This is why @GeminiApp picked @OpenPipeAI for this week's AI Infrastructure & Developer Tools competition:
"I believe Openpipe addresses a critical and underserved segment of the LLM lifecycle: practical, accessible fine-tuning for production applications. The market for custom AI solutions is exploding, and companies will increasingly need to tailor generic models for specific use cases to achieve reliable performance. By simplifying this process and leveraging real-world data for continuous improvement, Openpipe has the potential to become the standard tool for enterprise LLM customization, unlocking billions in value by making AI more reliable and performant across industries."
Want the rest of the verdict? Explore what other models think of Openpipe at:
https://t.co/OpyfHvoeES
If you want to evaluate startup(s) with leading AI models go to https://t.co/iwNJqMHs4P to signup and get 5 free evaluations!
#startupdose #startups #tech #innovation #ai #aiinfrastructure #developertools
I came across the dataset and tools from @OpenPipeAI's blog and it was a nice chance to port this into verifiers by @willccbb to create an environment from scratch.
Willow is the first-ever dictation app that learns how you speak and gets better every time.
Super proud of the team @OpenPipeAI for innovating on the post-training.
More details coming soon
Today was the first time I used my fine-tuned model
I used Llama 3.1 using @OpenPipeAI the results are encouraging.
There are like 5 more to build so wish me luck 😂
@jeremyphoward@teknium@aidanshandle 👀 Lora inference is part of our recent release with @OpenPipeAI and I was told we're working on an independent way to do lora inference on @wandb inference.
Will keep you posted if you'd like Jeremy 🫡
We as a team are learning RL for the first time this weekend.
We're totally new to this field, but @OpenPipeAI's docs really helped us kickstart!
@wandb
some thoughts on why/how the standard paradigm for optimizing Task Specific Agents will be Harness Engineering + Rubric Based Task Specific RL.
this write up codifies a lot of my thoughts on where harness engineering is going + inspiration from @corbtt on @latentspacepod
Steps:
1. Obsessively hand/auto tune agent harness until you reach a baseline threshold of task performance. Goal: make sure the agent has roughly what it needs to succeed.
2. Do Task Specific RL to make the model better at operating in the harness, touching the model weights pushes us beyond what harness engineering alone can do.
FAQs:
1. Why in this order?
If your agent rarely succeeds on the Task, it can’t get enough of a reward, this makes RL difficult. Optimize the harness first —> “You can’t succeed if you don’t have the right tools”
2. Why Not Just Keep Optimizing your Harness, I thought Prompt Engineering is the way?
Harness engineering in the latter stages is incredibly hard. It’s also combinatorially complex from the start. You have to jointly optimizes each component(System Prompt, Tools/Skills/MCP, Subagent definitions, Additional Context) but you have:
- A Selection Problem: How do you intelligently select relevant tools from a sea of possibilities? Context is a precious resource and selecting too many tools is confusing and degrades perf.
- Codependency: No component is optimized in isolation, it’s one big system (ex: changing the system prompt may change how/if a tool is called)
3. So how should I start?
First painstakingly test everything in your harness.
- try multiple models
- hand tune system prompts, try GEPA
- more/less tools, tool descriptions, compound tools
- handing off tasks to subagents
- preloading useful notes, docs, and instructions as references
eventually when you hit a wall (on performance or human resources), you move on. You can also move on much earlier once you hit some performance threshold.
4. What does RL get you?
Agents (Claude Code, Codex) from the labs are so reliable at using their tools (WebSearch, Multi-Edit, Grep) because they’re directly post-trained with them. We want that same for our tasks, we want to make the model more comfortable using its harness while training to increase Task performance.
5. How should I get started with Task Specific RL?
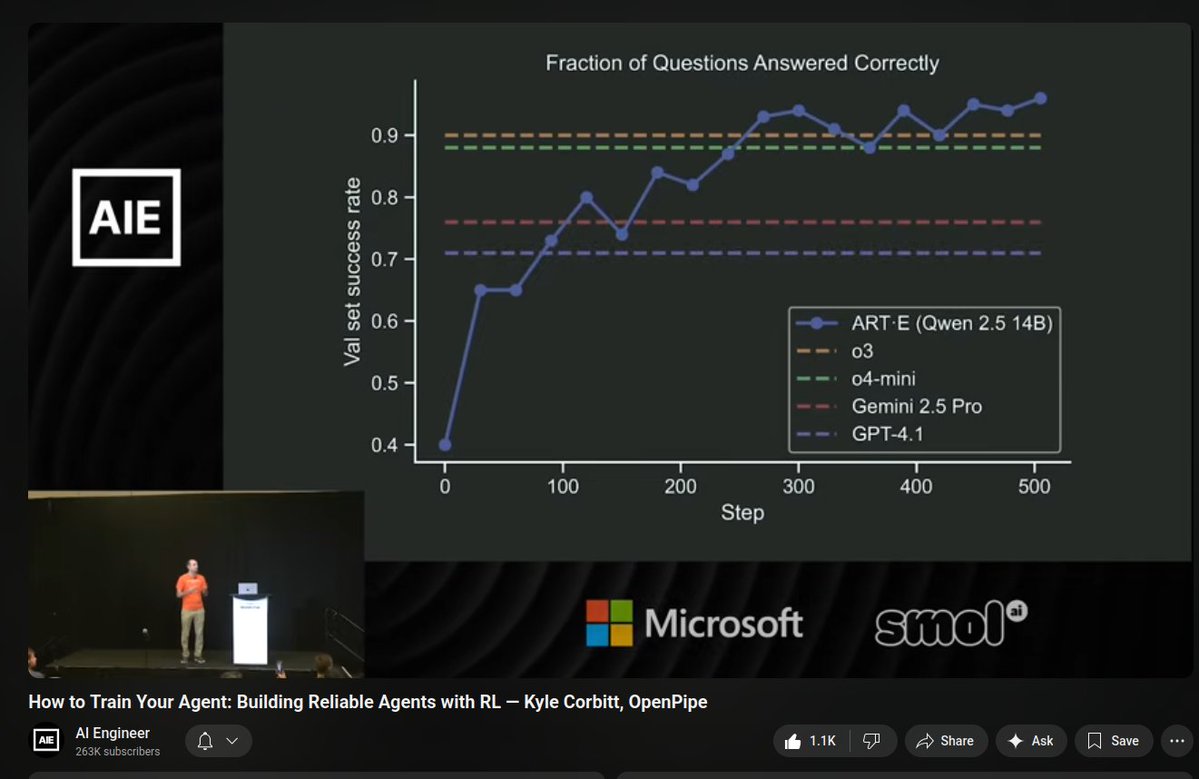
A fantastic first place to start is RULER from @OpenPipeAI which relies on rubrics created by you + LLM as a judge across multiple generations. For your task, you probably already have a set of ideas on what’s good, codifying that in a rubric is all you need to get started
working on writing up a walkthrough blog of this with code. really excited about building products that treat agent building as a harness optimization problem that you measure deeply + push further with RL
LIVE: Kyle Corbitt, Head of the OpenPipe team at CoreWeave, joins ThursdAI to talk about launching the first Serverless Reinforcement Learning capability. https://t.co/sK5A4W3nLa
@MaziyarPanahi@TrelisResearch@wandb Serverless RL from the @OpenPipeAI crew (now also at Coreweave) with W&B inference is pretty sweet - new models being added soon too
https://t.co/xEkguCluHF
We've started a great tradition at CoreWeave of shipping an integrated new product weeks after acquisition - congrats @OpenPipeAI on the serverless RL launch!
I'm in the unfortunate position to let you know that I've fallen for the RL-LLMs propaganda 100% with these results from openpipe
I am now fully RL pilled and there is no turning back
very sorry folks
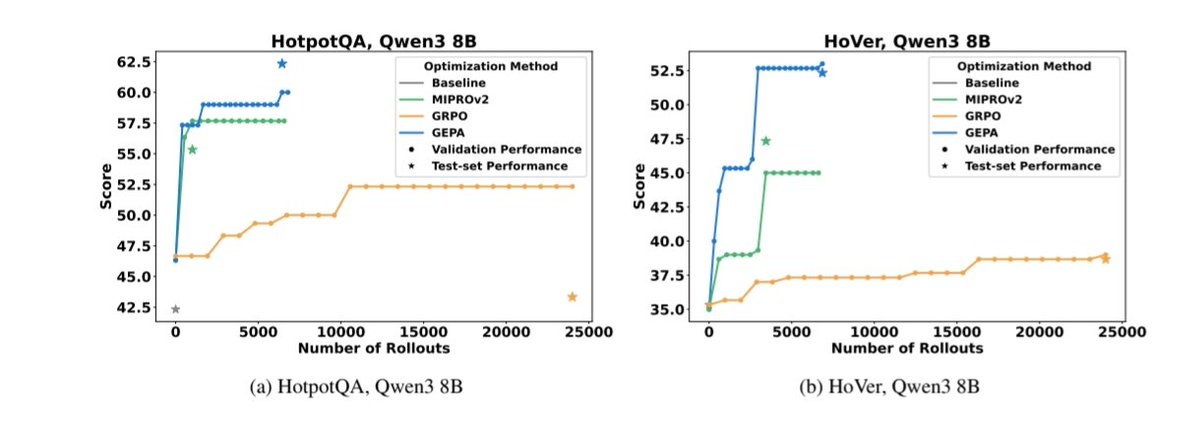
@yacinelearning One thing that surprised me pretty much is how well feedback from LLM is for automatic improvement. OpenPipe is one example with RL, but it also works well with prompt optimization (sometimes outperforming RL), see GEPA paper.
https://t.co/hzMbQajZvs