🚨🚨🚨A research project idea! How to measure world models?
Everyone's talking about world models these days. World model here, world model there. We can argue about what "world model" actually means, and we have some interesting results on that, but let's assume some hand-wavy definition for now. The real question is how you tell a good world model from a bad one.
Here's my bet on what actually matters, and it isn't how real the video looks or whether you can read off physical quantities from some giant latent. It's the structure of how the latents evolve. Say a rock is flying towards you and you want to plan an escape — do you care about its velocity? its energy? the projection of its velocity onto the 2D plane? They're all nonlinearly related, so chasing any one of them is the wrong target. What matters more is whether there's a simple, interpretable rule for how the latents move. And it has to be the latents — the real degrees of freedom aren't the pixels. Write down the map from past latents to future latents: what's its Jacobian? The world is noisy, so do errors propagate in a reasonably uniform way, or are there points where a tiny error blows up immediately? And separately, find the smallest latent space that still works and check whether its dimension matches what physics says it should be.
Meanwhile the field measures world models in a dozen ways, and they quietly disagree with each other. Representational probing puts a linear probe on the representation and asks what's decodable. Information-based methods try to measure something like the predictive information the latents carry about the future. Rollout error runs the model forward and tracks how fast it drifts from reality. Then there's downstream task success — does it help on some task — versus closed-loop utility, where an agent actually plans with it and you see whether it succeeds. Different things, and they often disagree.
So two ways to make sense of the mess. One is empirical: take many settings and many models, measure all these metrics, and map how they correlate, similar to the "Fantastic Generalization Measures and Where to Find Them," paper, but for world models. The other is to stop treating them as separate benchmarks at all. There's really one thing underneath: a system that changes over time, that you can act on, and that you only ever see part of. Every metric is just one shadow of it — realism checks the frames, rollout error checks the predictions, probing checks the state, and closed-loop checks the planning. Each hides an assumption about when it's even a fair test. Make those explicit, and ask the real question: when does doing well on one metric actually guarantee doing well on another, and when do they just happen to agree?
I'd love to hear what people think, and let me know if you want to collaborate on it.
We’ve identified industrial-scale distillation attacks on our models by DeepSeek, Moonshot AI, and MiniMax.
These labs created over 24,000 fraudulent accounts and generated over 16 million exchanges with Claude, extracting its capabilities to train and improve their own models.
at long last, the final paper of my phd
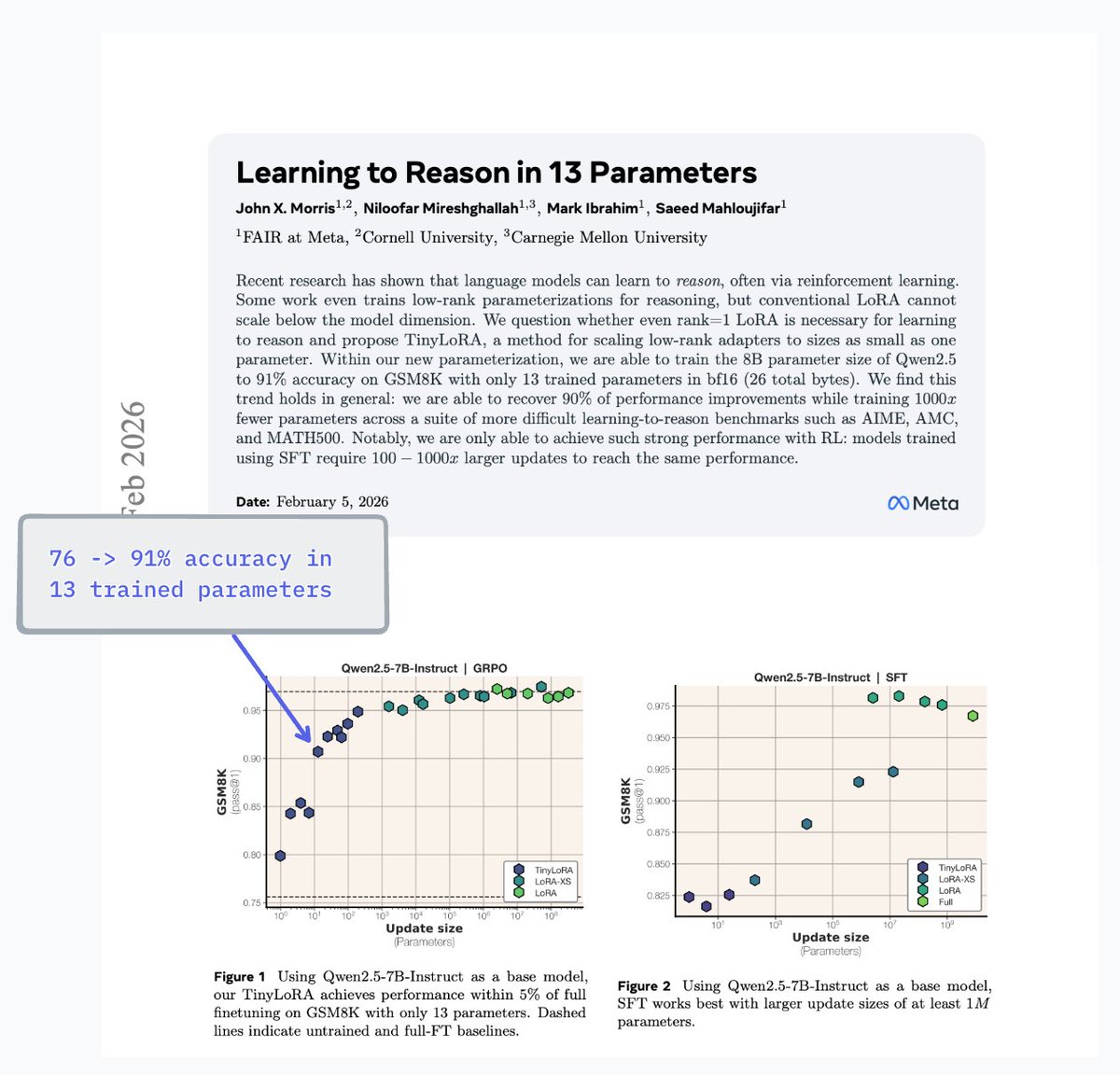
🧮 Learning to Reason in 13 Parameters 🧮
we develop TinyLoRA, a new ft method. with TinyLoRA + RL, models learn well with dozens or hundreds of params
example: we use only 13 parameters to train 7B Qwen model from 76 to 91% on GSM8K 🤯
Simple vision pretraining by predicting next step embedding. The embedding itself is trained along with this while stop grad is applied when it is used as a target.
Some people are unhappy with the AI 2027 title and our AI timelines. Let me quickly clarify:
We’re not confident that:
1. AGI will happen in exactly 2027 (2027 is one of the most likely specific years though!)
2. It will take <1 yr to get from AGI to ASI
3. AGIs will definitely be misaligned
We’re confident that:
1. AGI and ASI will eventually be built and might be built soon
2. ASI will be wildly transformative
3. We’re not ready for AGI and should be taking this whole situation way more seriously
🧵 with more details
Excited to announce our MIT Press book “Neuroevolution: Harnessing Creativity in AI Agent Design” by Sebastian Risi (@risi1979), Yujin Tang (@yujin_tang), Risto Miikkulainen, and myself.
We explore decades of work on evolving intelligent agents and shows how neuroevolution can drive creativity in deep learning, RL, LLMs and AI Agents!
📖 Free open-access edition: https://t.co/1VraVue7Sk
In addition to our own works, this video features work by Jürgen Schmidhuber (@SchmidhuberAI), Seth Bling (@SethBling), Igor Karpov, Jacob Schrum, Yulu Gan (@yule_gan), Ken Stanley (@kenneth0stanley), Joel Lehman (@joelbot3000), Jeff Clune (@jeffclune), Nick Cheney (@CheneyLab), Richard Song (@XingyouSong), Chelsea Finn (@chelseabfinn), Julian Togelius (@togelius), Sam Earle (@Smearle_RH), Hod Lipson (@hodlipson), and Jean-Baptiste Mouret (@jb_mouret).
✨ New course materials: Interpretability of LLMs✨
This semester I'm teaching an active-learning grad course at @TelAvivUni on LLM interpretability, co-developed with my student @dhgottesman.
We're releasing the materials as we go, so they can serve as a resource for anyone curious about how LLMs work from the inside:
https://t.co/3L9ZP7T1eZ
What if next-token prediction wasn't a single forward pass, but a tiny optimization problem?
Introducing: nanoEBM a tiny transformer that learns to think harder by doing gradient descent on its own predictions.
You can start training on your Mac now - it comes < 400 lines
Tired to go back to the original papers again and again? Our monograph: a systematic and fundamental recipe you can rely on!
📘 We’re excited to release 《The Principles of Diffusion Models》— with @DrYangSong, @gimdong58085414, @mittu1204, and @StefanoErmon.
It traces the core ideas that shaped diffusion modeling and explains how today’s models work, why they work, and where they’re heading.
🧵You’ll find the link and a few highlights in the thread.
We’d love to hear your thoughts and join some discussions!
⚡ Stay tuned for our markdown version, where you can drop your comments!
New paper 📜: Tiny Recursion Model (TRM) is a recursive reasoning approach with a tiny 7M parameters neural network that obtains 45% on ARC-AGI-1 and 8% on ARC-AGI-2, beating most LLMs.
Blog: https://t.co/w5ZDsHDDPE
Code: https://t.co/7UgKuD9Yll
Paper: https://t.co/3m8ANhNMiw
Reinforcement Learning (RL) has long been the dominant method for fine-tuning, powering many state-of-the-art LLMs. Methods like PPO and GRPO explore in action space. But can we instead explore directly in parameter space? YES we can. We propose a scalable framework for full-parameter fine-tuning using Evolution Strategies (ES).
By skipping gradients and optimizing directly in parameter space, ES achieves more accurate, efficient, and stable fine-tuning.
Paper: https://t.co/Es44ZqfcJ6
Code: https://t.co/eduztHwrLS
much more convinced after getting my own results:
LoRA with rank=1 learns (and generalizes) as well as full-tuning while saving 43% vRAM usage! allows me to RL bigger models with limited resources😆
script: https://t.co/p6IIiBQA6c
(1/7) New preprint from the Rajan Lab! 🧠🤖 @RyanPaulBadman1 & @SimmonsEdler show–through cog sci, neuro & ethology-how an AI agent with fewer ‘neurons’ than an insect can forage, find safety & dodge predators in a virtual world. Here's what we did
Paper: https://t.co/DvRKjERrGl
Excited to introduce Dreamer 4, an agent that learns to solve complex control tasks entirely inside of its scalable world model! 🌎🤖
Dreamer 4 pushes the frontier of world model accuracy, speed, and learning complex tasks from offline datasets.
co-led with @wilson1yan
really good and thought provoking paper. somehow i was thinking, what if we could run this gan-style training for a long time? i think these are the first steps of training algorithms that would not stop running, something eternal and open-ended
https://t.co/8f1his4HlP
Title: Advice for a young investigator in the first and last days of the Anthropocene
Abstract: Within just a few years, it is likely that we will create AI systems that outperform the best humans on all intellectual tasks. This will have implications for your research and career! I will give practical advice, and concrete criteria to consider, when choosing research projects, and making professional decisions, in these last few years before AGI.
This is my current go-to academic talk. It's mostly targeted at early career scientists. It gets diverse and strong reactions. Let's try it here. Posting slides with speaker notes...
--
The title is a play on a very opinionated and pragmatic book by the nobel prize winner ramon y cajal, who is one of the founders of modern neuroscience.
To get you in the right mindset, on the right we have a plot of GDP vs time.
That is you, standing precariously on the top of that curve.
You are thinking to yourself -- I live in a pretty normal world.
Some things are going to change, but the future is going to look mostly like a linear extrapolation of the present.
And the plot should suggest that this may not be the right perspective on the future.
This plot by the way looks surprisingly similar even if you plot it on a log scale. We didn't stabilize on our current rate of growth until around 1950.
Since floating point addition isn't associative, you could use it as an activation function.
Especially with fp8, fp4... with fp4 I feel like you wouldn't need an activation function.