I wanted a way to see what my Claude Code sessions actually look like over time, and how to build TUIs.
so I built cicada.
It's a TUI that reads your local session data and gives you basic analysis, token usage, project analytics, tool breakdowns, streaks, and full chat replay right in the terminal.
brew install base-14/tap/cicada
https://t.co/S8G5DKoxyt
When we started base14, all we wanted to build was products that our customers love and use every day. A lot has changed since, but this hasn't. This month I've been meeting customers for casual feedback, and I'm more convinced that we're on the right path. A few things I heard:
- "With base14, the most significant change has been [that] my whole team is now involved and more customer-obsessed"
- "Before working with you, our monitoring setup was all over the place, and very costly. You guys brought our [o11y] costs down by 80%, and now I'm seeing compounding value..."
- "We were afraid of upgrading our systems. My team got confidence not just from the product, but from the support and guidance. You supplemented us with technology expertise we didn't have at the time"
Back to building. As a small team, we needed to hear this more than we realised.
I wanted visibility into what was actually happening under the hood, so I set up a monitoring dashboard using Claude Code's built-in OpenTelemetry support.
It's pretty straightforward — set CLAUDE_CODE_ENABLE_TELEMETRY=1, point it at a collector, and you get metrics on cost, tokens, tool usage, sessions, and lines of code modified. https://t.co/93WU9FdYtG
A few things I found interesting after running this for about a week:
Cache reads are doing most of the work. The token usage breakdown shows cache read tokens absolutely shadowing everything else. Prompt caching is doing a lot of heavy lifting to keep costs reasonable.
Haiku gets called way more than you'd expect. Even on a Pro plan where I'd naively assumed everything runs on the flagship model, the model split shows Haiku handling over half the API requests. Claude Code is routing sub-agent tasks (tool calls, file reads, etc.) to the cheaper model automatically.
Usage patterns vary a lot across individuals. Instrumented claude code for 5 people in my team , and the per-session and per-user breakdowns are all over the place. Different tool preferences, different cost profiles, different time-of-day patterns.
(this is data collected over the last 7 days, engineers had the ability to switch off telemetry from time to time. we are all on the max plan so cost is added just for analysis)
Designing the next generation of observability tools. There are 5 medium term predictions we will be testing -
- slow death of interfaces - Slowly but surely, proprietary interfaces are vanishing. Your AI chat is the interface for everything. Let's call your chat interface Bob, your 24x7 helper. Want to book a meal, ask Bob. For engineers, IDEs like Intellij Idea - one of the best - are slowly giving way to a CLI interface with Bob Code. Fix downtime? Ask Bob. Over time, complex workflows will get delegated. Very few dashboards (if at all) will reach your eyes.
- consolidation of tools - While Bob provides a single interface over 100s of services, the cost of doing so increases as the number grows. Anyone with 2 or more observability tools will soon feel the pinch when the agents start consuming 3-4 times more tokens to make sense of things. More importantly, the more databases your agents need to look at, the slower their response will be. Moving to a single unified telemetry platform will be a competitive advantage.
- Cambrian explosion of smaller custom systems - The amount of custom software put to production is increasing dramatically. Agents are good at building and managing smaller systems. Custom Software will grow 2-5x YoY for the next 5 years. Barrier to entry is very low. As the cost of building custom systems comes down, the cost of operating custom systems will be the next challenge. Observability plays a pivotal role here, and the cost of observability has to come down for all this to make sense.
- focused low-cost agents - For a personal assistant, typically the models would be need to be generally more capable. But smaller systems with singular tasks do not need heavy models. Costly Bob type Agents are already good at managing other cheaper agents with singular tasks. Such agents will need more scaffolding and guardrails. Evals will be decisive, and any observability platform must provide the ability to inform agents and engineers about divergences.
- agents treat observability data providers as infrastructure - observability data provides a vital feedback loop. As monitoring moves to agents, the long cycle from that data to SDLC that takes months - add to a backlog, prioritise, build, test, deploy - should be done in minutes with seemingly infinite capacity at hand. As the cycle shortens, agents will need observability system of record as much as they need models and hardware.
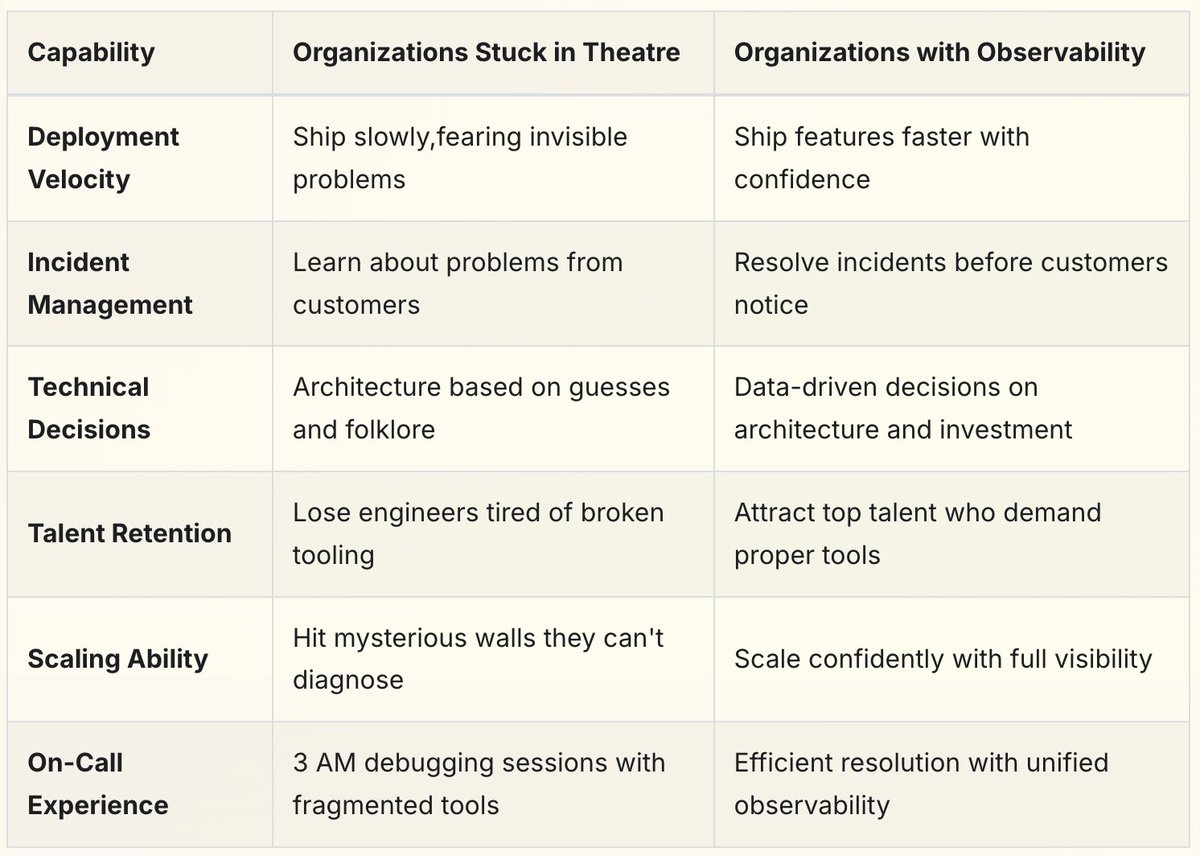
Your organization has invested millions in observability tools. You have dashboards for everything. Your teams dutifully instrument their services. Yet when incidents strike, engineers still spend hours hunting through disparate systems, correlating timestamps manually
We just shipped pgX - unified PostgreSQL observability that lives alongside your app and infra monitoring.
No more jumping between dashboards during incidents.
Introducing pgX - get 500+ timeseries high res postgres o11y data right next to your application and infra o11y.
slowAPI -> slow Query -> connection issues, locks, indexes, cluster and delays, vacuums - without any tool hops.
https://t.co/r7EktuJBOS
Thought of a future where production infrastructure self-heals? And agents autonomously detect and resolve incidents before they impact users? Join our founding team to define the next era of infrastructure automation.
Please DM or apply at https://t.co/7UasyCjYqa
Look, in a few months/years, production issues will be solved by agents. At @base14io, we are building products that enable businesses to deploy healing agents in their production environments and dramatically reduce MTTR. exciting? join us - please DM or https://t.co/Ff1p70ym0C
When all of world’s answer are available to all of world’s people, on can only wonder “What will the best questionbe, and how many such questions be asked? ”
- Aravind Srinivas
- https://t.co/tIEpXJQeIi
Meta launched Llama 3 to show the world what’s possible with open source LLMs.
500+ AI engineers just spent 24 hours straight putting it to the test.
Here’s what we saw at the @AIatMeta x @cerebral_valley#Llama3Hackathon (🧵):
New YouTube video: 1hr general-audience introduction to Large Language Models
https://t.co/Bl4WNuNyFJ
Based on a 30min talk I gave recently; It tries to be non-technical intro, covers mental models for LLM inference, training, finetuning, the emerging LLM OS and LLM Security.
The AI assistant travel app in @OpenAI's DevDay keynote today has got to be one of the most impressive live demos I've ever seen.
Brilliant presentation by @romainhuet + stellar design & engineering work by @simonpfish & @karoliskosas behind the scenes 👏