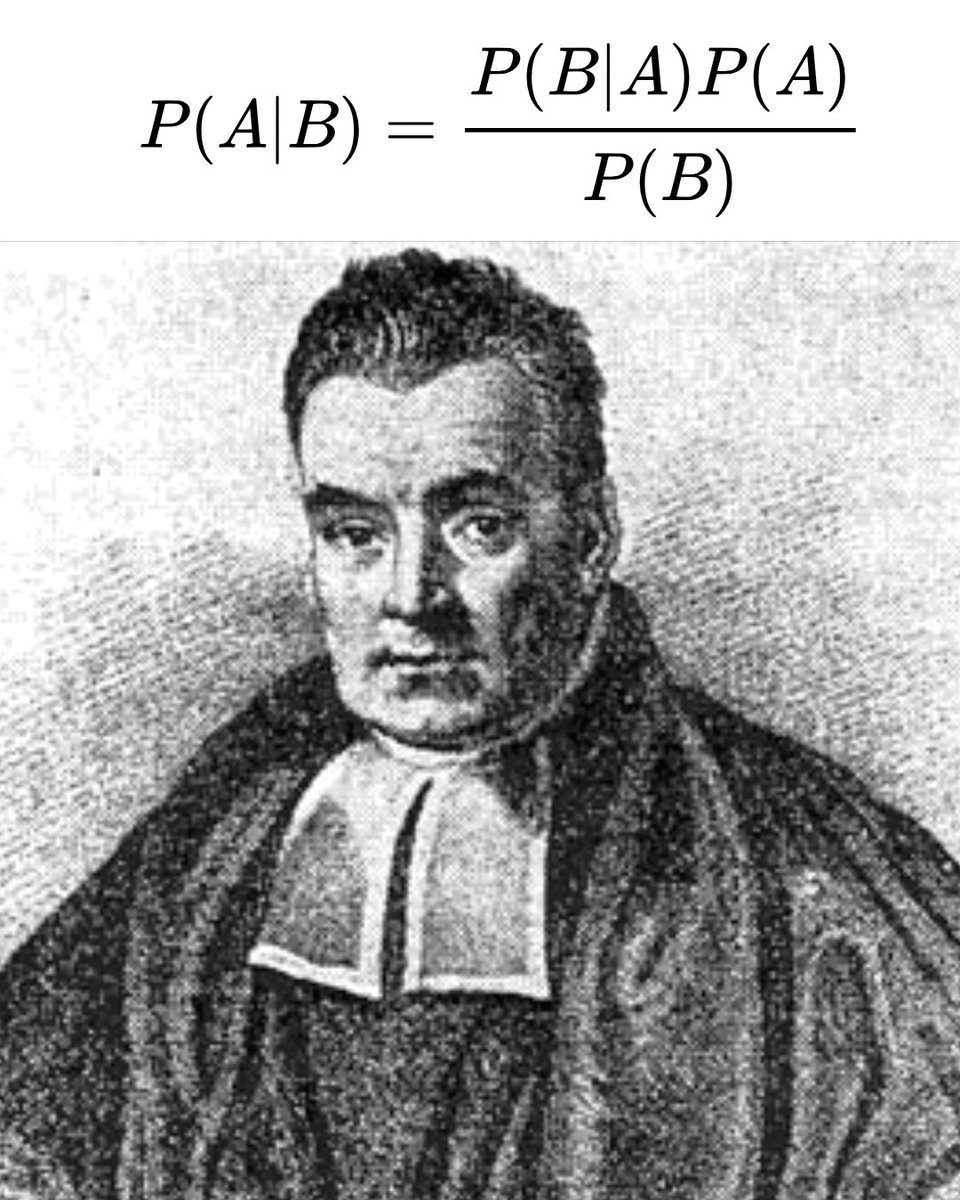Understanding probability functions can help us make sense of randomness and predict outcomes. Here's a quick overview of four key probability functions:
1️⃣ Probability Density Function (PDF)
The PDF tells us the probability of a continuous variable falling within a certain range. Think of it as the "shape" of the data, showing how values are distributed.
2️⃣ Cumulative Distribution Function (CDF)
The CDF represents the cumulative probability of a variable being less than or equal to a specific value. It provides a complete picture of the distribution by accumulating probabilities up to a point.
3️⃣ Quantile Function (Inverse CDF)
The Quantile Function helps us determine the value below which a certain percentage of observations fall. It’s useful for identifying thresholds and setting benchmarks in data analysis.
4️⃣ Random Variate Generation
This function is used to generate random numbers based on a specific probability distribution. It’s essential for simulations and modeling real-world scenarios where randomness plays a role.
Understanding these functions can empower you to analyze data sets more effectively, predict outcomes, and make informed decisions.
If you want to learn more about probability functions and other statistical methods, join my online course on Statistical Methods in R. This course dives into these topics and much more, building a strong foundation in statistics.
Check out this link for more details: https://t.co/7YQCRDKSPO
#datastructure #DataAnalytics #RStats #rstudioglobal
A “shift in perspectives” type book!
If you are running a serious mathematical training program & want to teach “how to think like a mathematician”, then guide your students to understand mathematical arguments of some of the best human minds involved in this creative pursuit!
Correlación no es causalidad
Estoy llegando a pensar que por más que intentemos educar sobre la lectura adecuada de un indicador, estará muy complejo.
Pero les traigo dos imágenes para que siempre evalúen como es correcto 👇🏼
¿Qué es una base de datos y por qué un LLM no lo es?
Una base de datos almacena información estructurada (piensa en filas y columnas tipo Excel, aunque puede guardar otros formatos).
Lo importante no es solo que guarda datos.
Lo importante es cómo responde.
Cuando haces una consulta con SQL:
•Recuperas contenido que ya está en la base.
•La respuesta es determinista: misma consulta → mismo resultado.
No hay creatividad. No hay interpretación. No hay variación.
Un LLM es otra cosa.
Un LLM no “recupera registros”.
Genera una secuencia de tokens basada en probabilidades aprendidas.
Por eso:
•No devuelve necesariamente algo que “esté dentro” tal cual.
•No es determinista (incluso con el mismo prompt puede variar).
•No está optimizado para exactitud transaccional.
•No es un sistema de consulta estructurada.
Si a una base de datos le preguntas cuánto ha transaccionado un cliente, obtienes el número exacto almacenado.
Si a un LLM le preguntas cuánto ha transaccionado un cliente, lo único que puede hacer es estimar o inventar en función del contexto que le diste.
Confundir ambos sistemas es no entender la diferencia entre recuperar información y generarla.
Y esa diferencia no es menor.
Deep Learning with PyTorch step by step
Total 3 volumes:
- Vol.1 (Fundamentals)
- Vol.2 (Computer Vision)
- Vol.3 (Sequences and NLP)
Official Repo: https://t.co/AdxIJjJc4t
⚠️ The Greatest Lie Ever Told: SQL Is Hard
No, SQL is easy. Now, before you come at me, yes, SQL syntax is easy. You can learn SELECT, FROM, WHERE, GROUP BY, and ORDER BY in a weekend. You can write:
SELECT *
FROM sales
WHERE total_price > 100;
And boom, it works. Yes, it is not that hard. Writing simple SQL syntax that does the job? Easy.
💨 Here is what nobody tells you: The SQL is not the hard part. The business is. And that changes everything.
What’s hard is the problem you’re supposed to solve with SQL.
Here’s what real life sounds like:
▶️ Why did customer churn increase in Q3?
▶️ Which product category is driving the decline in margin?
▶️ How many active users converted within 30 days of signup, excluding refunded orders and internal test accounts?
▶️ Which car types had the highest percentage of flagged claims relative to total claims, and what is the total claim amount for those segments?
Now we’re not talking about syntax anymore.
We’re talking about:
👉 Business logic
👉 Ambiguous definitions
👉 Edge cases
👉 Data quality issues
👉 Changing requirements
That’s where SQL becomes difficult.
Not the syntax, but because of the thinking.
💡 The Real Skill: Translating Business Questions
The SQL syntax is easy. The hardest part of SQL is translation. You’re constantly translating business language to data logic.
👑 How to Properly Learn SQL
This is where most learners get it wrong. They practice syntax. They memorize functions and test themselves on isolated exercises. That is cool and all.
But that’s not how you learn SQL deeply.
🔑 You learn SQL in context.
🔑 You learn it by solving problems that have a purpose.
🔑 You learn it by building something.
For example:
👉 Creating a database that will host questions for an app
👉 Designing tables for an insurance company
👉 Analyzing real-world sales data
👉 Building dashboards from raw transactional data
👉 Creating reporting logic for churn or claims
When you build something real, suddenly you're not asking, "How do I use ROW_NUMBER?" You're asking, "How do I identify the most recent policy per customer while excluding canceled contracts and handling missing effective dates?"
That's real learning. That’s growth.
If SQL feels easy to you, it's because the syntax is easy, and you probably haven’t been asked hard questions yet. And that’s okay. But don’t confuse syntactic comfort with analytical depth.
👑 SQL is easy. Solving real problems with SQL?
That’s where professionals are built.
Solve real problems with SQL 👇
Link: https://t.co/OVaNhH3eeq
Bayes’ theorem is probably the single most important thing any rational person can learn.
So many of our debates and disagreements that we shout about are because we don’t understand Bayes’ theorem or how human rationality often works.
Bayes’ theorem is named after the 18th-century Thomas Bayes, and essentially it’s a formula that asks: when you are presented with all of the evidence for something, how much should you believe it?
Bayes’ theorem teaches us that our beliefs are not fixed; they are probabilities. Our beliefs change as we weigh new evidence against our assumptions, or our priors. In other words, we all carry certain ideas about how the world works, and new evidence can challenge them.
For example, somebody might believe that smoking is safe, that stress causes mouth ulcers, or that human activity is unrelated to climate change. These are their priors, their starting points. They can be formed by our culture, our biases, or even incomplete information.
Now imagine a new study comes along that challenges one of your priors. A single study might not carry enough weight to overturn your existing beliefs. But as studies accumulate, eventually the scales may tip. At some point, your prior will become less and less plausible.
Bayes’ theorem argues that being rational is not about black and white. It’s not even about true or false. It’s about what is most reasonable based on the best available evidence. But for this to work, we need to be presented with as much high-quality data as possible. Without evidence—without belief-forming data—we are left only with our priors and biases. And those aren’t all that rational.
Calculus: Early Transcendentals
by David Guichard, Lyryx Learning Team, Jim Bailey, Mark Blenkinsop, Michael Cavers, Gregory Hartman, and Joseph Ling
PDF freely available at: https://t.co/EM7I6Tder3
El teorema de Bayes es probablemente la cosa más importante que cualquier persona racional puede aprender.
Muchos de nuestros debates y desacuerdos sobre los que gritamos se deben a que no entendemos el teorema de Bayes o cómo funciona a menudo la racionalidad humana.
El teorema de Bayes recibe su nombre del monje Thomas Bayes, del siglo XVIII, y esencialmente es una fórmula que pregunta: cuando se te presenta toda la evidencia de algo, ¿cuánto debes creerlo?
El teorema de Bayes nos enseña que nuestras creencias no son fijas; son probabilidades. Nuestras creencias cambian a medida que sopesamos nueva evidencia con nuestras suposiciones o premisas previas. En otras palabras, todos tenemos ciertas ideas sobre cómo funciona el mundo, y la nueva evidencia puede cuestionarlas.
Por ejemplo, alguien podría creer que fumar es seguro, que el estrés causa úlceras orales o que la actividad humana no está relacionada con el cambio climático. Estas son sus premisas previas, sus puntos de partida. Pueden estar formadas por nuestra cultura, nuestros prejuicios o incluso por información incompleta.
Ahora imagina que surge un nuevo estudio que cuestiona una de tus hipótesis previas. Un solo estudio podría no tener la suficiente fuerza para refutar tus creencias existentes. Pero a medida que se acumulan estudios, la balanza puede inclinarse. En algún momento, tu hipótesis previa se volverá cada vez menos plausible.
El teorema de Bayes argumenta que ser racional no se trata de blanco o negro. Ni siquiera se trata de verdadero o falso. Se trata de lo más razonable según la mejor evidencia disponible. Pero para que esto funcione, necesitamos que se nos presenten la mayor cantidad posible de datos de alta calidad. Sin evidencia —sin datos que formen creencias—, solo nos quedan nuestras presunciones y sesgos. Y estos no son tan racionales.
🚨 Acaban de filtrar el prompt que hace que ChatGPT escriba como un humano.
Olvídate de textos robóticos y empieza a sonar como una persona de verdad.
Aquí tienes el prompt completo 👇