1 HIIT/week.
1 hour later I vibe coded this super custom dashboard for this very specific experiment that shows me how I'm tracking. Claude had to reverse engineer the Woodway treadmill cloud API to pull raw data, process, filter, debug it and create a web UI frontend to track the experiment. It wasn't a fully smooth experience and I had to notice and ask to fix bugs e.g. it screwed up metric vs. imperial system units and it screwed up on the calendar matching up days to dates etc.
But I still feel like the overall direction is clear:
1) There will never be (and shouldn't be) a specific app on the app store for this kind of thing. I shouldn't have to look for, download and use some kind of a "Cardio experiment tracker", when this thing is ~300 lines of code that an LLM agent will give you in seconds. The idea of an "app store" of a long tail of discrete set of apps you choose from feels somehow wrong and outdated when LLM agents can improvise the app on the spot and just for you.
2) Second, the industry has to reconfigure into a set of services of sensors and actuators with agent native ergonomics. My Woodway treadmill is a sensor - it turns physical state into digital knowledge. It shouldn't maintain some human-readable frontend and my LLM agent shouldn't have to reverse engineer it, it should be an API/CLI easily usable by my agent. I'm a little bit disappointed (and my timelines are correspondingly slower) with how slowly this progression is happening in the industry overall. 99% of products/services still don't have an AI-native CLI yet. 99% of products/services maintain .html/.css docs like I won't immediately look for how to copy paste the whole thing to my agent to get something done. They give you a list of instructions on a webpage to open this or that url and click here or there to do a thing. In 2026. What am I a computer? You do it. Or have my agent do it.
So anyway today I am impressed that this random thing took 1 hour (it would have been ~10 hours 2 years ago). But what excites me more is thinking through how this really should have been 1 minute tops. What has to be in place so that it would be 1 minute? So that I could simply say "Hi can you help me track my cardio over the next 8 weeks", and after a very brief Q&A the app would be up. The AI would already have a lot personal context, it would gather the extra needed data, it would reference and search related skill libraries, and maintain all my little apps/automations.
TLDR the "app store" of a set of discrete apps that you choose from is an increasingly outdated concept all by itself. The future are services of AI-native sensors & actuators orchestrated via LLM glue into highly custom, ephemeral apps. It's just not here yet.
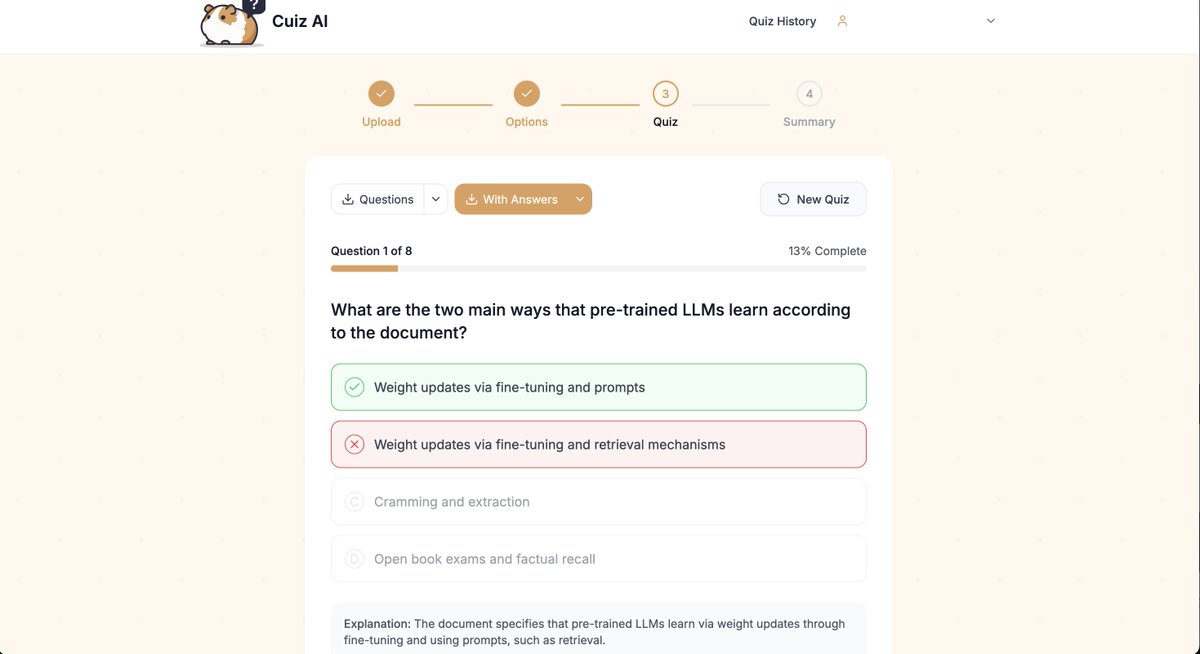
🔍 Ever wonder how we transform documents into smart quizzes?
👨💻 Coming soon: an inside look at our tech stack, the AI magic behind Cuiz AI, and lessons from our dev journey.
Stay tuned! @FastAPI@openrouter@Firebase@nextjs
Launching Cuiz AI!! – an AI-powered platform that transforms any document, text, or URL into interactive quizzes instantly!
Perfect for students, educators, and anyone looking to make learning more engaging.
Try it now at https://t.co/qxuY07A7Ia #EdTech#Quizzes#AItools
When searching for similar tracks, do we just compare every single track to every other track, one by one? Nope! We use 🪐 Voyager, our new open source library for nearest neighbor search. Listen here: https://t.co/kfMQjsVczP
#opensource#machinelearning#ML#LLMs
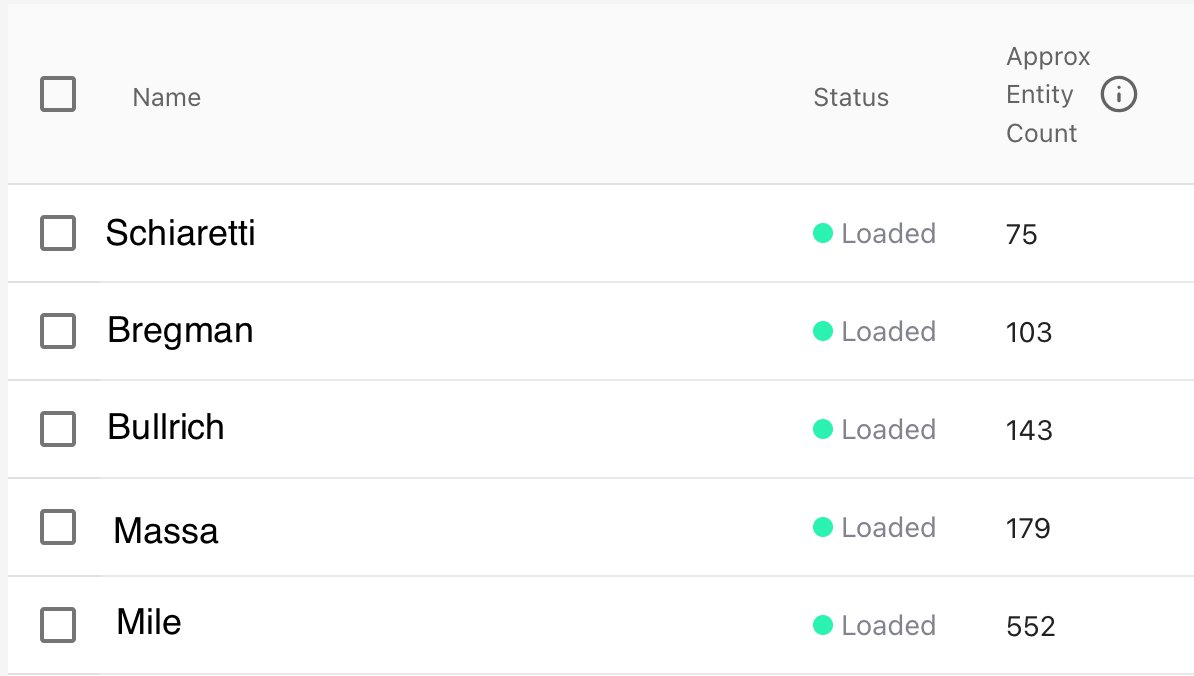
@langchain@milvusio https://t.co/VJm6vSVaCD : aca todos los scripts de retrieval de las +2000 entrevistas en YT, baja los videos, transcribe con WhisperX, identifica speakers, y de-duplicación usando FAISS, todo explicado paso a paso!
Esto proyecto lo hicimos con @nicolasmetallo
y @NoninoJulian !
Les presento https://t.co/W7BNlqsd3Z
Con la ayuda de @langchain, #gpt4 y @milvusio, podemos preguntar a los candidatos presidenciales lo que realmente nos importa... basado en más de 2000 entrevistas! Un toque de tecnología en la política! (repos en 🧵) #Elecciones2023
@langchain@milvusio https://t.co/4xbhZbWGQ0 : en @FastAPI, también contiene el script de ingestion de transcripciones. Este script realiza embeddings de las transcripciones, y las guarda en la base de datos vectorial Milvus
El frontend está hecho en NextJS, no esta open porque es muy basico!
Mas detalles? Aca https://t.co/eMzie08bTp explicamos con @nicolasmetallo y @NoninoJulian cómo se hizo la app. Nuestro próximo proyecto? https://t.co/SlOhLbarxp Nadie resiste el archivo! Querés acordarte qué dijo o propuso cada candidato presidencial? Muy pronto @rebord#rebordGPT
Buenas! Con @nicolasmetallo y @mentasok nos propusimos transcribir los episodios del Metodo @tomasrebord.
Con @langchain y #gpt4 hicimos una app donde se puede preguntar y obtener respuestas basadas en las conversaciones del show. Repo en github: https://t.co/pxSlYo2UGB