Vmax is building an open-ended learning system that generates and optimizes itself on tasks that it creates, avoiding human bias that may corrupt optimal learning curricula.
In PopuLoRA, we instantiate this as co-evolving populations of LLMs performing asymmetric self-play.
Think OpenAI and Anthropic own the AI game?
Open-source models already handle 50%+ of real production requests!
New pod episode with our own Erfan & @shriyashku from @withmartian on the DeepSeek moment, vendor lock-in risk, and the fine-tuning cheat code.
It's pretty wild to think that a year ago CLI-first code tools didn't really exist, and now here we are measuring the entire E2E effectiveness of LLMs in software development
The software factory is already here.
We're seeing bots write code, bots review it, and humans reduced to dispatching the next tool in the chain.
Using 500k+ PRs from Code Review Bench, we looked at one question: can the human leave the loop yet?
I've been so excited to see Mech Interp techniques actually generalize to improving real-world applications, and it feels like we're finally at that point!
We’re open-sourcing a new tool to control how LLMs behave: k-steering. In just 10 lines of code, you can control multiple aspects of LLM behavior at the same time without any fine-tuning or prompt engineering.
Here's how 👇
Traditional Precision-Recall curves tell you how your code review tool performs on static benchmarks.
They don't tell you how it performs against a Hawk.
Introducing Fight Index (FI).
Personally, I love the shift in the industry of optimizing for two separate workflows - fast and iterative, vs slow and offline.
And I'm always a sucker for seeing data back up intuition 😅
We've been tracking AI code review tools across OSS, and a new category is emerging. We're calling it "Deep Review":
→ Standard AI review: PR-level, fast, human in the loop
→ Deep Review: repo-wide context, runs autonomously in the background
🧵👇
If this policy is not revoked, I won’t be reviewing/ACing for #NeurIPS
Science requires open exchange of ideas!
When participation gets shaped by geopolitics, it ends up reflecting power structures, not merit--narrows what science can be and powerful nations get full control!
I've been playing around with eval-ing AI code review tools at work. We track 22 different ones. @greptile V4 had the single biggest improvement I've ever measured.
Recall increased 47% from 38.7 → 56.9%
Our code review tracker caught the release of Claude Code Review before @AnthropicAI announced it.
Greptile v4 hit #1 on CRB. The tracker caught it before their announcement.
The data is predicting something new from @Devin Review in the near future.
Here's how. 🧵
Coding tools are getting way better, but also way more convincing to humans (or me at least). We definitely need to continue building robust evals for code review so we know we are keeping the "LGTM effect" in check
Verification is easier than Generation - the same is true for Code, and I am really excited to see the pipeline of: Code Review getting more robust evals → better code review tools → better coding tools
A new ARES tutorial from @Narmeen29013644:
Getting started in long-horizon interp.
When do agents fail to accurately model their environment? How de we fix them? And how can you run these experiments on your own machine?
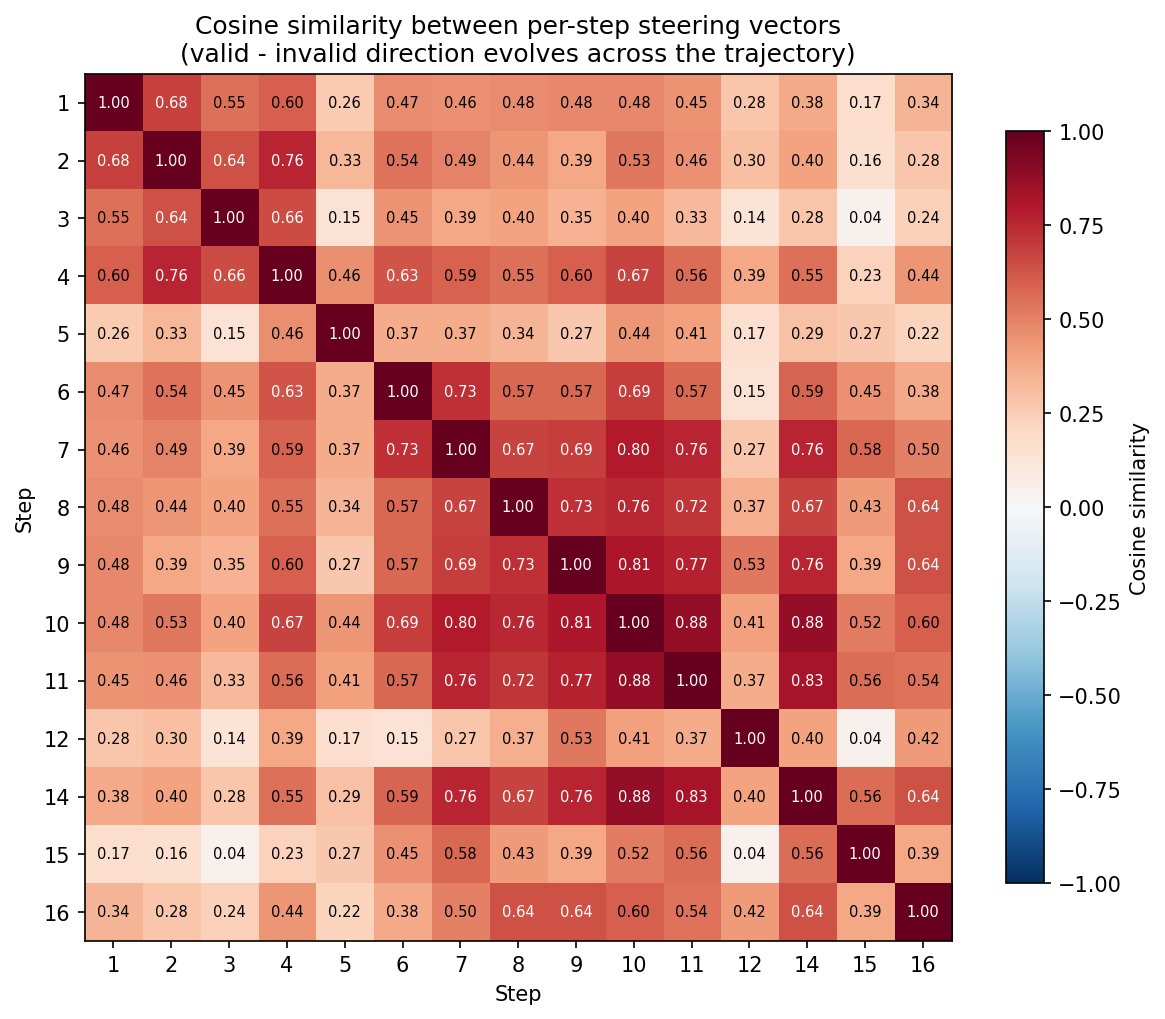
This is one of the biggest takeaways for me - model internals change over steps after interacting with the environment! I love this other figure @Narmeen29013644 made that shows this too - a matrix of cosine similarity between optimal steering vectors at each step:
But you can't just compute one steering vector and reuse it for the whole episode. The representation of "valid vs. invalid" drifts as the conversation goes on;per-step vectors outperform a single static one.
PCA on the vectors at different time steps shows they point in genuinely different directions.
ARES 🤝 Mech Interp
We’re excited that you can now easily dig into model internals across long-horizon tasks with ARES! We’ve built some nice integrations with TransformerLens, with even better support for hooks coming soon!
LLM agents ignore their own environment — skipping outputs, misreading tools, repeating failures.
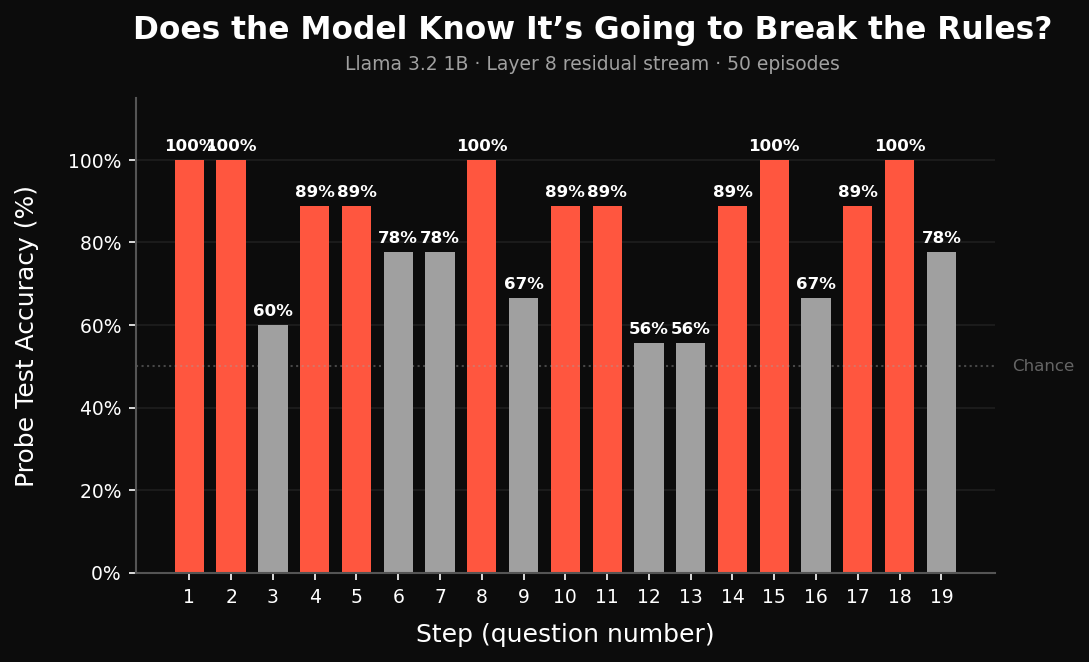
Turns out the model knows when it’s wrong.
87% probe accuracy from activations.
How we found it, fixed it, and how to try it with ARES + TransformerLens 🧵