1/ today we're releasing muse spark, the first model from MSL. nine months ago we rebuilt our ai stack from scratch. new infrastructure, new architecture, new data pipelines. muse spark is the result of that work, and now it powers meta ai. 🧵
We propose GPA (Generalized Primal Averaging), a new optimizer for LLM Training, making interesting connections to DiLoCo and Schedule-Free!
Paper: https://t.co/COvSXCjfTD and Code: https://t.co/8pDSGoGl8e. Checkout below thread for more details.
1/10 Are DiLoCo and Schedule-Free actually related? A brief history and unusually late advertisement for our work: Smoothing DiLoCo with Primal Averaging for Faster Training of LLMs (see https://t.co/ESaSU8kwpx).
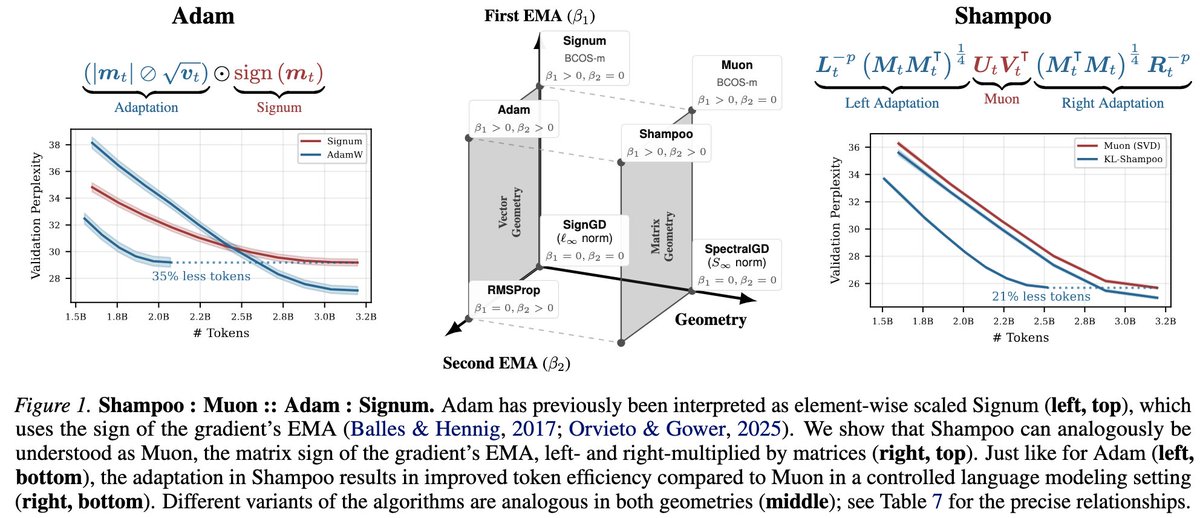
1/14 Is Muon “better” than Shampoo?
We argue that their relationship parallels Adam's relationship with Signum. Analogous to @lukas_balles and Hennig’s (2018) decomposition of Adam into element-wise scaled Signum, we can decompose Shampoo as left- and right-adapted Muon.
Why do gradients increase near the end of training?
Read the paper to find out!
We also propose a simple fix to AdamW that keeps gradient norms better behaved throughout training.
https://t.co/t5gxzV9CrZ
wow. The new model from @LumaLabsAI extending images into videos is really something else. I understood intuitively that this would become possible very soon, but it's still something else to see it and think through future iterations of.
A few more examples around, e.g. the girl in front of the house on fire
https://t.co/wDiCirpmUa
I absolutely love this education demo of @OpenAI. Let's make it available in all languages, and personalised to each country.
For example, we could do Spanish for kids and teenagers in Bolivia, giving them access to a technical education that otherwise would not be available to them.
Voice opens up the opportunity to do this even with old not-smart phones, e.g. a farmer in Ghana could start a conversation to get assistance on how to run a farm more efficiently and make more money.
There's a great opportunity here to help people in the entire world, and the AI community should embrace it.
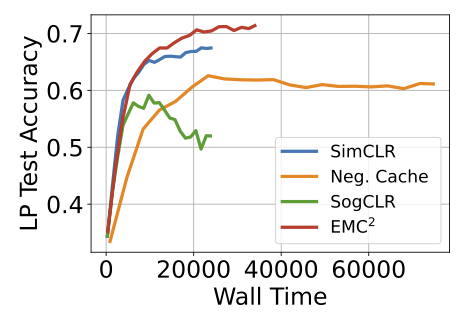
In https://t.co/4JAk4ZWkWo, we propose an MCMC sampler for contrastive learning to look for negative samples - works especially well with small batch size and we showed stationary point convergence.
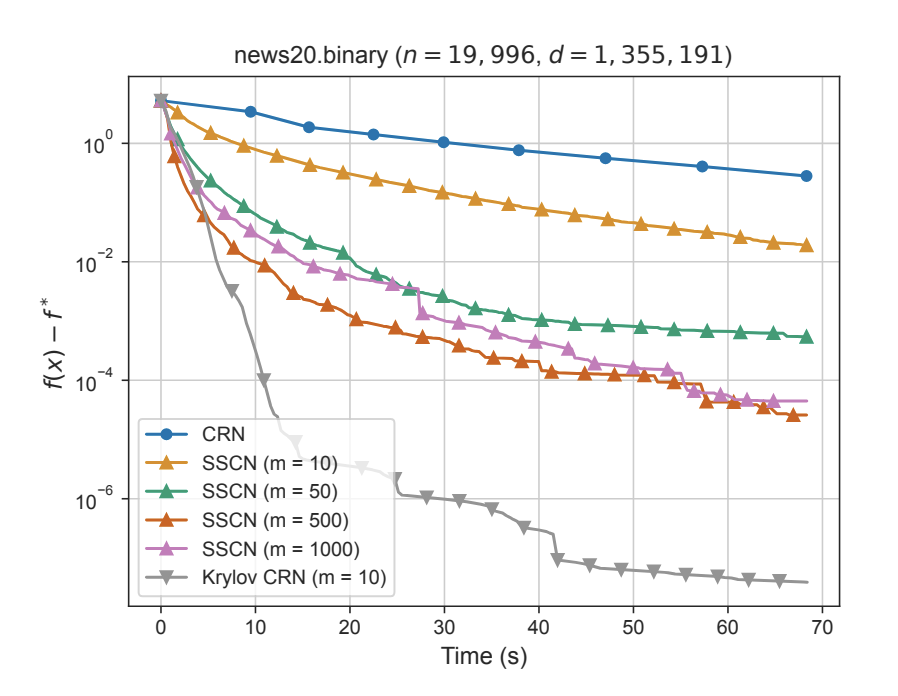
If you are at #AISTATS2024, checkout our work "Krylov cubic regularized Newton: A subspace second-order method with dimension-free convergence rate" where we present a novel subspace method that converges fast by selecting a subspace with a handful of dimensions (size m <<< d ).
Congrats to @AIatMeta on Llama 3 release!! 🎉
https://t.co/UBwFPTJM6V
Notes:
Releasing 8B and 70B (both base and finetuned) models, strong-performing in their model class (but we'll see when the rankings come in @ @lmsysorg :))
400B is still training, but already encroaching GPT-4 territory (e.g. 84.8 MMLU vs. 86.5 4Turbo).
Tokenizer: number of tokens was 4X'd from 32K (Llama 2) -> 128K (Llama 3). With more tokens you can compress sequences more in length, cites 15% fewer tokens, and see better downstream performance.
Architecture: no major changes from the Llama 2. In Llama 2 only the bigger models used Grouped Query Attention (GQA), but now all models do, including the smallest 8B model. This is a parameter sharing scheme for the keys/values in the Attention, which reduces the size of the KV cache during inference. This is a good, welcome, complexity reducing fix and optimization.
Sequence length: the maximum number of tokens in the context window was bumped up to 8192 from 4096 (Llama 2) and 2048 (Llama 1). This bump is welcome, but quite small w.r.t. modern standards (e.g. GPT-4 is 128K) and I think many people were hoping for more on this axis. May come as a finetune later (?).
Training data. Llama 2 was trained on 2 trillion tokens, Llama 3 was bumped to 15T training dataset, including a lot of attention that went to quality, 4X more code tokens, and 5% non-en tokens over 30 languages. (5% is fairly low w.r.t. non-en:en mix, so certainly this is a mostly English model, but it's quite nice that it is > 0).
Scaling laws. Very notably, 15T is a very very large dataset to train with for a model as "small" as 8B parameters, and this is not normally done and is new and very welcome. The Chinchilla "compute optimal" point for an 8B model would be train it for ~200B tokens. (if you were only interested to get the most "bang-for-the-buck" w.r.t. model performance at that size). So this is training ~75X beyond that point, which is unusual but personally, I think extremely welcome. Because we all get a very capable model that is very small, easy to work with and inference. Meta mentions that even at this point, the model doesn't seem to be "converging" in a standard sense. In other words, the LLMs we work with all the time are significantly undertrained by a factor of maybe 100-1000X or more, nowhere near their point of convergence. Actually, I really hope people carry forward the trend and start training and releasing even more long-trained, even smaller models.
Systems. Llama 3 is cited as trained with 16K GPUs at observed throughput of 400 TFLOPS. It's not mentioned but I'm assuming these are H100s at fp16, which clock in at 1,979 TFLOPS in NVIDIA marketing materials. But we all know their tiny asterisk (*with sparsity) is doing a lot of work, and really you want to divide this number by 2 to get the real TFLOPS of ~990. Why is sparsity counting as FLOPS? Anyway, focus Andrej. So 400/990 ~= 40% utilization, not too bad at all across that many GPUs! A lot of really solid engineering is required to get here at that scale.
TLDR: Super welcome, Llama 3 is a very capable looking model release from Meta. Sticking to fundamentals, spending a lot of quality time on solid systems and data work, exploring the limits of long-training models. Also very excited for the 400B model, which could be the first GPT-4 grade open source release. I think many people will ask for more context length.
Personal ask: I think I'm not alone to say that I'd also love much smaller models than 8B, for educational work, and for (unit) testing, and maybe for embedded applications etc. Ideally at ~100M and ~1B scale.
Talk to it at https://t.co/KmKRlZeTHQ
Integration with https://t.co/RD6MRWT2zz
Interested in training SOTA LLMs end-to-end on Trainium - the AI chip purpose built by AWS? We shared our experience on training the LLaMA2 (7B) model on Trn here: https://t.co/W4z3LEwJya (Code and scripts to follow soon)
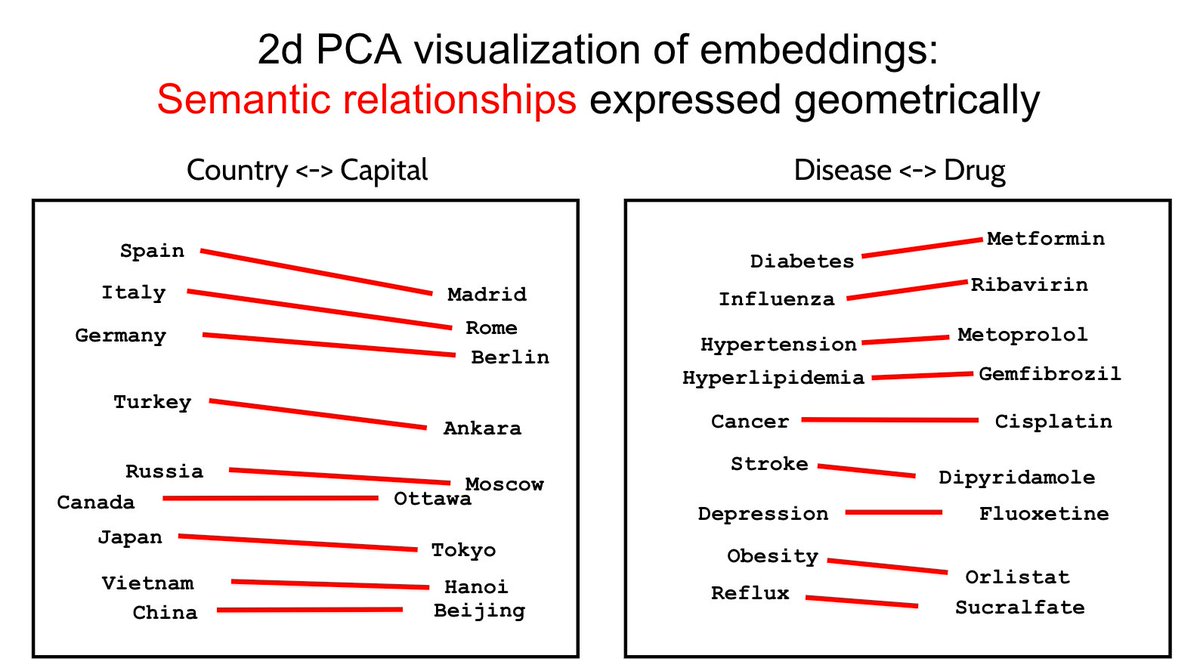
On behalf of our co-authors Tomáš Mikolov, @ilyasut and Kai Chen, @greg_corrado and I were delighted to accept the #NeurIPS2023 Test of Time Award for the "word2vec" paper (https://t.co/HMnrA18EO5). Thanks to the @NeurIPSConf test of time committee for honoring us with this award!
This work started as an earlier ICLR 2013 workshop paper (https://t.co/vlIOxF7kmL) that explored a few different self-supervised techniques for learning word embeddings. The skip-gram approach worked better than others, and we scaled that and explored various alternative loss functions in the NeurIPS paper.
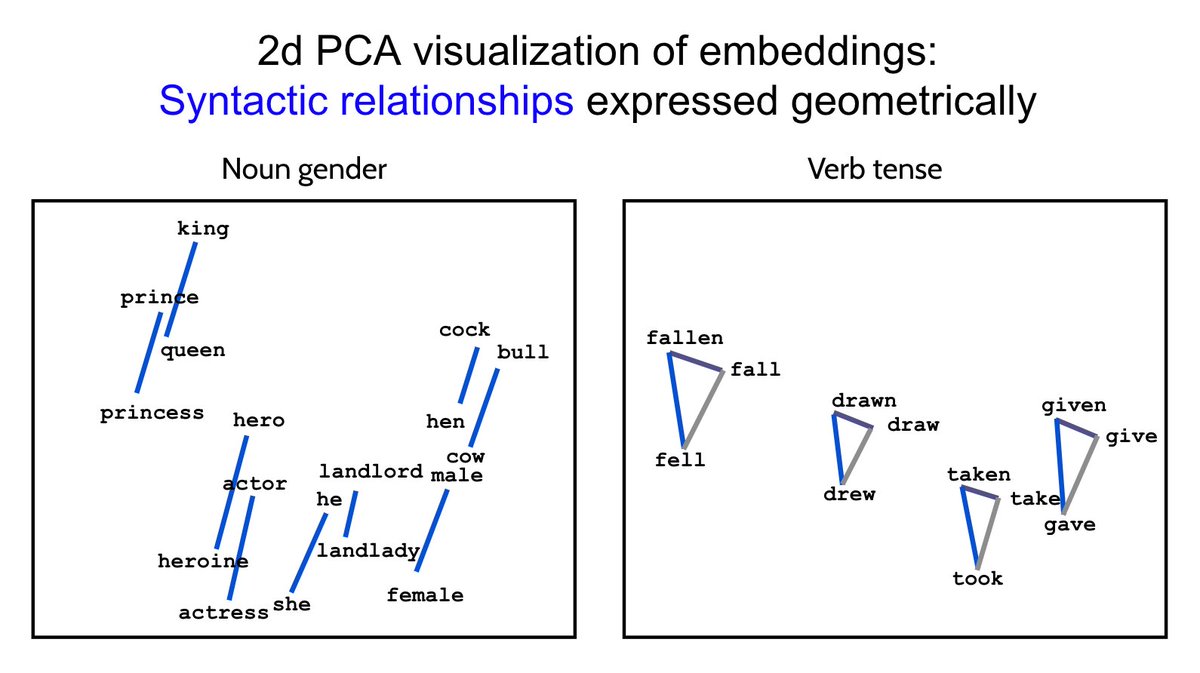
The geometric relationships contained in the trained word embeddings were one thing about this work that I think people found interesting (see images from our talk below).
Explore how @amazon leveraged the NVIDIA NeMo framework, GPUs, and EFA from @awscloud to train its next-generation LLM, giving some of the largest Amazon Titan foundation models customers a faster, more accessible solution for #generativeAI. #AWSreinvent https://t.co/fMyxn946mr
One of the best tutorial-style repos since @karpathy's minGPT! GPT-Fast: a minimalistic, PyTorch-only decoding implementation loaded with best practices: int8/int4 quantization, speculative decoding, Tensor parallelism, etc. Boosts the "clock speed" of LLM OS by 10x with no model change!
We need more minGPTs and GPT-Fasts in the open-source world! Created by the awesome @cHHillee from PyTorch team.
Blog: https://t.co/wCaBW7A2pn
Code: https://t.co/2WvKNnJApw
Our group is hiring PhD interns for projects related to optimization and large-scale training of deep learning models. Desired background: Design and implementation of optimization algorithms. If interested, please get in touch. #internship2023#phdinternships#machinelearning
I'll be at #NeurIPS2022 this week! @tri_dao and I will be presenting FlashAttention (https://t.co/0TWBnwJ2Dg) at Poster Session 4 Hall J #917, Wednesday 4-6 PM.
Super excited to talk all things performance, ML+systems, and breaking down scaling bottlenecks!
Updated this 1-year old post on diffusion models with some new content based on recent progresses - including classifier-free guidance, GLIDE, unCLIP, Imagen and latent diffusion model.