MiniMax just released MiniMax-M3, their first multimodal model. It is the new open-weight SOTA on the Vals Index and the Vals Multimodal Index, and #6 overall.
NYT cited our Vibe Code Bench in its coverage of Opus 4.8, signal that real-world model evals are becoming part of how frontier labs are understood.
With Ant's S1 filing, would expect benchmarks like this to matter more over time for accountability + market reporting.
"It’s actually one of the existential risks for AI progress in general... What are you hillclimbing on? It is one of the foundational questions that needs to be answered"
Was great to talk through the 3.5 release with Logan and where model progress is headed
We are excited to share that @OfficialLoganK joined us on The Bench to discuss Google's new Gemini 3.5 Flash: why it's deliberately more persistent and capable than previous Flash models, how it hit #1 on our FinanceAgent Benchmark taking 82 steps where competitors stopped at 13, and what justifies the price increase. We also get into why AI benchmarks need a paradigm shift, the trade-off of building everything vs staying focused, the Pope, and why Omni might kill the Subway Surfers content era.
0:11:00 – Flash is being rebased for the agent era, not just a cheaper model anymore
0:14:03 – Persistence by design: 82 tool calls vs competitors' 13
0:17:52 – Why pricing went up and how Google thinks about value per token
0:22:55 – Coding performance: from 20th to 10th place in one generation
0:28:28 – Why benchmarks have historically been misleading and what the new era of evaluation looks like
0:29:28 Logan on why Google has the best researchers in the world
0:36:16 – The cost of being Google
0:39:07 – The Pope’s encyclical on AI and whether most people see frontier intelligence as a good thing
0:51:12 – Why Omni is the thing that recently clicked
Ant continuing to push the ceiling and find headroom on coding. I was blown away seeing such a significant jump on our Vibe Code Benchmark (71% -> 83%) only furthering their lead as the SOTA coding model.
Anthropic just dropped another powerhouse model, Opus 4.8 and it’s the new SOTA on the Vals Index (70.2%) and Vals Multimodal (70.7%). Full results below.
Pitch us a benchmark or eval technique. We'll fund you to build it.
We're opening applications for the Vals Fellowship. 3–6 months working on the hardest open problems in AI evaluation, with the resources to actually solve them.
What you get:
- Unlimited API credits + budget capacity for GPUs and human data
- Vals’ evaluation infrastructure
- $1,000–2,500 / week stipend
- A network of evals researchers across frontier labs and academia
Location: Both remote / in-person in SF applications will be considered
Yesterday we had the privilege of hosting @tkalil2050 and the top foundation model labs at our office for an exclusive first look at what we are shipping next.
Exciting things to come! DM us if you want to come to the next one.
Can AI do the job of a financial analyst?
We just released V2 of our Finance Agent Benchmark and tested the frontier models. The results are tighter than you'd expect.
Finance Agent Benchmark v2 is here.
Finance is one of the most lucrative applications of AI where much of the busy work could be automated. That’s why we rebuilt our Finance Agent Benchmark to push frontier models even further. We designed V2 to better reflect what financial analysts actually do: refined taxonomy reflecting real workflows, an improved harness with more tools, and jury-based evaluation.
The result: no model cracks 52%.
Would you trust a financial analyst who’s only correct half the time?
After reaching out, we were able to confirm with OpenAI that “tool_choice”: “none” injects an additional steering instruction into the model system prompt, in a way that tools: [] does not.
This instruction seemingly hurts the model’s ability to use the Terminus 2 harness effectively, which, despite not using native-tool-calling, is still agentic.
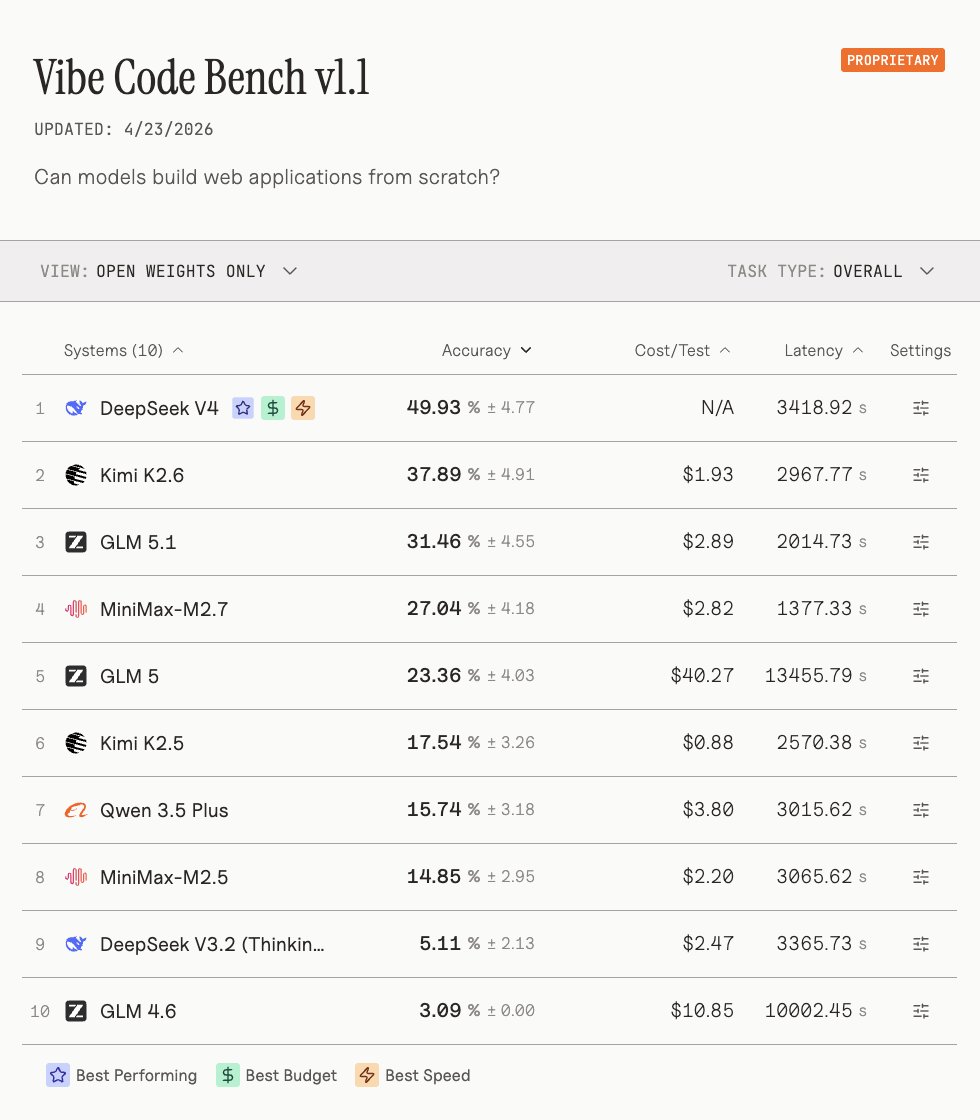
DeepSeek v4 is now the #1 open-weight model on our Vibe Code Benchmark, and it’s not close.
It leaves the #2 (Kimi K2.6) in the dust, and even beats out frontier closed source models like Gemini 3.1 Pro.