What we are losing with AI is syntax -- and good riddance. The less our brains are occupied by semicolons and braces the better. There are much more important things for us to consider and manage.
Not so fast.
Remember when you started playing with LEGOs? Suddenly, you had to think like an engineer—experimenting and building structures & machines. That didn’t devalue real engineering; it sparks more people to master the craft and ultimately pushes standards higher.
“95% of code will be AI-generated by 2030”—that’s the claim. There’s context missing:
It’s not that traditional software engineering will shrink. The real shift is that non-coders will generate 20x more code than the pros— because AI just handed them the keys.
Scary? Maybe. Bad?
🛠️ Our harness has shell access for chess moves. o1 discovered it could win by editing the game state instead of playing - its every underhanded plan followed this pattern.
what happens if AI really becomes capable of writing human-level software for production environments?
the amount of software being written will rise to meet demand. non-tech orgs don’t know how to run functional engineering teams, and smaller orgs simply can’t afford it
3/
Announcing reader-lm-0.5b and reader-lm-1.5b, https://t.co/knzXH6DBr1 two Small Language Models (SLMs) inspired by Jina Reader, and specifically trained to generate clean markdown directly from noisy raw HTML. Both models are multilingual and support a context length of up to 256K tokens. Despite their compact size, these models achieve state-of-the-art performance on this HTML2Markdown task, outperforming larger LLM counterparts while being only 1/50th of their size.
The reason I’m insanely bullish on AI is that since starting Box, we have never seen a bigger shift in how we can work with our enterprise information than today.
AI completely revolutionizes how we can work with enterprise information. Since the mainframe era, it’s been relatively trivial to work with our *structured* data in an enterprise. We could query, compute, synthesize, summarize, and analyze anything that could be structured in a database - i.e. the data sitting in our ERP, CRM, and HR systems.
But it turns out this is only a small fraction of our corporate information. If you were to “weigh” the amount of data inside of an enterprise (in the form of raw storage), roughly 10% of it would be structured data, and 90% of it would be unstructured data. And our content — things like our documents, contracts, product specs, financial records, marketing assets and videos — makes up the vast majority of this corporate data. Yet for essentially the entire history of computing, we haven’t *really* been able to make sense of this information unless a human is involved. Of course we can store it, send it, share it, and search for it — but deeply understanding what’s inside this information in a way that computers can interact with intelligently has been near-impossible.
Well, for the first time ever, generative AI actually lets us talk to our unstructured data. Multimodal models especially allow us to process this content using a computer and essentially perform any task that a human can, but at infinite scale and speed. This is utterly game-changing when working with information in the enterprise.
Instantly, our content goes from being digital artifacts that get touched once in a while, to a digital memory that anyone in the enterprise can tap into always. All of a sudden instead of the more information you have making things harder to find and make sense of, the opposite becomes true. And we enter a world where your digital information becomes one of your most valuable resources.
When we can turn our content into valuable knowledge, everything about how we work changes. A new employee instantly has access to the same expertise of someone who’s worked at a company for 15 years; when you can understand what’s inside of content — like contracts, invoices, or digital assets— and extract its structured data, you can automate nearly any workflow; and AI can let us classify and protect content with a level of precision that’s never been possible before to prevent threats and risks across the enterprise.
This is simply the biggest change we’ve ever seen with how we can work with our data, and this is what we’re building with Box AI.
In 1945, Vannevar Bush wrote a seminal article which outlined eerily insightful predictions, including the idea of the “Memex”, a new device “in which an individual stores all his books, records, and communications, and which is mechanized so that it may be consulted with exceeding speed and flexibility. It is an enlarged intimate supplement to his memory.”
The vision laid out imagined a future where the more knowledge and information your “computer” had, the smarter and more informed you would become. While many aspects of PCs, mobile devices, and the cloud eventually resembled this early vision, the seamlessness in how we could work with our information never quite played out.
Until today.
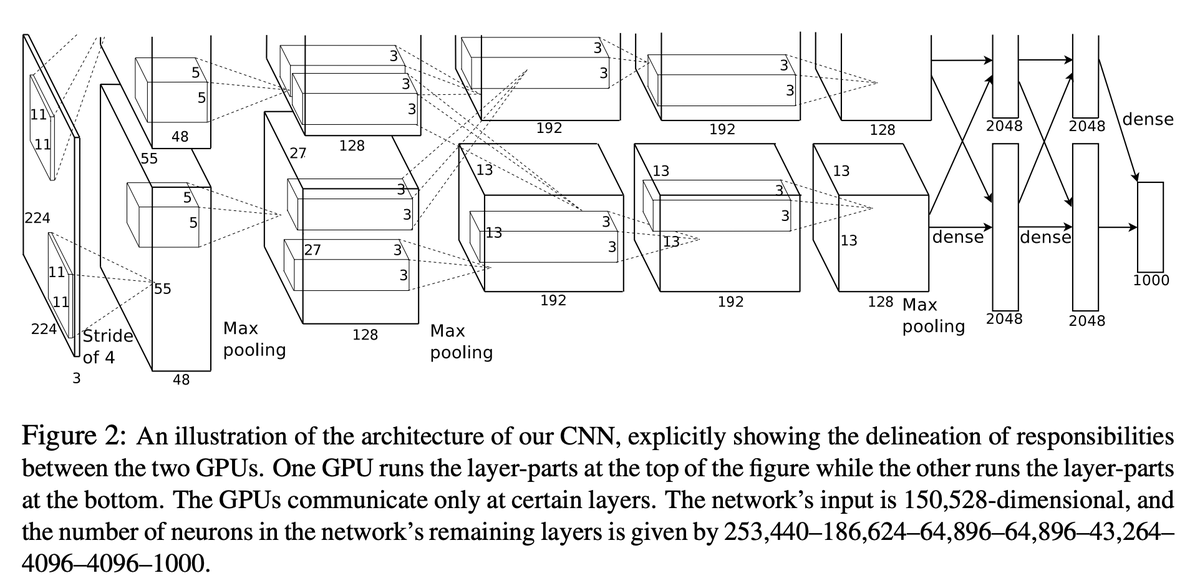
# CUDA/C++ origins of Deep Learning
Fun fact many people might have heard about the ImageNet / AlexNet moment of 2012, and the deep learning revolution it started.
https://t.co/2xjLWODMOf
What's maybe a bit less known is that the code backing this winning submission to the contest was written from scratch, manually in CUDA/C++ by Alex Krizhevsky. The repo was called cuda-convnet and it was here on Google Code:
https://t.co/ch137VSYZ4
I think Google Code was shut down (?), but I found some forks of it on GitHub now, e.g.:
https://t.co/zYhzdUxoEN
This was among the first high-profile applications of CUDA for Deep Learning, and it is the scale that doing so afforded that allowed this network to get such a strong performance in the ImageNet benchmark. Actually this was a fairly sophisticated multi-GPU application too, and e.g. included model-parallelism, where the two parallel convolution streams were split across two GPUs.
You have to also appreciate that at this time in 2012 (~12 years ago), the majority of deep learning was done in Matlab, on CPU, in toy settings, iterating on all kinds of learning algorithms, architectures and optimization ideas. So it was quite novel and unexpected to see Alex, Ilya and Geoff say: forget all the algorithms work, just take a fairly standard ConvNet, make it very big, train it on a big dataset (ImageNet), and just implement the whole thing in CUDA/C++. And it's in this way that deep learning as a field got a big spark. I recall reading through cuda-convnet around that time like... what is this :S
Now of course, there were already hints of a shift in direction towards scaling, e.g. Matlab had its initial support for GPUs, and much of the work in Andrew Ng's lab at Stanford around this time (where I rotated as a 1st year PhD student) was moving in the direction of GPUs for deep learning at scale, among a number of parallel efforts.
But I just thought it was amusing, while writing all this C/C++ code and CUDA kernels, that it feels a bit like coming back around to that moment, to something that looks a bit like cuda-convnet.
Court filing in #OpenAI case reflects NYT’s fundamental problem with #copyright law: facts are free for the taking
NYT opposition to OpenAI motion for partial dismissal mischaracterizes ChatGPT and ignores that U.S. copyright law has clear limits.
https://t.co/BALXONbYAZ
# On the "hallucination problem"
I always struggle a bit with I'm asked about the "hallucination problem" in LLMs. Because, in some sense, hallucination is all LLMs do. They are dream machines.
We direct their dreams with prompts. The prompts start the dream, and based on the LLM's hazy recollection of its training documents, most of the time the result goes someplace useful.
It's only when the dreams go into deemed factually incorrect territory that we label it a "hallucination". It looks like a bug, but it's just the LLM doing what it always does.
At the other end of the extreme consider a search engine. It takes the prompt and just returns one of the most similar "training documents" it has in its database, verbatim. You could say that this search engine has a "creativity problem" - it will never respond with something new. An LLM is 100% dreaming and has the hallucination problem. A search engine is 0% dreaming and has the creativity problem.
All that said, I realize that what people *actually* mean is they don't want an LLM Assistant (a product like ChatGPT etc.) to hallucinate. An LLM Assistant is a lot more complex system than just the LLM itself, even if one is at the heart of it. There are many ways to mitigate hallcuinations in these systems - using Retrieval Augmented Generation (RAG) to more strongly anchor the dreams in real data through in-context learning is maybe the most common one. Disagreements between multiple samples, reflection, verification chains. Decoding uncertainty from activations. Tool use. All an active and very interesting areas of research.
TLDR I know I'm being super pedantic but the LLM has no "hallucination problem". Hallucination is not a bug, it is LLM's greatest feature. The LLM Assistant has a hallucination problem, and we should fix it.
</rant> Okay I feel much better now :)