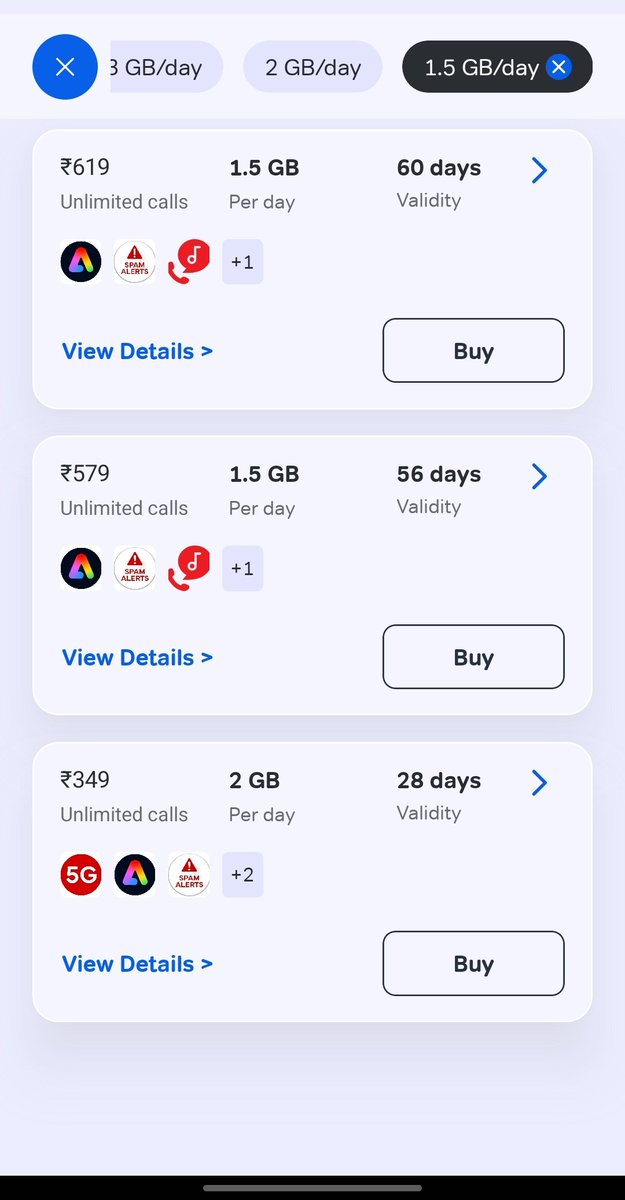
what the hell with the @IndiGo6E Both business and support are worse than expected. A delayed flight is understandable, but the lack of smart support is frustrating.
@IndiGo6E should be held accountable and accommodate those who suffering a 12-hour delay.
AI agents, real terminal UI, team orchestration, nested sessions, and Claude Code—all from your browser.
Run Agent Maestro locally, manage multiple AI teammates, and build without workflow chaos.
GitHub: https://t.co/q7V6jnJVag
bash scripts/start-web.sh
#AI#OpenSource#Agent
Portless killed :3000
Dev servers got stable names like myapp.localhost
Agents could use worktrees in parallel without stepping on each other
Now it's easier than ever in v0.11
Just run: portless
Zero config. Zero args. Zero code changes.
Introducing ml-intern, the agent that just automated the post-training team @huggingface
It's an open-source implementation of the real research loop that our ML researchers do every day. You give it a prompt, it researches papers, goes through citations, implements ideas in GPU sandboxes, iterates and builds deeply research-backed models for any use case. All built on the Hugging Face ecosystem.
It can pull off crazy things:
We made it train the best model for scientific reasoning. It went through citations from the official benchmark paper. Found OpenScience and NemoTron-CrossThink, added 7 difficulty-filtered dataset variants from ARC/SciQ/MMLU, and ran 12 SFT runs on Qwen3-1.7B. This pushed the score 10% → 32% on GPQA in under 10h. Claude Code's best: 22.99%.
In healthcare settings it inspected available datasets, concluded they were too low quality, and wrote a script to generate 1100 synthetic data points from scratch for emergencies, hedging, multilingual etc. Then upsampled 50x for training. Beat Codex on HealthBench by 60%.
For competitive mathematics, it wrote a full GRPO script, launched training with A100 GPUs on https://t.co/udm7xGpNzR, watched rewards claim and then collapse, and ran ablations until it succeeded. All fully backed by papers, autonomously.
How it works?
ml-intern makes full use of the HF ecosystem:
- finds papers on arxiv and https://t.co/brvCC7fLPa, reads them fully, walks citation graphs, pulls datasets referenced in methodology sections and on https://t.co/hrJuRkRyzi
- browses the Hub, reads recent docs, inspects datasets and reformats them before training so it doesn't waste GPU hours on bad data
- launches training jobs on HF Jobs if no local GPUs are available, monitors runs, reads its own eval outputs, diagnoses failures, retrains
ml-intern deeply embodies how researchers work and think. It knows how data should look like and what good models feel like.
Releasing it today as a CLI and a web app you can use from your phone/desktop.
CLI: https://t.co/l3K1PslZ1n
Web + mobile: https://t.co/orko5srL4H
And the best part? We also provisioned 1k$ GPU resources and Anthropic credits for the quickest among you to use.
Must-read research of the week
▪️ Dive into Claude Code: The design space of today’s and future AI agent systems
▪️ Lightning OPD: Efficient Post-Training for LRMs with Offline On-Policy Distillation
▪️ Self-Distillation Zero: Self-Revision Turns Binary Rewards into Dense Supervision
▪️ TIP: Token Importance in On-Policy Distillation
▪️ Toward Autonomous Long-Horizon Engineering for ML Research
▪️ Memory Transfer Learning: How Memories are Transferred Across Domains in Coding Agents
▪️ Agentic Aggregation for Parallel Scaling of Long-Horizon Agentic Tasks
▪️ Introspective Diffusion Language Models
▪️ Maximal Brain Damage Without Data Or Optimization: Disrupting Neural Networks Via Sign-Bit Flips
▪️ The Past Is Not Past: Memory-Enhanced Dynamic Reward Shaping
▪️ KnowRL
▪️ Rethinking On-Policy Distillation of LLMs
▪️ Continuous Adversarial Flow Models
Find all the links and the most important AI news of the week here: https://t.co/sIqDJ3Dp4p
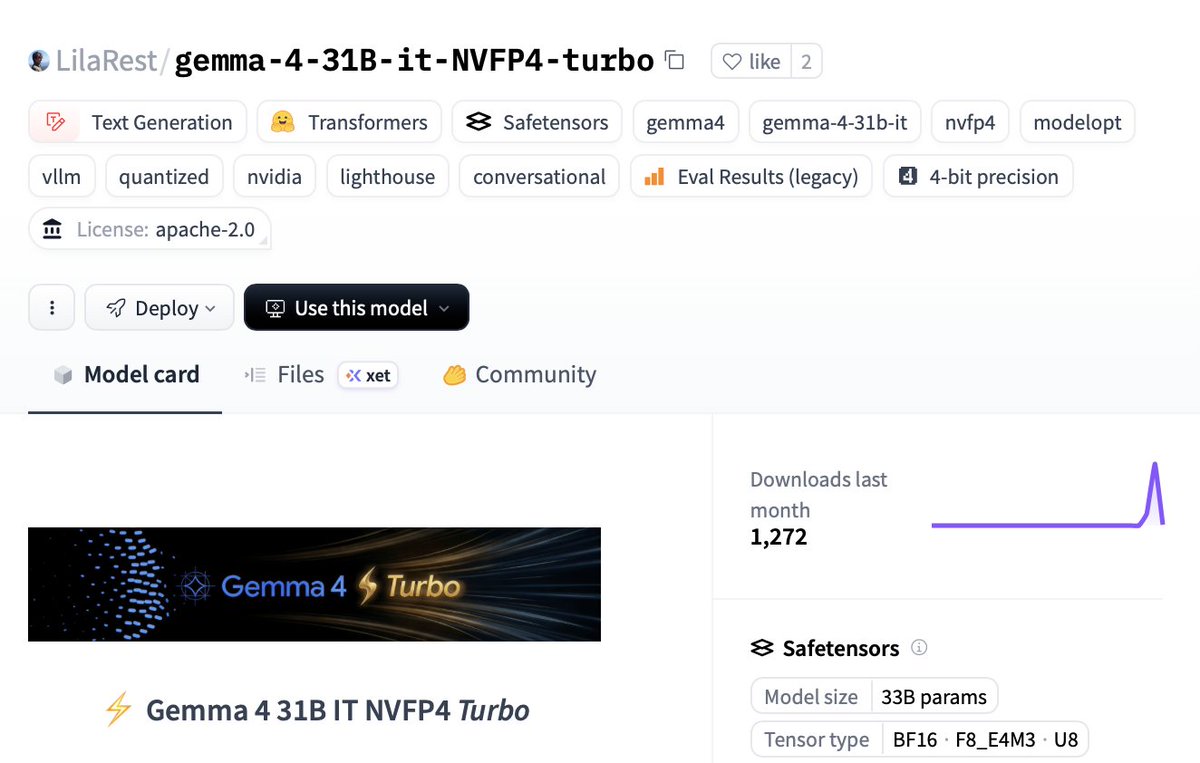
🚀 NEW GEMMA 4 31B TURBO DROPPED
Runs on a SINGLE RTX 5090:
⚡️18.5 GB VRAM only (68% smaller)
🧠51 tok/s single decode
💻1,244 tok/s batched
🤖15,359 tok/s prefill ← yes, fifteen thousand
🚨2.5× faster than base model with basically zero quality loss.
It hits Sonnet-4.5 level on hard classification tasks…
at 1/600th the cost.
Local models are shipping faster than we can test 👇🏻
🔥 HF: https://t.co/XUvVZBj9AX