Together with UC Berkeley we are announcing the laser phase plate - a breakthrough in atomic resolution imaging. This is the brightest continuous wave laser in the world, 100 million times the intensity of the surface of the sun.
Phase contrast plays an important role in microscopy, but it was thought close to impossible for electron microscopy, where it would require interfering with an electron beam. Holger Mueller and Robert Glaeser proposed exactly this using a standing wave laser. It has taken over 15 years to make this a reality. Biohub partnered with UC Berkeley and Mueller to support this work and to engineer and build the technology.
Contrast has been the critical barrier to achieving atomic resolution imaging of the cell. In cryo-electron tomography, a cellular imaging technology that uses electron microscopy, the low contrast makes it impossible to resolve anything but the largest proteins within their cellular context. The laser phase plate removes that barrier.
With advances in AI this breakthrough in contrast will start to open up a new frontier in structural biology, that will allow us to see the molecular machines of the cell, and how they assemble into far more complex and dynamic systems, and understand how they work.
1/?) As promised to Sander Dieleman (@sedielem), we’re finally excited to share:
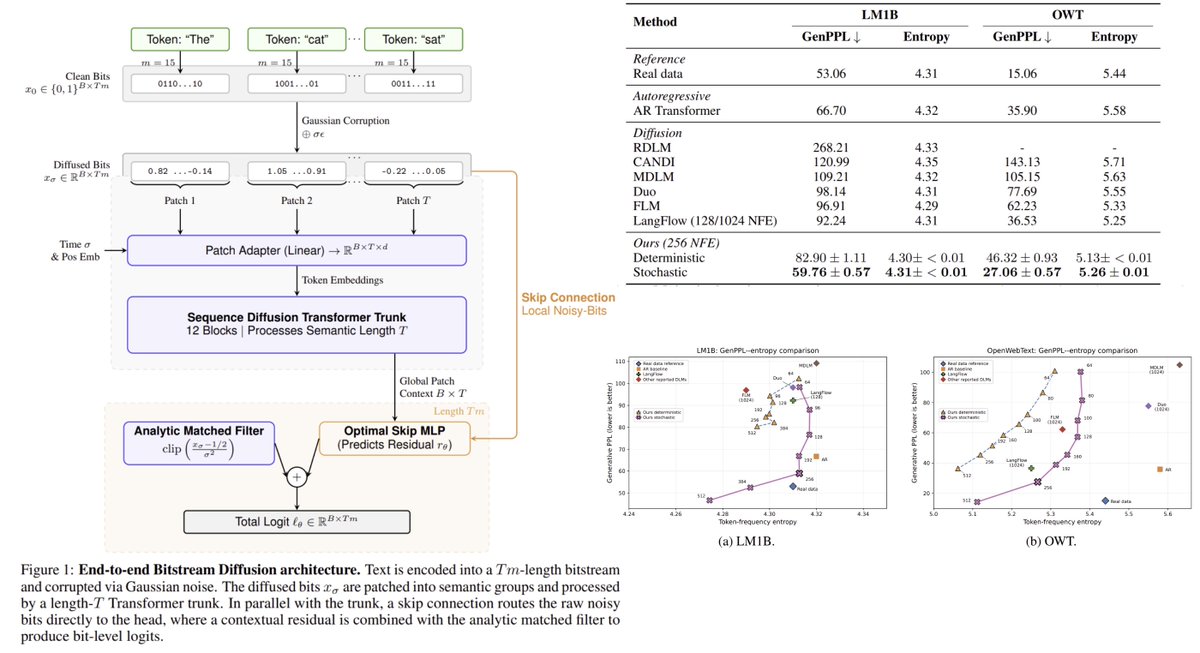
Towards Closing the Autoregressive Gap in Language Modeling via Entropy-Gated Continuous Bitstream Diffusion
We show that continuous diffusion can achieve very strong language modeling performance when operating directly on bitstreams, outperforming masked and uniform diffusion baselines, and essentially matching autoregressive models under our evaluation settings.
LLMs can hide a text in another text of the same length.
I'll explain how, it is very simple, you'll understand before I finish, and smile.
That's what I noticed during my #ICLR2026 poster session in Rio! 🇧🇷
Too bad you missed it, but let me remedy now
For 40+ years, building a robot that could rally with an elite human table tennis player at full speed was an unsolved problem. Sony AI's Ace research project set out to change that—and the results are now accepted for publication in @Nature and featured on the cover.
I work on the JAX team. If you're new to the field ignore this bait. The things you should focus on are understanding the math and how to program accelerators - really master your hardware and your methods. We try to make a great tool but don't obsess over tools early.
I trained an LLM from scratch on pre-1900 text to see if it could come up with quantum mechanics and relativity.
While the model is too small to do meaningful reasoning, it has glimpses of intuition.
When given observations from past landmark experiments, the model can declare that “light is made up of definite quantities of energy” and even suggest that gravity and acceleration are locally equivalent.
I’m releasing the dataset + models and leave this as an open problem to the research community.
I also include what this project has taught me about intelligence in a mini essay linked below.
🧵(1/n)
I'd like to thank @daniel_rossett for his help in my recovery from the POTS version of Long COVID. Daniel was key in bringing me back from highly disabled and suffering to being able to do what I want to again.
This X account is mostly focused on ML / AI. From that point of view, many of you know that in December 2024, I wasn't able to do the test of time award talk at NeurIPS, even by video call. Daniel started working
with me in March 2025. By April, I started to have days of no POTS symptoms, by June I was off all heart rate lowering medications, by September I was back to work. I'm back to full exercise, running, lifting weights, mountain biking, and have even done things I hadn't done before I got sick, like riding Whistler Mountain Bike Park.
I'm now getting the word out to help Daniel build a company that will bring this approach to more people.
after a bit of digging, first author @a1zhang has a GREAT blog-like description of the work + a nice minimal implementation. the blog is like 1000x better in describing the work than the paper. why do we still bother with papers.
Really interesting stuff happening on that other social network thanks to the open protocols and hackable algorithms. E.g there's Personalized Academic Recommendations and a whole paper about it.
https://t.co/rUdNViVU3T
New blog post w @pawtrammell: Capital in the 22nd Century
Where we argue that while Piketty was wrong about the past, he’s probably right about the future.
Piketty argued that without strong redistribution of wealth, inequality will indefinitely increase. Historically, however, income inequality from capital accumulation has actually been self-correcting. Labor and capital are complements, so if you build up lots of capital, you’ll lower its returns and raise wages (since labor now becomes the bottleneck).
But once AI/robotics fully substitute for labor, this correction mechanism breaks.
For centuries, the share of GDP that goes to paying wages has been 2/3, and the share of GDP that’s been income from owning stuff has been 1/3.
With full automation, capital’s share of GDP goes to 100% (since datacenters and solar panels and the robot factories that build all the above plus more robot factories are all “capital”).
And inequality among capital holders will also skyrocket - in favor of larger and more sophisticated investors. A lot of AI wealth is being generated in private markets. You can’t get direct exposure to xAI from your 401k, but the Sultan of Oman can. A cheap house (the main form of wealth for many Americans) is a form of capital almost uniquely ill-suited to taking advantage of a leap in automation: it plays no part in the production, operation, or transportation of computers, robots, data, or energy.
Also, international catch-up growth may end. Poor countries historically grew faster by combining their cheap labor with imported capital/know-how. Without labor as a bottleneck, their main value-add disappears.
Inequality seems especially hard to justify in this world. So if we don’t want inequality to just keep increasing forever - with the descendants of the most patient and sophisticated of today’s AI investors controlling all the galaxies - what can we do? The obvious place to start is with Piketty’s headline recommendation: highly and progressively tax wealth. This might discourage saving, but it would no longer penalize those who have earned a lot by their hard work and creativity. The wealth - even the investment decisions - will be made by the robots, and they will work just as hard and smart however much we tax their owners.
But taxing capital is pointless if people can just shift their future investment to lower tax countries. And since capital stocks could grow really fast (robots building robots and all that), pretty soon tax havens go from marginal outposts to the majority of global GDP. But how do you get global coordination on taxing capital, when the benefits to defecting are so high and so accessible?
Full automation will probably lead to ever-increasing inequality. We don’t see an obvious solution to this problem. And we think it’s weird how little thought has gone into what to do about it.
Many more thoughts from re-reading Piketty with our AGI hats on at the post in the link below.
Stronger Normalization-Free Transformers – new paper.
We introduce Derf (Dynamic erf), a simple point-wise layer that lets norm-free Transformers not only work, but actually outperform their normalized counterparts.
I think GitHub needs competition. I’m not convinced that either Codeberg or sourcehut are the solution. I find both completely non enjoyable to use. They would need a lot of love to get to where GitHub is today, even with all of its faults.
Announcing Olmo 3, a leading fully open LM suite built for reasoning, chat, & tool use, and an open model flow—not just the final weights, but the entire training journey.
Best fully open 32B reasoning model & best 32B base model. 🧵
🤔What you’ll get from this monograph:
A clear and systematic walkthrough of how diffusion models emerged, how the main formulations connect, and how today’s methods achieve controllability and speed, leading to the next generation of diffusion-based generative models: the flow-map family.
• A unified view linking Variational (VAE), Score-Based (Energy-Based), and Flow-Based (Normalizing Flow) approaches — all as simple changes of variables over time.
• How guidance and numerical solvers make generation faster and controllable.
• The rise of Flow Map Models (e.g., Consistency Model, Consistency Trajectory Model, Mean Flow) shaping the next wave of generative AI.
🔗Link to our monograph: https://t.co/YRhX6wOwG3
Robotics / VLM researchers from Meta
If you're a VLM / VLA / post-training researcher laid off from Meta, and in need of urgent visa support, drop me a dm.
We have a number of Visiting Researcher positions open in our Seattle office. You get to work on a publishable project, or even continue your Meta work, while searching for a permanent role.
We have unprecedented access to manufacturing assembly line video data and a decent fleet of GPUs. This might give you unparalleled insight into the actual problems from the industry thats the biggest consumer of robots.
We won't make you go through an interview process, and we have the best immigration lawyers on retainer. So you can be on staff in a couple of weeks. :-)
#MetaLayoffs #Robotics #VLA #VLM
Strongly disagree with the original post, and agree with that Berkeley, Stanford, and UCSD actually do offer many good courses that are cutting edge and timely.
For example, this Winter I offered this machine learning systems course https://t.co/Zl27QyT59T at UCSD (all materials are public available btw) which attracted 220+ students across UCSD CSE/HDSI/ECE
I covered how DeepSeek V3 was made literally 2 weeks after its release, and one of the programming assignment my TA team designed was to implement an all2all primitive, which precisely was one of the core innovation made by DSK-v3.
Also got very encouraging feedback from students, too, to let you appreciate the happiness of being a teacher 😀
Probably will make a Youtube course with more latest content in both English and Chinese next quarter when I have more time to make it more accessible!