Update: new gig, and I'm hiring!
I recently joined the Institute of Foundation Models in the SF Bay Area! Our goal is to train large-scale FULLY open-source LLMs at and beyond the frontier, from scratch, with open science, open data and open checkpoints.
We are hiring across the training stack. Further, I'm building a new team to advance open agentic LLMs, and hiring researchers/engineers on-site. Send me a DM or email if you are interested! I'll also be at #NeurIPS2025 in San Diego this week to talk to potential candidates for internships and FT positions.
Tera IPOs coming! $1T sounds like a lot. But $1T is just a 7-m-wide gold cube, thanks to massive inflation since 1971 when $ and gold decoupled. A little house full of gold. To put things in perspective: the 2017 neutron star merger GW170817 produced several earth masses of gold.
Frontier LLMs are converging on efficient, adaptive reasoning. Opus 4.7 lets the model decide how deeply to reason. GPT-5.5 achieves strong results with fewer reasoning tokens.
We study a related but more structural question: what 𝗸𝗶𝗻𝗱 𝗼𝗳 𝗿𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴 should we adapt?
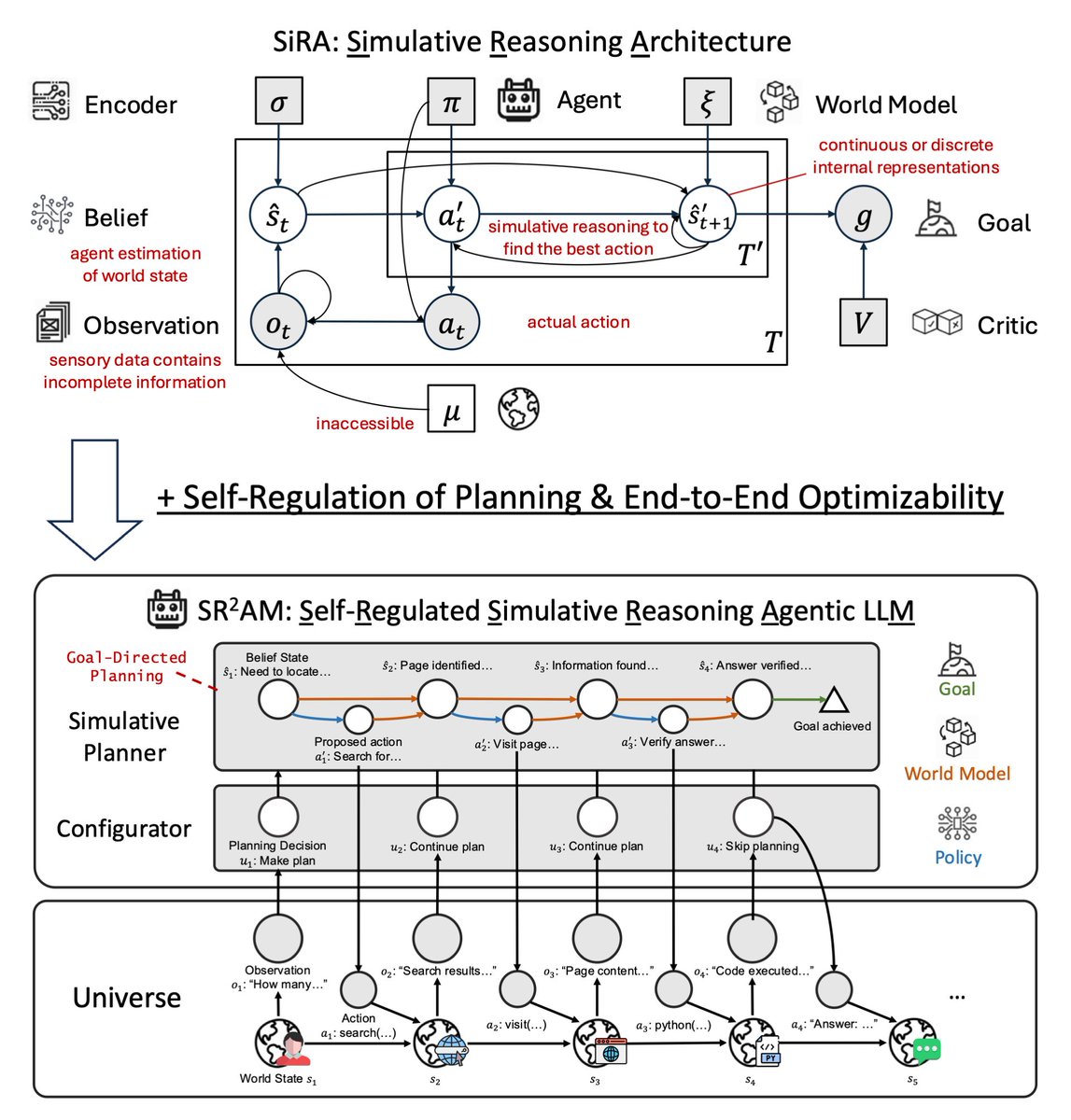
Last year in SiRA (upper figure), we showed that simulative reasoning (System II), which uses a 𝘄𝗼𝗿𝗹𝗱 𝗺𝗼𝗱𝗲𝗹 to evaluate consequences of actions, yields up to 124% improvement over reactive baselines (System I), and that strong reasoning models (o1, o3-mini) fail as planners without this structure.
In our new paper SR²AM (lower figure), we add a learned 𝗰𝗼𝗻𝗳𝗶𝗴𝘂𝗿𝗮𝘁𝗼𝗿 (System III) that self-regulates when to simulate, how far ahead, and when to skip planning entirely.
Efficient reasoning is not just shorter reasoning: it is better allocation of simulation.
Thrilled to share that we founded Recursive to create AI that safely conducts experiments on how to improve itself in an open-ended process of endless, automated scientific discovery. As I wrote in my 2019 AI-generating algorithms paper, this will likely be the fastest path to superintelligence. Our work since has shown the power of this approach. Excited to scale up and improve upon ideas like the Darwin Gödel Machine, HyperAgents, ADAS, OMNI, ALMA, The AI Scientist, PromptBreeder, Rainbow Teaming, Automated Capability Discovery, and other work on open-ended and AI-generating algorithms. We’ve assembled a dream team of researchers and significant resources to pursue this vision. My amazing co-founders are pictured here, and we have an all-star team of founding members (we’re over 25 and growing).
Please join us if you are interested! Follow our progress @Recursive_SI
@charuman wasn't meant as sarcasm
it's always nice to see a lab so confident/secure in their capabilities that they can openly publish all their struggles
@finbarrtimbers I think this is likely a difference of scale mainly. If there's enough filtered data to train on, then use that. If there's limited data, train on all.
🍫 CocoaBench v1.0 is out!
CocoaBench is a benchmark for unified digital agents, built around open-world tasks that require composing 💻 coding, 👀 vision, 🌐 search.
Since our first research preview last December, we have expanded the benchmark substantially with community contributed tasks, and spent months testing and refining the tasks, evaluations, and agent runs.
Some takeaways:
• Even the best agent system reaches only 45.1% on CocoaBench v1.0.
• Coding agents like Codex are already surprisingly strong on general tasks beyond software engineering.
• Stronger agents tend to push more of the work into code.
• Open source models still lag behind leading frontier models on these general tasks.
👇More on the website and in the paper
#AI #Agents #LLM #Benchmark #CocoaBench
A visually convincing rollout is not the same thing as a useful world model.
WR-Arena is built to test the harder question: can a model simulate futures well enough to support action, planning, and reasoning?
That’s the shift from simple next-state prediction to realistic world simulation grounded in real-world utility.
Paper + code are live.
https://t.co/x4zQfpHzKt
https://t.co/FVvnKQpCdd
#AI #WorldModels #Benchmarking #EmbodiedIntelligence #PhysicalAI #MachineLearning
Back in beautiful New Haven this weekend for YHack.
We’ll be there with K2 Think V2, a fully open-source reasoning system.
Hackers! Dig into how it works: https://t.co/xALonGPL6n
Yes and no. Very often it turns out that what you think solves the problem is not what actually solves it, and this you only find out by not moving on, but making sure you have experiments that back up the *exact* statement you make removing all reasonable confounders. And that, you get from one of:
- public review
- extremely strict colleagues
- insane self discipline
Can language models learn useful priors without ever seeing language?
We pre-pre-train transformers on neural cellular automata — fully synthetic, zero language. This improves language modeling by up to 6%, speeds up convergence by 40%, and strengthens downstream reasoning.
Surprisingly, it even beats pre-pre-training on natural text!
Blog: https://t.co/Pni0RsIcxL
(1/n)